
1.3.3.6 关联分析
1. 简介
关联分析,顾名思义用于计算两个要素之间的相关性。
在增长黑客的诸多经典案例中,facebook 的“A-Ha Moment”为人所知。Facebook 通过挖掘发现新用户在前10天内至少添加7个好友时,最可能在次周留存。这里“前10天添加7个好友”即为 facebook 用户增长的“A-Ha Moment”,也切实的指导了 facebook 后续用户增长的运营与产品方向。
纯人力的“A-Ha Moment”分析,要耗费专业的分析师大量的时间与精力,而“关联分析”正是通过引入机器学习的算法模型,并利用机器算力的优势实现 “A-Ha Moment”的自动化分析,真正实现业务人员只需轻松点击“开始分析”,即可在数秒钟内得到可直接应用于自己业务的“A-Ha Moment”,开启用户增长。
2. 使用说明
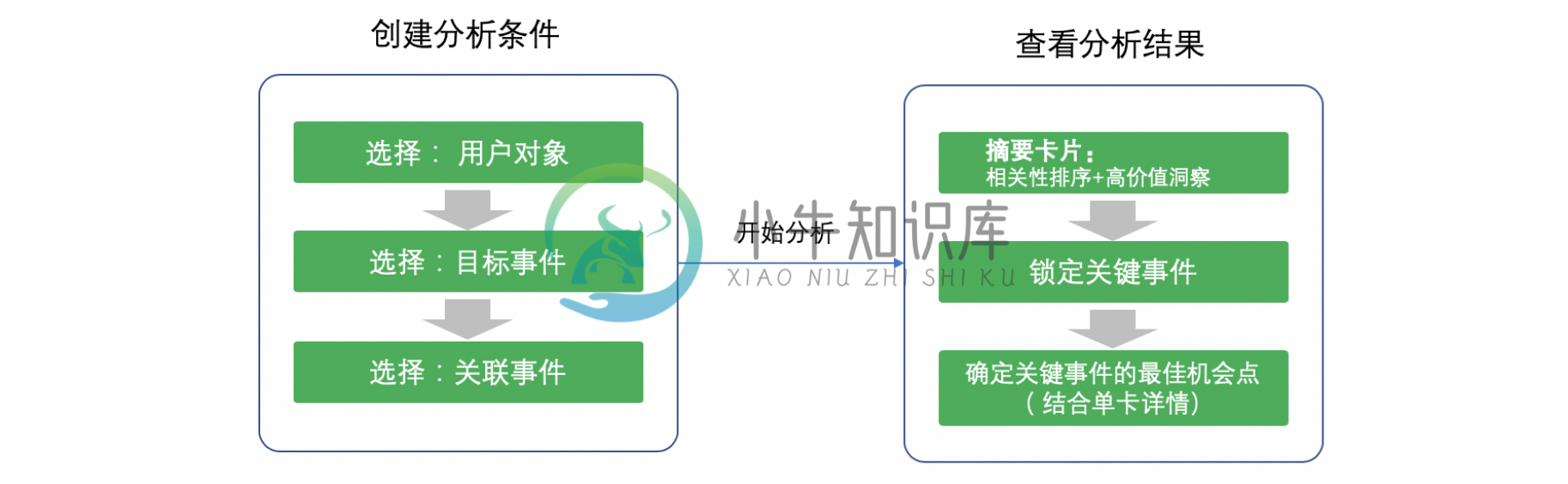
以下按照“分析新用户留存与哪些事件有关”为例做说明
2.1. 创建查询
- 用户对象选择:近3个月新用户
- 目标事件选择:第2周留存
- 关联事件选择:任意事件
- 点击“开始分析”
2.2. 分析结果
- 按照“相关系数由高到低排序”
- 排序靠前的事件,即为新用户与次周留存强相关的事件
- 在强相关事件中,参考给出的“洞察”为“优化空间与优化效率”均较高的事件。即可重点考察这些“事件”的最佳机会点,考虑选择其中1-2个作为“A-Ha Moment”的备选结果。

3. 创建查询
3.1. 创建总体逻辑
选择“用户对象”--> 选定“目标事件 -->选定“关联事件”--> 点击“开始分析”
3.2. 用户对象
