
如何爬取通过ajax加载数据的网站

目前很多网站都使用ajax技术动态加载数据,和常规的网站不一样,数据时动态加载的,如果我们使用常规的方法爬取网页,得到的只是一堆html代码,没有任何的数据。
请看下面的代码:
url = 'https://www.toutiao.com/search/?keyword=美女'
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0"}
response = requests.get(url,headers=headers)
print(response.text)
上面的代码是爬取今日头条的一个网页,并打印出get方法返回的文本内容如下图所示,值现在一堆网页代码,并没有相关的头条新闻信息
内容过多,只截取部分内容,有兴趣的朋友可以执行上面的代码看下效果。
对于使用ajax动态加载数据的网页要怎么爬取呢?我们先看下近日头条是如何使用ajax加载数据的。通过chrome的开发者工具来看数据加载过程。
首先打开chrome浏览器,打开开发者工具,点击Network选项,点击XHR选项,然后输入网址:https://www.toutiao.com/search/?keyword=美女 ,点击Preview选项卡,就会看到通过ajax请求返回的数据,Name那一栏就是ajax请求,当鼠标向下滑动时,就会出现多条ajax请求:
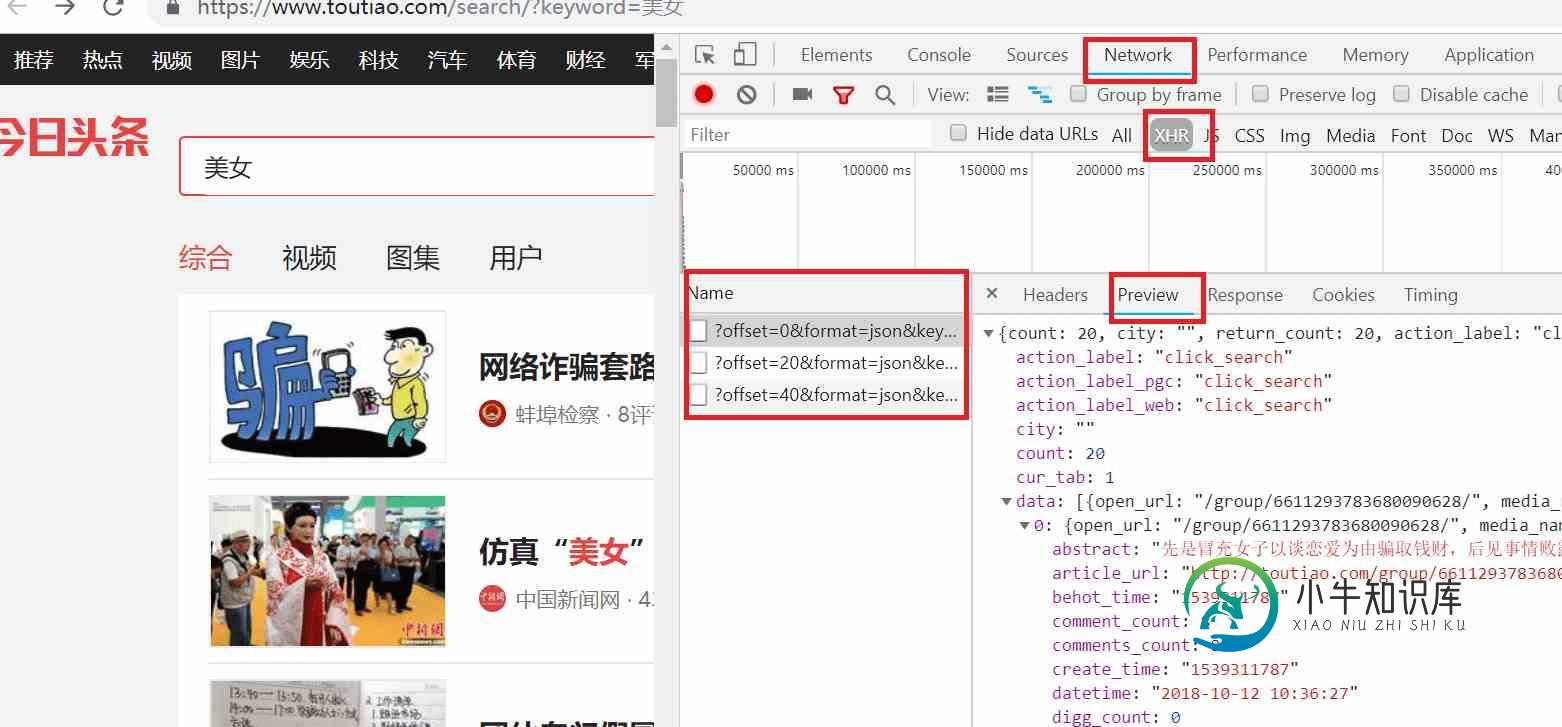
通过上图我们知道ajax请求返回的是json数据,我们继续分析ajax请求返回的json数据,点击data展开数据,接着点击0展开数据,发现有个title字段,内容刚好和网页的第一条数据匹配,可知这就是我们要爬取的数据。如下所示:

鼠标向下滚动到网页底部时就会触发一次ajax请求,下面是三次ajax请求:
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis https://www.toutiao.com/search_content/?offset=20&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis https://www.toutiao.com/search_content/?offset=40&format=json&keyword=%E7%BE%8E%E5%A5%B3&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis
观察每个ajax请求,发现每个ajax请求都有offset,format,keyword,autoload,count,cur_tab,from,pd参数,除了offset参数有变化之外,其他的都不变化。每次ajax请求offset的参数变化规律是0,20,40,60…,可以推测offset是偏移量,count参数是一次ajax请求返回数据的条数。
为了防止爬虫被封,每次请求时要把请求时都要传递请求头信息,请求头信息中包含了浏览器的信息,如果请求没有浏览器信息,就认为是网络爬虫,直接拒绝访问。request header信息如下:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3",
'x-requested-with': 'XMLHttpRequest'
}
完整代码如下:
import requests
from urllib.parse import urlencode
def parse_ajax_web(offset):
url = 'https://www.toutiao.com/search_content/?'
