《python爬虫》专题
-
 Python制作爬虫抓取美女图
Python制作爬虫抓取美女图本文向大家介绍Python制作爬虫抓取美女图,包括了Python制作爬虫抓取美女图的使用技巧和注意事项,需要的朋友参考一下 作为一个新世纪有思想有文化有道德时刻准备着的屌丝男青年,在现在这样一个社会中,心疼我大慢播抵制大百度的前提下,没事儿上上网逛逛YY看看斗鱼翻翻美女图片那是必不可少的,可是美图虽多翻页费劲!今天我们就搞个爬虫把美图都给扒下来!本次实例有2个:煎蛋上的妹子图,某网站的rosi
-
 Python制作豆瓣图片的爬虫
Python制作豆瓣图片的爬虫本文向大家介绍Python制作豆瓣图片的爬虫,包括了Python制作豆瓣图片的爬虫的使用技巧和注意事项,需要的朋友参考一下 前段时间自学了一段时间的Python,想着浓一点项目来练练手。看着大佬们一说就是爬了100W+的数据就非常的羡慕,不过对于我这种初学者来说,也就爬一爬图片。 我相信很多人的第一个爬虫程序都是爬去贴吧的图片,嗯,我平时不玩贴吧,加上我觉得豆瓣挺良心的,我就爬了豆瓣首页上
-
Python制作简单的网页爬虫
本文向大家介绍Python制作简单的网页爬虫,包括了Python制作简单的网页爬虫的使用技巧和注意事项,需要的朋友参考一下 1.准备工作: 工欲善其事必先利其器,因此我们有必要在进行Coding前先配置一个适合我们自己的开发环境,我搭建的开发环境是: 操作系统:Ubuntu 14.04 LTS Python版本:2.7.6 代码编辑器:Sublime Text 3.0 这次的网络爬虫需求背景我打算
-
Python爬虫之UserAgent的使用实例
本文向大家介绍Python爬虫之UserAgent的使用实例,包括了Python爬虫之UserAgent的使用实例的使用技巧和注意事项,需要的朋友参考一下 问题: 在Python爬虫的过程中经常要模拟UserAgent, 因此自动生成UserAgent十分有用, 最近看到一个Python库(fake-useragent),可以随机生成各种UserAgent, 在这里记录一下, 留给自己爬虫使用。
-
python爬虫之urllib3的使用示例
本文向大家介绍python爬虫之urllib3的使用示例,包括了python爬虫之urllib3的使用示例的使用技巧和注意事项,需要的朋友参考一下 Urllib3是一个功能强大,条理清晰,用于HTTP客户端的Python库。许多Python的原生系统已经开始使用urllib3。Urllib3提供了很多python标准库urllib里所没有的重要特性: 线程安全 连接池 客户端SSL/TLS验证 文
-
详解Python爬虫的基本写法
本文向大家介绍详解Python爬虫的基本写法,包括了详解Python爬虫的基本写法的使用技巧和注意事项,需要的朋友参考一下 什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那
-
简单的Python抓taobao图片爬虫
本文向大家介绍简单的Python抓taobao图片爬虫,包括了简单的Python抓taobao图片爬虫的使用技巧和注意事项,需要的朋友参考一下 写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品。 从网页http://mm.taobao.com/json/request_top_list.htm?type=0&page=中提取taobao模特的照片。
-
python爬虫常用的模块分析
本文向大家介绍python爬虫常用的模块分析,包括了python爬虫常用的模块分析的使用技巧和注意事项,需要的朋友参考一下 本文对Python爬虫常用的模块做了较为深入的分析,并以实例加以深入说明。分享给大家供大家参考之用。具体分析如下: creepy模块 某台湾大神开发的,功能简单,能够自动抓取某个网站的所有内容,当然你也可以设定哪些url需要抓。 地址:https://pypi.python.