通过“日期”+“用户类型”+“事件过滤”三者来定义。

- 日期:近30天、近60天、近90天、近180天、近360天。当所选时间段越长时,每个用户有越长的时间来完成目标事件,有助于提升分析结果的置信度。同时,考虑到性能,我们会按照用户粒度进行抽样。确保每个用户的分析结果是完整且准确的。
- 用户类型:目前支持选择“新用户”和“全部用户”
- 事件过滤:支持选择用户群组后,对用户群组添加1个事件筛选条件(包括事件筛选+事件触发次数:即指定用户需触发过某个事件至少X次;)

3.3. 目标事件
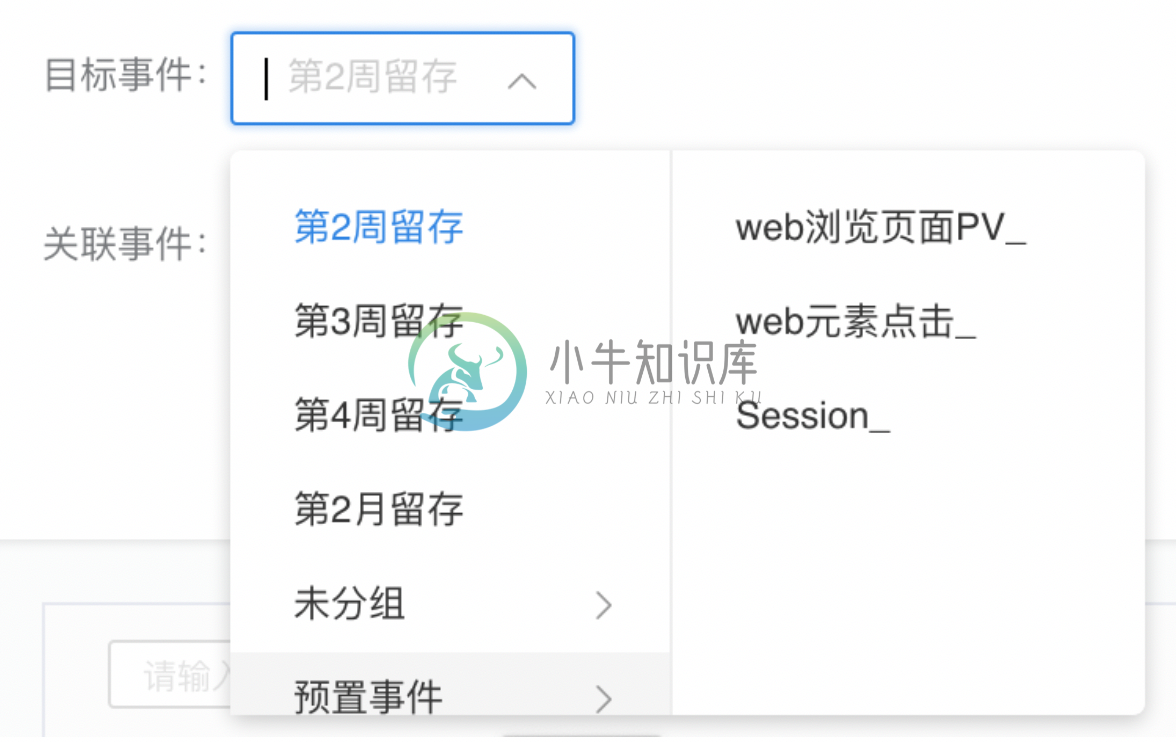
- 支持选择的目标事件分为两类,一类是“留存目标”,另一类是事件目标。
- 在“留存目标”中,可以选择第2周留存、第3周留存、第4周留存、第2月留存。
- 在“事件目标”中,可以选择任意一个事件,且设置该事件至少完成多少次才算是达成目标。

3.4. 关联事件
- 关联事件:即是指希望用来分析与目标事件有关系的具体行为。目前支持选择“TOP事件”与“指定事件”
- TOP 事件:当不确定希望分析哪些事件与目标有关时,可以选择“top事件”,平台会帮助选择昨日启动次数较高的 top 事件,逐一分析这些事件与目标事件的关系。
- 指定事件:支持自行指定至多10个事件。适用于已经明确了希望分析 A 事件与留存目标的关系时,可以在关联事件中只选择“A 事件”,以便更快速的得到分析结果。
4. 分析结果
4.1. 摘要卡片页
点击了“开始分析”后,在分析条件的下方,生成分析结果的摘要卡片(如下图)。摘要卡片主体分为三个部分:关联事件及其最佳机会点、相关性与洞察

