《python爬虫》专题
-
 python爬虫 - python3 爬虫,请问这是什么编码?
python爬虫 - python3 爬虫,请问这是什么编码?原始content: decode('utf-8')报错: UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe8 in position 1: invalid continuation byte decode('utf-8', 'ignore'): decode('gbk', 'ignore'): decode('utf-16', 'ig
-
 Python使用爬虫猜密码
Python使用爬虫猜密码本文向大家介绍Python使用爬虫猜密码,包括了Python使用爬虫猜密码的使用技巧和注意事项,需要的朋友参考一下 我们可以通过python 来实现这样一个简单的爬虫猜密码功能。下面就看看如何使用python来实现这样一个功能。 这里我们知道用户的昵称为:heibanke 密码是30以内的一个数字,要使用requests库循环提交来猜密码 主要需要用到的库是requests库 安装requests
-
第一个Python爬虫程序
主要内容:获取网页html信息,常用方法本节编写一个最简单的爬虫程序,作为学习 Python 爬虫前的开胃小菜。 下面使用 Python 内置的 urllib 库获取网页的 html 信息。注意,urllib 库属于 Python 的标准库模块,无须单独安装,它是 Python 爬虫的常用模块。 获取网页html信息 1) 获取响应对象 向百度( http://www.baidu.com/)发起请求,获取百度首页的 HTML 信息,代码
-
python爬虫的工作原理
本文向大家介绍python爬虫的工作原理,包括了python爬虫的工作原理的使用技巧和注意事项,需要的朋友参考一下 1.爬虫的工作原理 网络爬虫,即Web Spider,是一个很形象的名字。把互联网比喻成一个蜘蛛网,那么Spider就是在网上爬来爬去的蜘蛛。网络蜘蛛是通过网页的链接地址来寻找网页的。从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这些链接地址
-
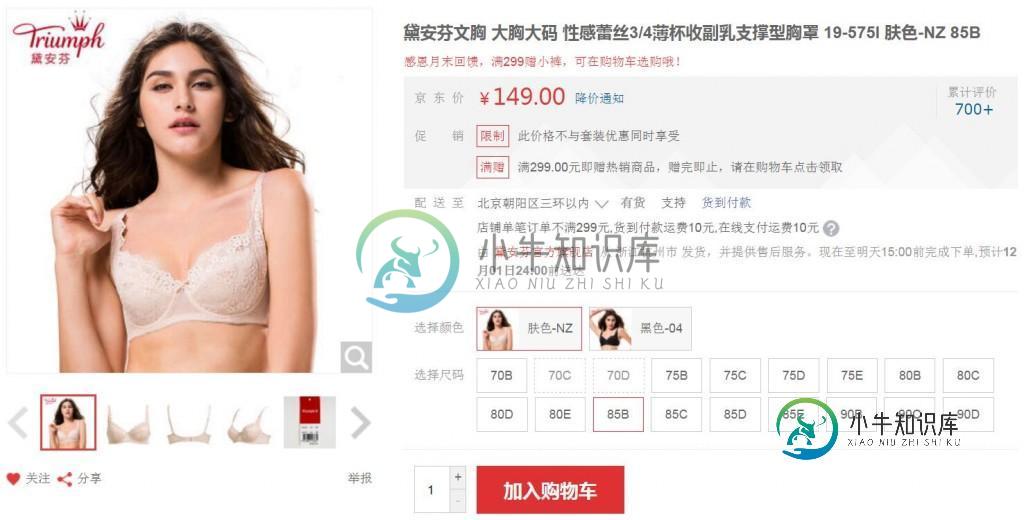 python制作爬虫爬取京东商品评论教程
python制作爬虫爬取京东商品评论教程本文向大家介绍python制作爬虫爬取京东商品评论教程,包括了python制作爬虫爬取京东商品评论教程的使用技巧和注意事项,需要的朋友参考一下 本篇文章是python爬虫系列的第三篇,介绍如何抓取京东商城商品评论信息,并对这些评论信息进行分析和可视化。下面是要抓取的商品信息,一款女士文胸。这个商品共有红色,黑色和肤色三种颜色, 70B到90D共18个尺寸,以及超过700条的购买评论。 京东商品评论
-
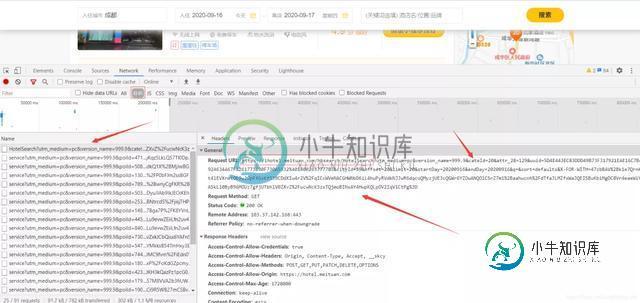 如何基于Python爬虫爬取美团酒店信息
如何基于Python爬虫爬取美团酒店信息本文向大家介绍如何基于Python爬虫爬取美团酒店信息,包括了如何基于Python爬虫爬取美团酒店信息的使用技巧和注意事项,需要的朋友参考一下 一、分析网页 网站的页面是 JavaScript 渲染而成的,我们所看到的内容都是网页加载后又执行了JavaScript代码之后才呈现出来的,因此这些数据并不存在于原始 HTML 代码中,而 requests 仅仅抓取的是原始 HTML 代码。抓取这种类型
-
 python爬虫之爬取百度音乐的实现方法
python爬虫之爬取百度音乐的实现方法本文向大家介绍python爬虫之爬取百度音乐的实现方法,包括了python爬虫之爬取百度音乐的实现方法的使用技巧和注意事项,需要的朋友参考一下 在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法。对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同。在上次
