《雪花算法》专题
-
bandit算法
假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为p 我们不断地试验,去估计出一个置信度较高的*概率p的概率分布*就能近似解决这个问题了。 怎么能估计概率p的概率分布呢? 答案是假设概率p的概率分布符合beta(wins, lose)分布,它有两个参数: wins, lose。 每个臂都维护一个beta分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的
-
图算法
GraphX包括一组图算法来简化分析任务。这些算法包含在org.apache.spark.graphx.lib包中,可以被直接访问。 PageRank算法 PageRank度量一个图中每个顶点的重要程度,假定从u到v的一条边代表v的重要性标签。例如,一个Twitter用户被许多其它人粉,该用户排名很高。GraphX带有静态和动态PageRank的实现方法 ,这些方法在PageRank object
-
1.1.3 算法
1.1.3 算法 如前所述,程序是解决某个问题的指令序列。编程解决一个问题时,首先要找出解决问 题的方法,该解决方法一般先以非形式化的方式表述为由一系列可行的步骤组成的过程,然 后才用形式化的编程语言去实现该过程。这种解决特定问题的、由一系列明确而可行的步骤 组成的过程,称为算法(algorithm①)。算法表达了解决问题的核心步骤,反映的是程序的解 题逻辑。 算法其实并不是随着计算机的发明才出现
-
Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均 [1]。下面我们来介绍这个算法。 算法 Adam算法使用了动量变量$\boldsymbol{v}_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$,并在时间步0将它们中每个元素初始化为0。给定超参数$0 \leq \beta_1 < 1$(算法作者建议设为0.9
-
AdaDelta算法
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进 [1]。有意思的是,AdaDelta算法没有学习率这一超参数。 算法 AdaDelta算法也像RMSProp算法一样,使用了小批量随机梯度$\boldsymbol{g}_t$按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$。在时间步0,它的所有元
-
RMSProp算法
我们在“AdaGrad算法”一节中提到,因为调整学习率时分母上的变量$\boldsymbol{s}_t$一直在累加按元素平方的小批量随机梯度,所以目标函数自变量每个元素的学习率在迭代过程中一直在降低(或不变)。因此,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小
-
AdaGrad算法
在之前介绍过的优化算法中,目标函数自变量的每一个元素在相同时间步都使用同一个学习率来自我迭代。举个例子,假设目标函数为$f$,自变量为一个二维向量$[x_1, x_2]^\top$,该向量中每一个元素在迭代时都使用相同的学习率。例如,在学习率为$\eta$的梯度下降中,元素$x_1$和$x_2$都使用相同的学习率$\eta$来自我迭代: $$x_1 \leftarrow x_1 - \eta \f
-
9.11 算法
当你编写一个针对一类问题的通用解法,而非针对某一个问题的特定解法时,你就写出了一个算法。我在第一章提到过这个词,但是没有给出详细定义。这也不太好定义,所以我会试用多种方式进行定义。 首先,考虑一些不是算法的问题。当你学习个位数乘法时,你可能会背乘法表。实际上你记住的是100个特定解法,这种知识并不是真正意义的算法。 但是,如果你很“懒”,你可能学习一些作弊技巧。比如,求n与9的乘积,你可以在第一位
-
10 算法
算法策略 分治法T(n)=O(nlogn) 将问题分解成规模较小、相互独立的子问题,各个击破,分而治之。 归并排序 将数列分为几个序列片段,逐趟两两归并,到底层归并成有序数列 最大子段和问题 动态规划法T(n)=O(nW) 将问题分解成互不独立子问题,保存子问题解,需要时再用,例如多项式时间算法 0/1背包问题 LCS最长公共子序列 贪心/贪婪法T(n)=O(n) 不从整体最优考虑,只根据当前信息
-
LRU 算法
一、前言 上一章《Memcached源码分析 - Memcached源码分析之增删改查操作(5) 》中,我们讲到了SET命令的操作。当客户端向Memcached服务端SET一条缓存数据的时候,会将生成的Item地址挂到LRU的链表结构上。这一章节,我们主要讲一下Memcached是如何使用LRU算法的。 LRU:是Least Recently Used 近期最少使用算法。 二、Memcached的
-
1.-算法
名称 原理 复杂度 插入排序 对于元素索引i(i>=1),从头开始,若能找到比 a[i] 大对元素 a[j],则记录 a[i] 的值,将索引 j~i-1 的元素向后移动一位,使用 a[i] 替换 a[j]。优化思路:针对数组可以采用二分查找找到当前元素的插入位置,链表不需要位移操作。 O(n^2/2) 选择排序 从当前元素开始遍历,记录最小值的索引,根据索引交换当前值的最小值,选择排序每次选出最小
-
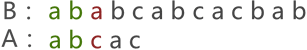 BF算法(串模式匹配算法)
BF算法(串模式匹配算法)主要内容:BF算法原理,BF算法实现,BF算法时间复杂度,总结串的模式匹配算法,通俗地理解,是一种用来判断两个串之间是否具有"主串与子串"关系的算法。 主串与子串:如果串 A(如 "shujujiegou")中包含有串 B(如 "ju"),则称串 A 为主串,串 B 为子串。主串与子串之间的关系可简单理解为一个串 "包含" 另一个串的关系。 实现串的模式匹配的算法主要有以下两种: 普通的模式匹配算法; 快速模式匹配算法; 本节,先来学习 普通模式匹配(BF)
-
寻找计算图节点的算法
假设我有一个无向多图,即一个(G,E)对,其中G是一个有限的结点集,E是一个有限的边集。我正在寻找一个算法,将分配一个单一的字符串值到每个节点在以下的约束。 1. 每个节点都被赋予一组约束(可能是空的),这些约束限制了允许的值。我希望至少支持以下类型的值约束: null 有两种类型的边缘: 不同, 相同, 这意味着应该为相关节点分配不同/相同的值(意味着不相等/相等的字符串)。 null 这意味着
-
算法题 - 一致性哈希算法
一致性哈希算法 tencent2012笔试题附加题 问题描述: 例如手机朋友网有n个服务器,为了方便用户的访问会在服务器上缓存数据,因此用户每次访问的时候最好能保持同一台服务器。 已有的做法是根据ServerIPIndex[QQNUM%n]得到请求的服务器,这种方法很方便将用户分到不同的服务器上去。但是如果一台服务器死掉了,那么n就变为了n-1,那么ServerIPIndex[QQNUM%n]与S
-
数据结构与算法 - KMP算法
KMP算法解决的问题是字符匹配,这个算法把字符匹配的时间复杂度缩小到O(m+n),而空间复杂度也只有O(m),n是target的长度,m是pattern的长度。 部分匹配表(Next数组):表的作用是 让算法无需多次匹配S中的任何字符。能够实现线性时间搜索的关键是 在不错过任何潜在匹配的情况下,我们”预搜索”这个模式串本身并将其译成一个包含所有可能失配的位置对应可以绕过最多无效字符的列表。 Nex