- 最佳机会点:每个关联事件都会有一个“最佳机会点”,通常描述为为“近 X 天内至少完成 N 次 某某事件”,最佳机会点是系统通过计算该事件的140个事件达成状态分别与目标事件的相关性后,综合给出的相关性最高的事件状态。
- 相关性:即当前事件与目标事件相关的程度。我们将事件的相关性,分为了四中状态:强相关、适度相关、弱相关、微弱或不相关。
洞察
结合机器学习的分析结果,将该事件的最佳机会点对业务的价值从两个维度给出了直观的评价,分别是“优化空间”与“优化效率”。
- 优化空间:考察完成该事件状态的用户占比,从而确定可优化的空间。
优化效率:通过相关性和灵敏性分析,确定该事件完成对目标完成的有效影响程度。
因此,我们建议您对于每个事件的分析,不能仅看相关性,还需结合给出的“优化空间与效率”的洞察结果,进行综合判断。
例如,分析与“注册完成”事件相关的事件有哪些?对于“填写信息”这个事件来说,其关联分析的结果会是“相关性极强,但优化空间极小”。因此这种分析结果意味着“填写信息”是“注册完成”明确的上游操作路径。
4.2. 某个事件的分析详情结果页
点击“事件名称”或“查看详情”进入到该事件的分析结果详情页。

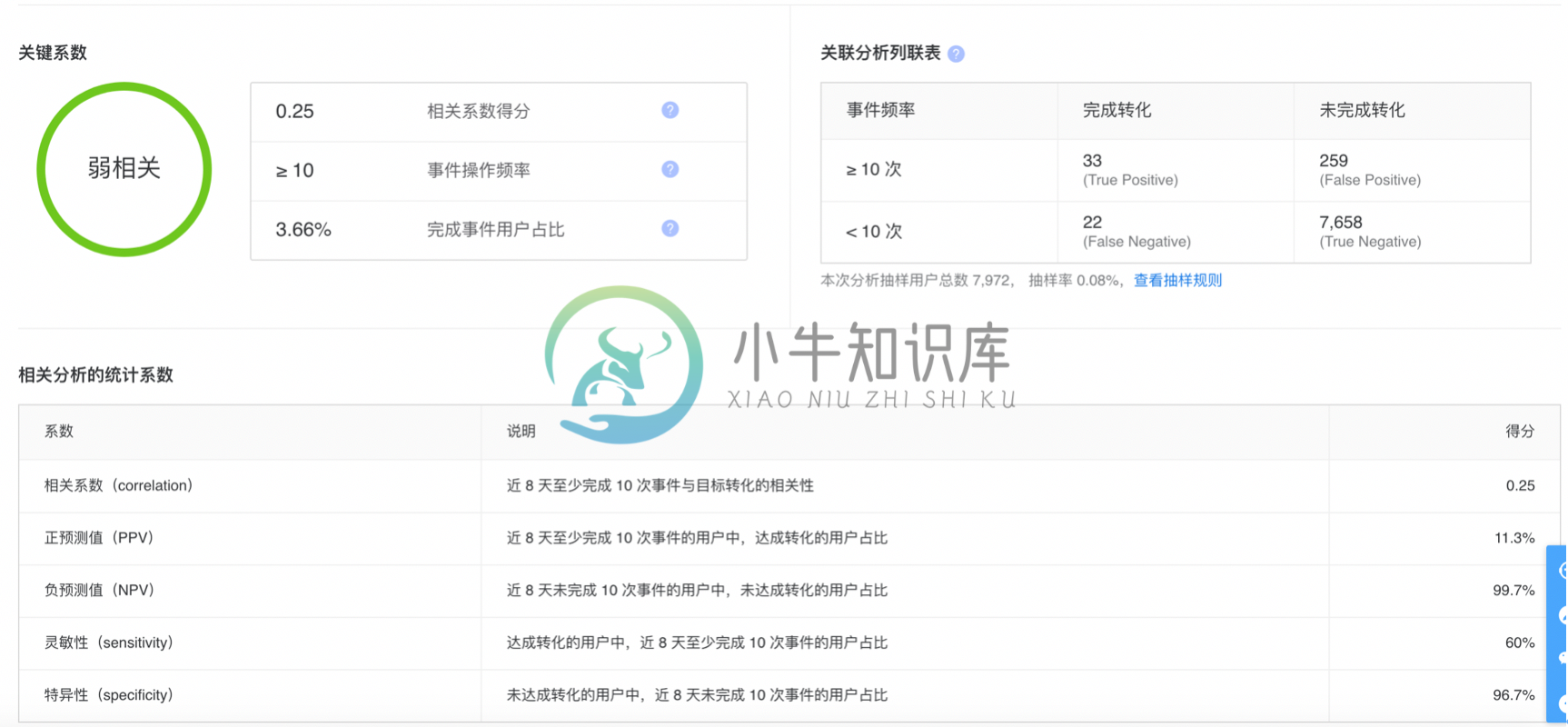
- 机会点分布图:详情页给出了该事件的“机会点分布图”,以及每一个事件状态(N 天完成 X 次)的相关分析详细结果。
- 关键系数:通过三个核心指标,展示该事件状态的 相关分析结果。
- 关联分析列联表:分析云关联分析使用的核心模型是统计学上的“Phi 系数分析模型”,通过对用户样本“事件完成状态”与“目标达成状态”两个维度的计算,得出该“列联表”,并通过标准的 phi 系数分析模型计算得出当前事件状态的相关系数及其它指标。