-
 python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)本文向大家介绍python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门),包括了python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)的使用技巧和注意事项,需要的朋友参考一下 【python爬虫基础入门】系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1
-
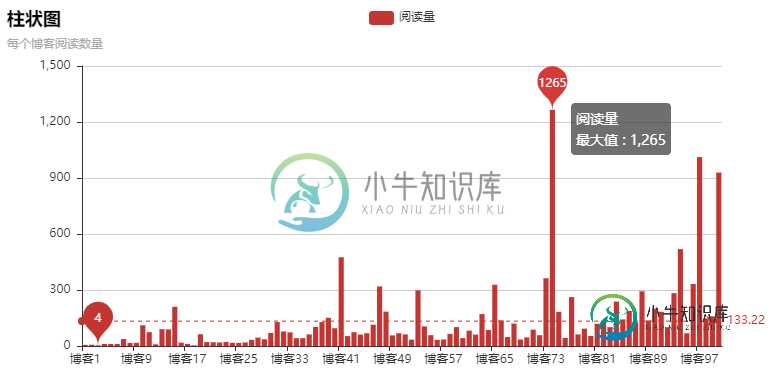 Python爬虫爬取博客实现可视化过程解析
Python爬虫爬取博客实现可视化过程解析本文向大家介绍Python爬虫爬取博客实现可视化过程解析,包括了Python爬虫爬取博客实现可视化过程解析的使用技巧和注意事项,需要的朋友参考一下 源码: 爬虫不是重点,只是拿来爬阅读数量,pyecharts是重点 这次爬的是我自己的博客,一共10页,每页10片文章,正好写了100篇博客 pyecharts安装: pip install wheelpip install pyecharts==0.
-
python 爬取微信文章
本文向大家介绍python 爬取微信文章,包括了python 爬取微信文章的使用技巧和注意事项,需要的朋友参考一下 本人想搞个采集微信文章的网站,无奈实在从微信本生无法找到入口链接,网上翻看了大量的资料,发现大家的做法总体来说大同小异,都是以搜狗为入口。下文是笔者整理的一份python爬取微信文章的代码,有兴趣的欢迎阅读
-
python scrapy爬虫代码及填坑
本文向大家介绍python scrapy爬虫代码及填坑,包括了python scrapy爬虫代码及填坑的使用技巧和注意事项,需要的朋友参考一下 涉及到详情页爬取 目录结构: kaoshi_bqg.py xmly.py item.py pipelines.py starts.py 然后是爬取到的数据 小说 xmly.json 记录一下爬取过程中遇到的一点点问题: 在爬取详情页的的时候, 刚开始不知道
-
 python 中xpath爬虫实例详解
python 中xpath爬虫实例详解本文向大家介绍python 中xpath爬虫实例详解,包括了python 中xpath爬虫实例详解的使用技巧和注意事项,需要的朋友参考一下 案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面。 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1、首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构。
-
 浅谈Python爬虫基本套路
浅谈Python爬虫基本套路本文向大家介绍浅谈Python爬虫基本套路,包括了浅谈Python爬虫基本套路的使用技巧和注意事项,需要的朋友参考一下 什么是爬虫? 网络爬虫也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据, 比如:如果响应内容是html,分析dom结构,进行dom解析、或者正则匹配,如果响应内容是xml/json数据,就可以
-
使用requests库制作Python爬虫
本文向大家介绍使用requests库制作Python爬虫,包括了使用requests库制作Python爬虫的使用技巧和注意事项,需要的朋友参考一下 使用python爬虫其实就是方便,它会有各种工具类供你来使用,很方便。Java不可以吗?也可以,使用httpclient工具、还有一个大神写的webmagic框架,这些都可以实现爬虫,只不过python集成工具库,使用几行爬取,而Java需要写更多的行
-
八、Python网络爬虫基础(下)