《雪花算法》专题
-
 5/15同花顺b2b前端二面
5/15同花顺b2b前端二面全程约半小时,几乎无八股考察,全程问经历和学习方法 自我介绍 介绍一下自己的项目经历 介绍一下实习项目 为什么实习中要对项目进行重构 在实习项目中学习到了什么东西 对移动端适配有什么了解 对前端优化方案有哪些了解 说一下过去的项目中有遇到哪些技术问题,怎么解决的 为什么会选择前端 学习路线是怎么样的 系统学习js用了多长时间 如何去学习新技术 对node有没有了解(一知半解,会用但了解不深)
-
计算下个月开始日的算法
我正在写一个简单的日历课程。我正在尝试重载,以便使用它将日历移动到下个月。然而,我找到下个月开始日期的算法并不完全正确。 1月定义为0,12月为11,周日为0,周六为6。start Day、previousStartDay、nextStartDay、月份和年份都是私有类变量 当我在2013年进行测试时,日期直到3月都是正确的。在这一点上,它将下一个开始日定为周二,而不是周一。 我也试过: 然而,它
-
数据结构与算法 - 递归算法
从前有座山 山里有座庙 庙里有个老和尚和小和尚 老和尚对小和尚说: 从前有座山 返回1 从前有座山,山里有个庙,庙里有个和尚讲故事……这是一个古老的童谣,每个人都知道下面一句说了什么,但还要不厌其烦的说下去。犹如我们的人性,陷入一种循环,不可逃脱,无法自拔。 所以在我们现实生活中,很多时候也有所谓的重复性,而这种重复性用计算机解决的话,就能够省很多事情。 如果用一部电影来类比的话,那《盗梦空间》就
-
数据结构与算法 - 排序算法
常见排序算法 稳定排序: 冒泡排序 — O(n²) 插入排序 — O(n²) 桶排序 — O(n); 需要 O(k) 额外空间 归并排序 — O(nlogn); 需要 O(n) 额外空间 二叉排序树排序 — O(n log n) 期望时间; O(n²)最坏时间; 需要 O(n) 额外空间 基数排序 — O(n·k); 需要 O(n) 额外空间 不稳定排序 选择排序 — O(n²) 希尔排序 — O
-
数据结构与算法 - 查找算法
ASL 由于查找算法的主要运算是关键字的比较,所以通常把查找过程中对关键字的平均比较次数(平均查找长度)作为衡量一个查找算法效率的标准。ASL= ∑(n,i=1) Pi*Ci,其中n为元素个数,Pi是查找第i个元素的概率,一般为Pi=1/n,Ci是找到第i个元素所需比较的次数。 顺序查找 原理是让关键字与队列中的数从最后一个开始逐个比较,直到找出与给定关键字相同的数为止,它的缺点是效率低下。时间复
-
K-Means 聚类算法 kmeans 聚类算法
算法介绍 K-Means又名为K均值算法,他是一个聚类算法,这里的K就是聚簇中心的个数,代表数据中存在多少数据簇。K-Means在聚类算法中算是非常简单的一个算法了。有点类似于KNN算法,都用到了距离矢量度量,用欧式距离作为小分类的标准。 算法步骤 (1)、设定数字k,从n个初始数据中随机的设置k个点为聚类中心点。 (2)、针对n个点的每个数据点,遍历计算到k个聚类中心点的距离,最后按照离哪个中心
-
SVM 支持向量机算法 Svm 算法
参考资料:http://www.cppblog.com/sunrise/archive/2012/08/06/186474.html http://blog.csdn.net/sunanger_wang/article/details/7887218 我的数据挖掘算法代码:https://github.com/linyiqun/DataMiningAlg
-
 计算机视觉算法岗面经(二)
