《python爬虫》专题
-
Okhttp3实现爬取验证码及获取Cookie的示例
本文向大家介绍Okhttp3实现爬取验证码及获取Cookie的示例,包括了Okhttp3实现爬取验证码及获取Cookie的示例的使用技巧和注意事项,需要的朋友参考一下 目前正在做毕业设计,一个关于校园服务的app,我会抽取已完成的相关代码写到文章里。一是为了造福这个曾经帮助过我的社区,二是写文章的同时更能巩固相关知识的记忆。 一、前言 在爬取教务系统的过程中,验证码的获取是非常重要的:在生成验证码
-
如何修复坚果爬行器中已存在的.locked?
我是nutch的初级用户。当我用bin/nutch抓取命令重新抓取时,我得到一个。锁定已经存在。 以下是我的例外。链接反转 /home/crawler_user/apache-nutch-1.14/bin/nutch invertlinks/data/crawlor_user/nutch/crawled-data/linkdb/data/crawle_user/nutch/crawled-data
-
python - 爬取apkpure网站,headers已经完全照搬浏览器数据requests发起请求为啥还是返回403?
代码如下,有无大佬解答 orz
-
AWS Glue作业将表转换为镶木地板,不需要另一个爬虫
有没有可能让粘合作业将JSON表重新分类为拼花,而不需要另一个爬虫来抓取拼花文件? 当前设置: 分区S3 bucket中的JSON文件每天爬网一次 我必须相信有一种方法可以在没有另一个爬虫的情况下转换表分类(但我以前被AWS烧伤过)。非常感谢任何帮助!
-
python - 求:关于爬取每次刷新页面后元素结构和对应class名都不相同的解决方法?
各位好,我使用 python的 selenium 去爬取某网页的 一些a标签,但有个问题,每次刷新后这个a标签所在的位置都会发生变化,比如第一次进入他的位置是: [@id="layoutPage"]/div[1]/div[2]/div[11]/div[2]/div[3]/div[2]/div/div[1]/div[1]/a 第二次刷新进入他就成了 [@id="layoutPage"]/div[1]
-
 如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求
如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求本文向大家介绍如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求,包括了如何准确判断请求是搜索引擎爬虫(蜘蛛)发出的请求的使用技巧和注意事项,需要的朋友参考一下 网站经常会被各种爬虫光顾,有的是搜索引擎爬虫,有的不是,通常情况下这些爬虫都有UserAgent,而我们知道UserAgent是可以伪装的,UserAgent的本质是Http请求头中的一个选项设置,通过编程的方式可以给请求设置任意的User
-
 Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法
Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法本文向大家介绍Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法,包括了Node.js+jade+mongodb+mongoose实现爬虫分离入库与生成静态文件的方法的使用技巧和注意事项,需要的朋友参考一下 接着这篇文章Node.js+jade抓取博客所有文章生成静态html文件的实例继续,在这篇文章中实现了采集与静态文件的生成,在实际的采集项目中, 应
-
在Scrapy中通过身份验证的会话进行爬网