- 相关分析的统计系数:结合 phi 系数分析模型与机器学习模型产出的核心数据指标,可用于更深度的分析该事件与目标的相关分析结果。
5. 分析的采样规则
在分析过程中,系统按照用户维度进行样本抽取,确保每个用户在考察时间范畴内的行为被完整记录。
抽样的样本量大小与当前分析云的版本有关,同时也与本次分析的用户对象筛选范围内的总用户量有关。系统均是在确保必要的就结果产出效率最优的情况下的最高标准进行采样。
6. 指标/维度
| 指标/维度 | 说明 |
|---|---|
| 相关性 | 通过相关系数的不同,匹配对应的五个相关程度的等级描述,分为:强相关、适度相关、弱相关、微弱或不相关 |
| 事件操作频率 | 事件操作频率是指在 N 天内该事件至少被完成多少次, 用来反映事件被完成的速度。 |
| 完成事件用户占比 | 完成事件的用户占比等于“抽样用户中, N 天内至少完成 X 次事件的用户数占总用户数的比例”。 |
| 相关系数 | 相关系数 相关系数即统计学上的 phi 系数, 用来描述目标事件与关联事件之间的相关性,得分越高则相关性越强,最大值为1 |
| 正预测值(PPV) | 近N天至少完成X次事件的用户中,达成转化的用户占比 |
| 负预测值(NPV) | 近N天未完成X次事件的用户中,未达成转化的用户占比 |
| 灵敏性(sensitivity) | 达成转化的用户中,近N天至少完成X次事件的用户占比 |
| 特异性(specificity) | 未达成转化的用户中,近N天未完成X次事件的用户占比 |