-
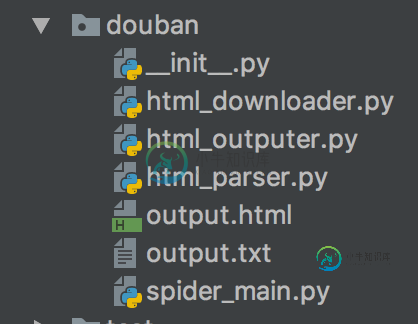 Python爬豆瓣电影实例
Python爬豆瓣电影实例本文向大家介绍Python爬豆瓣电影实例,包括了Python爬豆瓣电影实例的使用技巧和注意事项,需要的朋友参考一下 文件结构 html_downloader.py - 下载网页html内容 html_outputer.py - 输出结果到文件中 html_parser.py: 解析器:解析html的dom树 spider_main.py - 主函数 综述 其实就是使用了urllib2和Beauti
-
15 爬虫与反爬虫
有的时候,当我们的爬虫程序完成了,并且在本地测试也没有问题,爬取了一段时间之后突然就发现报错无法抓取页面内容了。这个时候,我们很有可能是遇到了网站的反爬虫拦截。 我们知道,网站一方面想要爬虫爬取网站,比如让搜索引擎爬虫去爬取网站的内容,来增加网站的搜索排名。另一方面,由于网站的服务器资源有限,过多的非真实的用户对网站的大量访问,会增加运营成本和服务器负担。 因此,有些网站会设置一些反爬虫的措施。我
-
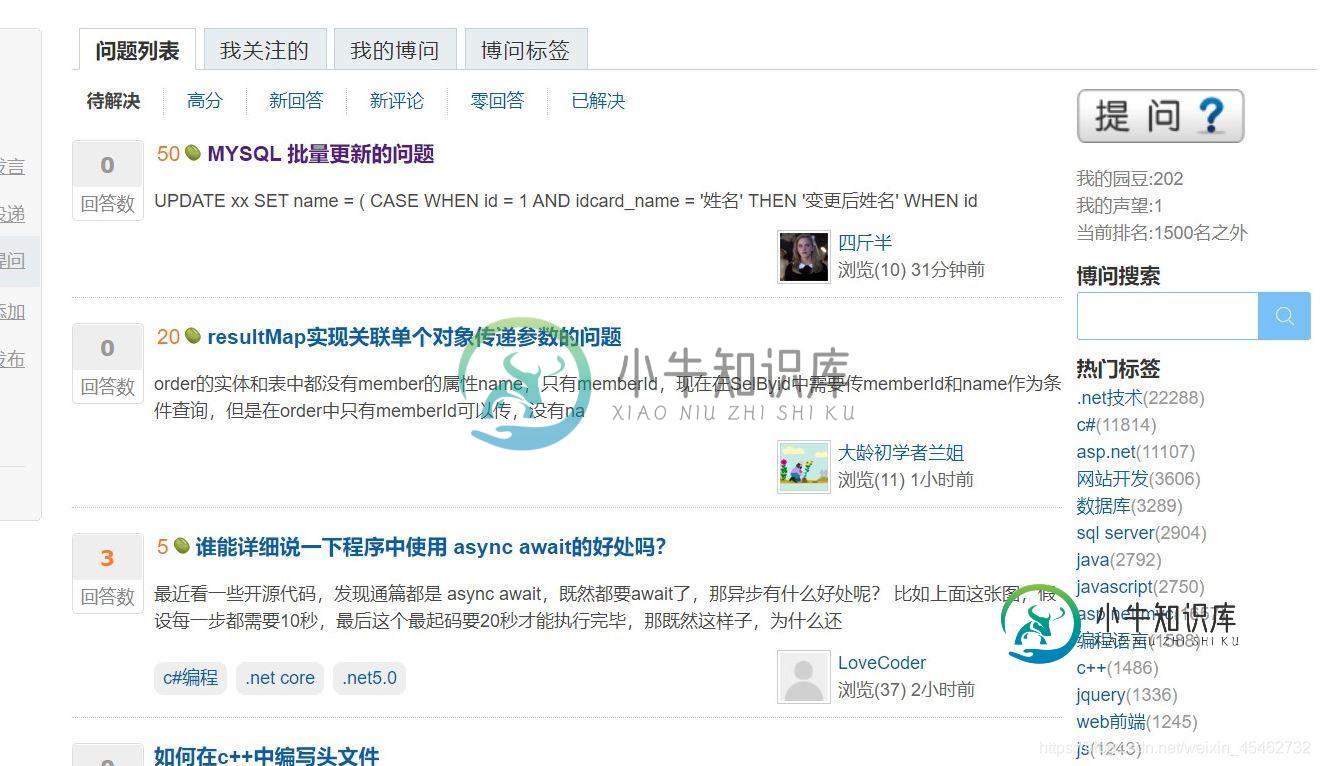 详解Python爬虫爬取博客园问题列表所有的问题
详解Python爬虫爬取博客园问题列表所有的问题本文向大家介绍详解Python爬虫爬取博客园问题列表所有的问题,包括了详解Python爬虫爬取博客园问题列表所有的问题的使用技巧和注意事项,需要的朋友参考一下 一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下。 我们的需求是将博客园问题列表中的所有问题的题目爬取下来。 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找
-
爬虫
这一章将会介绍使用一些新的模块(optparse,spider)去完成一个爬虫的web应用。爬虫其实就是一个枚举出一个网站上面的所有链接,以帮助你创建一个网站地图的web应用程序。而使用Python则可以很快的帮助你开发出一个爬虫脚本. 你可以创建一个爬虫脚本通过href标签对请求的响应内容进行解析,并且可以在解析的同时创建一个新的请求,你还可以直接调用spider模块来实现,这样就不需要自己去写
-
 python爬虫神器Pyppeteer入门及使用
python爬虫神器Pyppeteer入门及使用本文向大家介绍python爬虫神器Pyppeteer入门及使用,包括了python爬虫神器Pyppeteer入门及使用的使用技巧和注意事项,需要的朋友参考一下 前言 提起selenium想必大家都不陌生,作为一款知名的Web自动化测试框架,selenium支持多款主流浏览器,提供了功能丰富的API接口,经常被我们用作爬虫工具来使用。但是selenium的缺点也很明显,比如速度太慢、对版本配置要求严
-
 Python 制作糗事百科爬虫实例
Python 制作糗事百科爬虫实例本文向大家介绍Python 制作糗事百科爬虫实例,包括了Python 制作糗事百科爬虫实例的使用技巧和注意事项,需要的朋友参考一下 早上起来闲来无事做,莫名其妙的就弹出了糗事百科的段子,转念一想既然你送上门来,那我就写个爬虫到你网站上爬一爬吧,一来当做练练手,二来也算找点乐子。 其实这两天也正在接触数据库的内容,可以将爬取下来的数据保存在数据库中,以待以后的利用。好了,废话不多说了,先来看看程序爬
-
 Python爬虫学习之翻译小程序
Python爬虫学习之翻译小程序本文向大家介绍Python爬虫学习之翻译小程序,包括了Python爬虫学习之翻译小程序的使用技巧和注意事项,需要的朋友参考一下 本次博客分享的内容为基于有道在线翻译实现一个实时翻译小程序,本次任务是参考小甲鱼的书《零基础入门学习Python》完成的,书中代码对于当前的有道词典并不适用,使用后无法实现翻译功能,在网上进行学习之后解决了这一问题。 2、前置工作 1)由于有道在线翻译是“反爬虫”的,所以