问题内容: 在上一个问题中,我对问题不是很具体(希望通过与Scrapy进行身份验证的会话进行爬取),希望能够从更笼统的答案中得出解决方案。我应该宁可使用这个词。 因此,这是到目前为止的代码: 如您所见,我访问的第一页是登录页面。如果尚未通过身份验证(在函数中),则调用自定义函数,该函数将发布到登录表单中。然后,如果我 我 验证,我想继续爬行。 问题是我尝试覆盖以登录的功能,现在不再进行必要的调用以
-
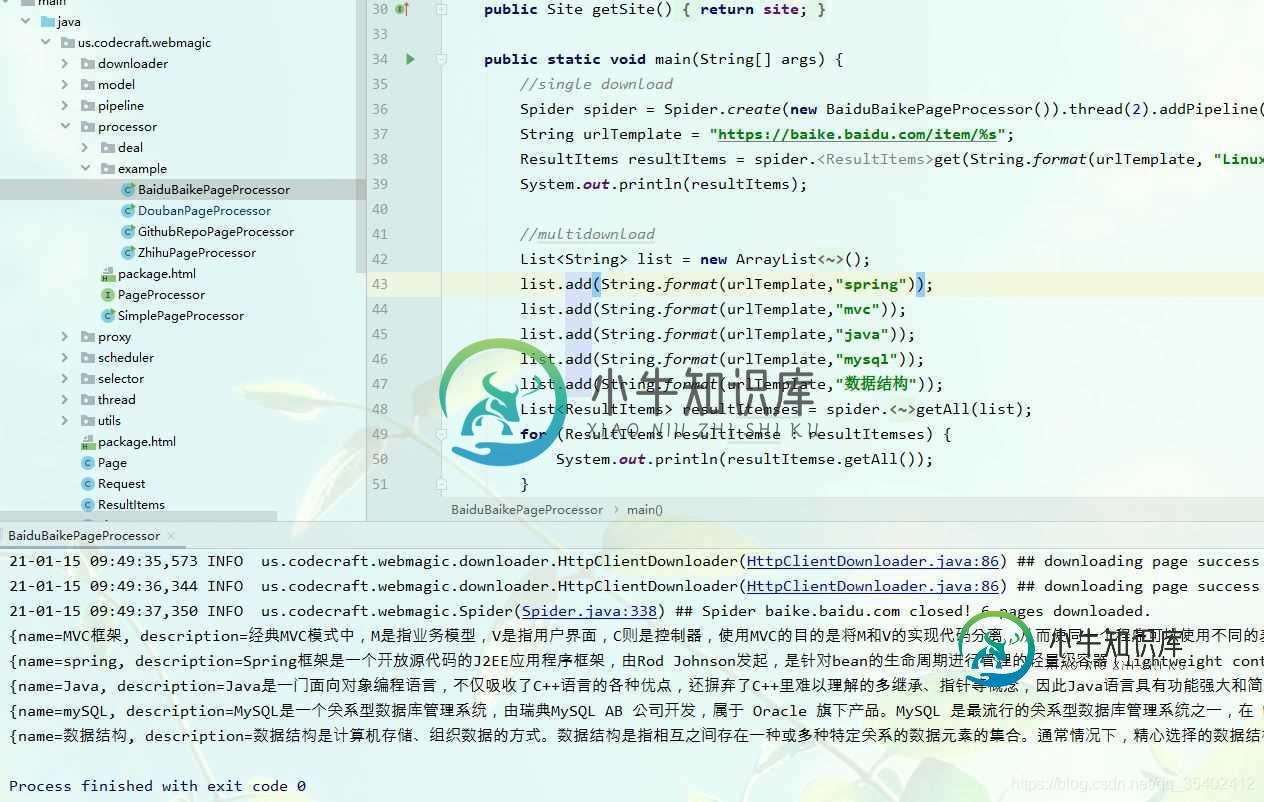 Java基于WebMagic爬取某豆瓣电影评论的实现
Java基于WebMagic爬取某豆瓣电影评论的实现本文向大家介绍Java基于WebMagic爬取某豆瓣电影评论的实现,包括了Java基于WebMagic爬取某豆瓣电影评论的实现的使用技巧和注意事项,需要的朋友参考一下 目的 搭建爬虫平台,爬取某豆瓣电影的评论信息。 准备 webmagic是一个开源的Java垂直爬虫框架,目标是简化爬虫的开发流程,让开发者专注于逻辑功能的开发。webmagic的核心非常简单,但是覆盖爬虫的整个流程,也是很好的学习爬
-
坚果爬网文档的Elasticsearch映射中面临的问题
问题内容: 在使用nutch和elasticsearch进行爬网时面临一些严重的问题。 我们的应用程序中有两个数据存储引擎。 的MySQL elasticsearch 可以说我在mysql db的urls表中存储了10个url。现在,我想在运行时从表中获取这些url,并将其写入seed.txt以进行爬网。我已经将所有这些网址一次性写入了txt。现在,我开始抓取,然后将这些文档在elasticsea
-
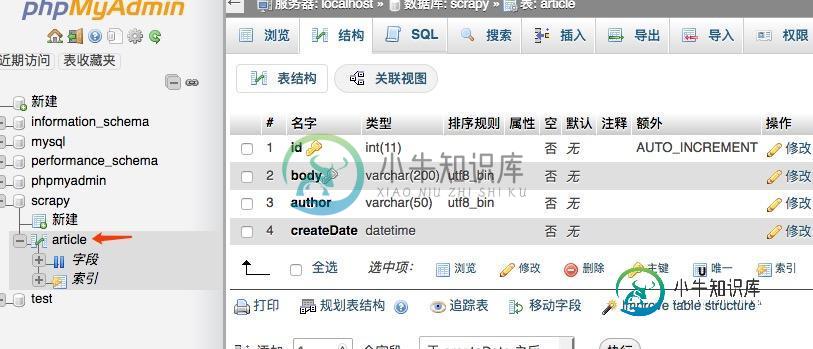 利用scrapy将爬到的数据保存到mysql(防止重复)
利用scrapy将爬到的数据保存到mysql(防止重复)本文向大家介绍利用scrapy将爬到的数据保存到mysql(防止重复),包括了利用scrapy将爬到的数据保存到mysql(防止重复)的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于scrapy爬到的数据保存到mysql(防止重复)的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧。 1.环境建立 1.使用xmapp安装php, mysql
-
使用nutch爬行时拒绝身份验证和连接错误
根据Nutch教程 http://wiki.apache.org/nutch/httpauthenticationschemes#a_note_on_ntlm_domains > 我已经在文件中设置了auth-configuration: http.auth.file httpclient-auth.xml“protocol-httpclient”插件的身份验证配置文件。 但对我来说没有成功! 是
-
前端 - py爬虫绕过猫眼验证码时,无法选择验证码内的元素?
前言:最近对爬虫感兴趣,看了崔的爬虫教程书,学到了滑块验证。跟着做的过程中突然想起刚学的时候,爬猫眼电影总是跳转验证码,学完一下opencv库的使用,想着复仇一下。 我首先编写简单的代码验证猫眼跳转的验证码,地址为猫眼验证码 无论选择的是什么元素,程序始终会报错。耗费大量时间后仍然没有取得答案,于是恳请各位佬给点提示或者指导。 代码方面 slider = wait.until(EC.element
-
python
我有一个数据框我想选择列A的值在[2,3]中的行 为此,我编写了一个简单的for循环: 有没有任何内置函数可以代替使用for循环来实现这一点?
-
Python
Python Python 诞生之初就被誉为最容易上手的编程语言。进入火热的 AI 人工智能时代后,它也逐渐取代 Java,成为编程界的头牌语言。 Python 是一门新手友好、功能强大、高效灵活的编程语言,学会之后无论是想进入数据分析、人工智能、网站开发这些领域,还是希望掌握第一门编程语言,都可以用 Python 来开启无限未来的无限可能! 语言排行榜 编程之旅 Python 适合谁来学习? 想