《python爬虫》专题
-
十一、Python网络爬虫进阶实战(下)
-
十分钟掌握最强大的 python 爬虫
安装方法 执行 yum install libffi-devel yum install openssl-devel pip install scrapy scrapy的代码会安装在 /usr/local/lib/python2.7/site-packages/scrapy 中文文档在 http://scrapy-chs.readthedocs.io/zh_CN/latest/ 使用样例 创建
-
爬虫项
爬虫项是什么呢?比如采集文章列表、文章详情页,他们都是不同的采集项。 定义示例: 继承Yurun\Crawler\Module\Crawler\Contract\BaseCrawlerItem类。 <?php namespace Yurun\CrawlerApp\Module\YurunBlog\Article; use Imi\Bean\Annotation\Bean; use Yurun\C
-
 Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例
Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例本文向大家介绍Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例,包括了Python实现爬取百度贴吧帖子所有楼层图片的爬虫示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现爬取百度贴吧帖子所有楼层图片的爬虫。分享给大家供大家参考,具体如下: 下载百度贴吧帖子图片,好好看 python2.7版本: PS:这里再为大家提供2款非常方便的正则表达式工具供大家参考使用: Ja
-
python爬虫实现爬取同一个网站的多页数据的实例讲解
本文向大家介绍python爬虫实现爬取同一个网站的多页数据的实例讲解,包括了python爬虫实现爬取同一个网站的多页数据的实例讲解的使用技巧和注意事项,需要的朋友参考一下 对于一个网站的图片、文字音视频等,如果我们一个个的下载,不仅浪费时间,而且很容易出错。Python爬虫帮助我们获取需要的数据,这个数据是可以快速批量的获取。本文小编带领大家通过python爬虫获取获取总页数并更改url的方法,实
-
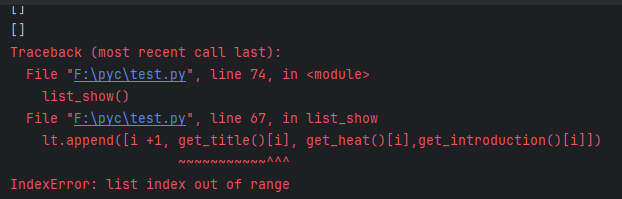 爬虫python ,为什么偶尔出现list out of range ,爬不出数据 的情况?
爬虫python ,为什么偶尔出现list out of range ,爬不出数据 的情况?python爬虫用 beautifulsoup 解析,有时候会出现 list out of range , 但是代码不变情况下,有时候也能运行。输出的列表均为空 输出statu_code 是 200, 也输出了soup ,但是就是列表返回不出数据
-
Python爬取读者并制作成PDF
本文向大家介绍Python爬取读者并制作成PDF,包括了Python爬取读者并制作成PDF的使用技巧和注意事项,需要的朋友参考一下 学了下beautifulsoup后,做个个网络爬虫,爬取读者杂志并用reportlab制作成pdf.. crawler.py getpdf.py 以上就是本文的全部内容了,希望大家能够喜欢。
-
python爬取NUS-WIDE数据库图片
本文向大家介绍python爬取NUS-WIDE数据库图片,包括了python爬取NUS-WIDE数据库图片的使用技巧和注意事项,需要的朋友参考一下 实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需要一个小爬虫程序来爬取这些图片。在图片的下载过程中建
-
 用Python爬取某宝商品数据
用Python爬取某宝商品数据数据采集是数据可视化分析的第一步,也是最基础的一步,数据采集的数量和质量越高,后面分析的准确的也就越高,我们来看一下淘宝网的数据该如何爬取。 淘宝网站是一个动态加载的网站,我们之前可以采用解析接口或者用Selenium自动化测试工具来爬取数据,但是现在淘宝对接口进行了加密,使我们很难分析出来其中的规律,同时淘宝也对Selenium进行了反爬限制,所以我们要换种思路来进行数据获取。
-
python爬虫(入门教程、视频教程) 原创
本文向大家介绍python爬虫(入门教程、视频教程) 原创,包括了python爬虫(入门教程、视频教程) 原创的使用技巧和注意事项,需要的朋友参考一下 python的版本经过了python2.x和python3.x等版本,无论哪种版本,关于python爬虫相关的知识是融会贯通的,呐喊教程关于爬虫这个方便整理过很多有价值的教程,小编通过本文章给大家做一个关于python爬虫相关知识的总结,以下就是全
-
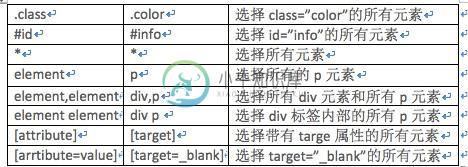 Python爬虫PyQuery库基本用法入门教程
Python爬虫PyQuery库基本用法入门教程本文向大家介绍Python爬虫PyQuery库基本用法入门教程,包括了Python爬虫PyQuery库基本用法入门教程的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python爬虫PyQuery库基本用法。分享给大家供大家参考,具体如下: PyQuery库也是一个非常强大又灵活的网页解析库,如果你有前端开发经验的,都应该接触过jQuery,那么PyQuery就是你非常绝佳的选择,PyQu
-
Python爬虫使用浏览器cookies:browsercookie过程解析
本文向大家介绍Python爬虫使用浏览器cookies:browsercookie过程解析,包括了Python爬虫使用浏览器cookies:browsercookie过程解析的使用技巧和注意事项,需要的朋友参考一下 很多用Python的人可能都写过网络爬虫,自动化获取网络数据确实是一件令人愉悦的事情,而Python很好的帮助我们达到这种愉悦。然而,爬虫经常要碰到各种登录、验证的阻挠,让人灰心丧气(
-
Python常用爬虫代码总结方便查询
本文向大家介绍Python常用爬虫代码总结方便查询,包括了Python常用爬虫代码总结方便查询的使用技巧和注意事项,需要的朋友参考一下 beautifulsoup解析页面 unicode编码转中文 url encode的解码与解码 html转义字符的解码 base64的编码与解码 过滤emoji表情 完全过滤script和style标签 过滤html的标签,但保留标签里的内容 时间操作 数据库操作
-
Python爬虫入门有哪些基础知识点
本文向大家介绍Python爬虫入门有哪些基础知识点,包括了Python爬虫入门有哪些基础知识点的使用技巧和注意事项,需要的朋友参考一下 1、什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向
-
使用PyV8在Python爬虫中执行js代码
本文向大家介绍使用PyV8在Python爬虫中执行js代码,包括了使用PyV8在Python爬虫中执行js代码的使用技巧和注意事项,需要的朋友参考一下 前言 可能很多人会觉得这是一个奇葩的需求,爬虫去好好的爬数据不就行了,解析js干嘛?吃饱了撑的? 搜索一下互联网上关于这个问题还真不少,但是大多数童鞋是因为自己的js基础太烂,要么是HTML基础烂,要么ajax基础烂,反正各方面都很烂。基础这么渣不