计算机视觉算法岗面经(二)四月很多面试都推掉了,所以只面了两个厂,字节和虹软。顺便问下,华为暑期实习不推进的话会影响秋招吗? 字节一面: 自我介绍 分类和回归常见的损失函数? 逻辑斯蒂,hingeloss,l1,BCE,focal等等 BCE的公式是什么,和KL散度的关系和区别? 一部分log的系数不一样 selfattention的原理和过程 为什么selfattention能注意该注意的地方,你能数学证明出来吗? 我能
-
火花之间的区别是什么。罐子和火花。驾驶员类外路径[重复]
我试图运行火花程序,在纱线客户端模式下使用火花提交,并获得类NotFindException。所以我的问题是我应该在哪个参数中传递我的jar(--jars或--drier-class-path)。 Spark=2.0.0 HDP 2.5 Hadoop=2.7.3
-
 今天面了同花顺和同程,同花顺toC的岗位,等下更新下面筋
今天面了同花顺和同程,同花顺toC的岗位,等下更新下面筋同程艺龙一面,岗位是市场营销-场景运营 是一个女面试官,很和蔼 首先是自我介绍 其次是问看简历实习很丰富,你是如何看待学校的课程成绩和实习工作的呢? 挑了两段简历,简要的问了一下大概做的什么? 其中让你最深刻的事是什么? 做的一个方案一个结果是怎么样的,数据是多少? 我看你简历中有些数据分析的情况,excel用的怎么样,用那些函数,数据透视怎么样? 能分享一个创新的案例吗?我没有过 如果通过的话,
-
对数算法
问题内容: 我需要以任何精度评估任何底数的对数。是否有一种算法?我使用Java编程,所以我对Java代码很好。 问题答案: 使用此身份: log b(n)= log e(n)/ log e(b) 其中可以在任何一个基对数函数,是数量和是基础。例如,在Java中,这将找到以2为底的对数256: 顺便使用base 。还有使用base的。
-
分区算法
操作系统实现了各种算法,以便找出链表中的空洞并将它们分配给进程。 关于每种算法的解释如下。 1. 第一拟合算法 第一拟合算法(First Fit)算法扫描链表,每当它找到第一个足够大的孔来存储进程时,它就会停止扫描并将进程加载到该进程中。 该过程产生两个分区。 其中,一个分区将是一个空洞,而另一个分区将存储该进程。 First Fit算法按照起始索引的递增顺序维护链表。这是所有算法中最简单的实现方
-
寻路算法
主要内容:src/runoob/graph/Path.java 文件代码:图的寻路算法也可以通过深度优先遍历 dfs 实现,寻找图 graph 从起始 s 点到其他点的路径,在上一小节的实现类中添加全局变量 from数组记录路径,from[i] 表示查找的路径上i的上一个节点。 首先构造函数初始化寻路算法的初始条件,from = new int[G.V()] 和 from = new int[G.V()],并在循环中设置默认值,visited 数组全部为false,fr
-
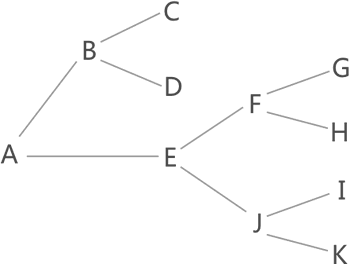 回溯算法
回溯算法主要内容:回溯算法的应用场景在图 1 中找到从 A 到 K 的行走路线,一些读者会想到用穷举算法(简称穷举法),即简单粗暴地将从 A 出发的所有路线罗列出来,然后逐一筛选,最终找到正确的路线。 图 1 找从A到K的行走路线 图 1 中,从 A 出发的路线有以下几条: A-B-C A-B-D A-E-F-G A-E-F-H A-E-J-I A-E-J-K 穷举法会一一筛选这些路线,最终找到 A-E-J-K 。 本节要讲的回溯算
-
贪心算法
主要内容:贪心算法的实际应用《 算法是什么》一节讲到,算法规定了解决问题的具体步骤,即先做什么、再做什么、最后做什么。贪心算法是所有算法中最简单,最易实现的算法,该算法之所以“贪心”,是因为算法中的每一步都追求最优的解决方案。 举个例子,假设有 1、2、5、10 这 4 种面值的纸币,要求在不限制各种纸币使用数量的情况下,用尽可能少的纸币拼凑出的总面值为 18。贪心算法的解决方案如下: 率先选择一张面值为 10 的纸币,可以