#请求头信息
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0",
"referer": "https://www.toutiao.com/search/",
'x-requested-with': 'XMLHttpRequest'
}
#每个ajax请求要传递的参数
parm = {
'offset': offset,
'format': 'json',
'keyword': '美女',
'autoload': 'true',
'count': 20,
'cur_tab': 1,
'from': 'search_tab',
'pd': 'synthesis'
}
#构造ajax请求url
ajax_url = url + urlencode(parm)
#调用ajax请求
response = requests.get(ajax_url, headers=headers)
#ajax请求返回的是json数据,通过调用json()方法得到json数据
json = response.json()
data = json.get('data')
for item in data:
if item.get('title') is not None:
print(item.get('title'))
def main():
#调用ajax的次数,这里调用5次。
for offset in (range(0,5)):
parse_ajax_web(offset*20)
if __name__ == '__main__':
main()
上面是爬取通过ajax请求加载数据网站的例子,如果想要其他的数据,可以动手自己写,这里只是搭了一个架子,各位可以尝试将数据写入到excel或者数据库中。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持小牛知识库。
-
我试图通过插入URL来使用JavaScript获取整个网页。但是,该网站被构建为一个单页面应用程序(SPA),它使用JavaScript/Backbone.js在呈现初始响应后动态加载大部分内容。 例如,当我路由到以下地址时: 然后在控制台中输入以下内容(在页面加载之后): 我在这里尝试了每个标记的内容的解决方案,但它看起来不够健壮,无法实际加载页面: 问:在JavaScript上完全加载网页的选
-
问题内容: 我想将页面上的一些数据发送到servlet 所以我写了下面的jQuery来做到这一点 我使用所有数据构建一个json字符串,并将其直接发送到servlet 但是我不知道如何从servlet中的ajax获取全部数据 如果查看来自chrome的请求标头的Form Data段 您会看到整个json字符串是关键。 问题答案: 看这里, 您的归属是错误的。它不应该是字符串,而是真实的JSON对象
-
问题内容: 我正在尝试通过ajax和php调用一些数据库数据。但是ajax调用不起作用,我无法在网络上找到解决方案。 所以这是我的代码: test.php 如果我在浏览器中键入该网址: 通过jsonEncode返回的数据是正确的,但是当我使用jquery将其加载到html页面时,他无法读取数据。 test.html 提前致谢。 问题答案: 您的 变量 没有价值。您想使用 字符串 。也许您也希望能够
-
我在这里找过类似的帖子,但是我找不到符合我要求的帖子。我试图显示jQuery数据。在UI上,我得到日期参数,并对servlet进行ajax调用。servlet将处理并返回json数据。一旦我得到的数据,我想显示在数据表的结果。但是我的代码不起作用。我是新的数据。这是我的代码: servlet返回的json数据:
-
问题内容: 我的页面上有一些CSS类=“ hello”的Divs。此外,我使用Ajax通过CSS class =“ hello”来获取更多Divs。我有一段代码被称为Divs的Click事件,如下: 从一开始,它就可以与我页面中存在的Divs一起正常工作,但不适用于使用Ajax加载的Divs。为了将这小段代码与新加载的Divs绑定在一起,我需要做些什么吗? 问题答案: 您应该用来将处理程序绑定到绑
-
问题内容: 好的,所以我对ajax和从外部加载内容还很陌生,希望对我的问题有任何见解。 我目前有一个隐藏的div,它是空的,单击链接后应该在其中加载ajax内容。 我目前有一个链接列表,所有链接都具有相同的类,并且我想在单击空白div时进行幻灯片切换,然后从链接要访问的页面中加载内容。 链接: 当前的jQuery: 刚接触Ajax并加载外部内容时,我想知道如何从位于标签中的链接页面加载内容。因此,