《猫眼》专题
-
熊猫read_excelUnicodeDecodeError:'utf-8'编解码器无法解码位置0的字节0xd0:无效的延续字节
以下代码创建错误 UnicodeDecodeError:“utf-8”编解码器无法解码位置0中的字节0xd0:无效的连续字节
-
熊猫:从Groupby创建一个数据帧,并在不同的列上应用和和平均值[重复]
我有以下数据帧 并且,我试图通过对奖牌分组,得到“数字”和“年龄”的平均值。我可以用两条线做,但是如何用熊猫Groupby单线做。 我可以一次做一个手术 或者 然后可能合并,这是一个漫长的过程。那么如何以这种方式实现呢 下面是所需的输出
-
如何从熊猫数据帧中删除在特定列中包含特定字符串的行?[重复]
我在python中有一个非常大的数据帧,我想把所有具有特定字符串的行放到特定列中。 例如,我想删除所有在数据帧的C列中有字符串“XYZ”作为子字符串的行。 这可以通过使用有效的方式实现。drop()方法?
-
寻找熊猫数据帧中两点之间平均边缘值最高的路径的有效方法?
请原谅这个问题看似混乱的措辞。这是我想做的。 给定数据帧df 以及对允许的最大路径长度L的约束 我希望返回一个具有最高平均路径的数据帧(即点之间的所有边的总和/路径长度最大),其中一个边由权重列表示,假设它不超过长度L。 用一个例子来说明我所说的最高平均路径: 假设我们只有4点A,B,C 最高的平均路径是max((A- 对于L=2,它将是最大值((A- 对于df,对于L=2,我们会得到 注意:这个
-
有没有一种简洁的方法来显示熊猫中的所有行,只显示当前命令?
有时我想显示数据帧中的所有行,但只显示单个命令或代码块。 当然,我可以将“max_rows”显示选项设置为一个较大的数字,但随后我必须重复该命令才能恢复到首选设置。(我个人最多喜欢12排)。 真烦人。 我在文档中读到我可以使用pd。如果我将命令与“with”语句结合使用,则可以使用option_context()函数来完成此操作: 我无法让它工作(没有返回输出)。但我认为这样的解决方案对于日常的偶
-
偏移量前滚加上加上一个月的偏移量后,熊猫超出了纳秒级时间戳
问题内容: 我感到困惑的是,大熊猫如何用这些行超出日期时间对象的范围: 这是设置的日期时间,并且是格式的日期信息。 此逻辑似乎适用于模拟数据(没有错误,日期有意义),因此目前我无法重现,但由于以下错误导致我的整个数据失败: 问题答案: 由于熊猫以纳秒分辨率表示时间戳,因此可以使用64位整数表示的时间跨度限制为大约584年 而且您的值超出此范围2262-05-01 00:00:00,因此发生出站错误
-
在熊猫中,如何将日期字符串转换为日期时间对象并将其放入DataFrame中?
问题内容: 此代码位产生错误: TypeError:“’int’对象不可迭代” 谁能告诉我如何将这一系列日期时间字符串作为对象放入DataFrame中? 问题答案: 更新 使用pandas.to_datetime(pd.Series(..))。简洁明了,比上面的代码要快得多。
-
猫鼬-创建文档(如果不存在),否则,在两种情况下均会更新并返回文档
问题内容: 我正在寻找一种将代码的一部分重构为更短,更简单的方法,但是我对Mongoose不太了解,并且不确定如何进行。 我正在尝试检查集合是否存在文档,如果不存在,则创建它。如果确实存在,我需要对其进行更新。无论哪种情况,我都需要稍后访问文档的内容。 到目前为止,我设法完成的工作是查询集合中的特定文档,如果找不到,则创建一个新文档。如果找到它,我将对其进行更新(当前使用日期作为虚拟数据)。从那里
-
如何在熊猫数据框的行中使类型成为结果为行类型的列标题?[重复]
我有一个按以下设置构造的df,并希望更改它,以便在列中找到的类型是行读取器,原始
-
如何通过拆分单个列中的字符串将其拆分为多个列-熊猫巨蟒〔复制〕
我有一个这样的专栏: 现在我想在dot在列中如下所示:
-
TypeError:第一个参数必须是熊猫对象的可迭代对象,您传递了“ DataFrame”类型的对象
问题内容: 我有一个大数据框,然后尝试将其拆分。我用 但它返回一个错误 我该如何解决? 问题答案: IIUC您需要以下内容: 您需要将每个块附加到列表中,然后用于将它们全部串联起来,我也认为可能没有必要,但是我可能错了
-
如何计算平均绝对误差(MAE)和平均有符号误差(MSE)使用熊猫/Numpy/python数学库?
我有一个如下的数据集。在该数据集中,有不同颜色的温度计,给定“真实”或参考温度,根据一些测量方法“方法1”和“方法2”,它们测量的差异有多大。 我在计算我需要的两个重要参数时遇到困难,这两个参数是平均绝对误差(MAE)和平均符号误差(MSE)。我想为每个方法使用非NaN值并打印结果。 我能够得到的点,我可以返回一个两列系列的索引和和,但在这种情况下的问题是,我需要除以方法值的数量总和,这取决于有多
-
将用户定义的函数应用于熊猫数据框的特定列,并向数据框添加新列
我创建了一个名为的函数,该函数采用了如图所示的这3个参数,结果是新参数。我想将此函数应用于一个数据帧,其中函数参数是数据帧中的某些列,并希望将函数的输出参数添加为数据帧中的新参数,在数据帧中为每行计算函数。
-
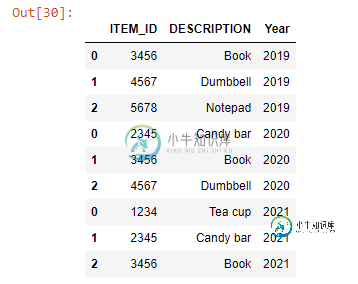 有没有更简单的方法将多个Excel工作簿读取到单个熊猫数据框中?[重复]
有没有更简单的方法将多个Excel工作簿读取到单个熊猫数据框中?[重复]我需要读取三个不同年份(2019年、2020年和2021年)的SKU列表,所有这些都存在于Excel工作簿中,每个工作簿都有一个标记为年份的工作表。我想将所有三个工作表读取到一个数据框中,并为SKU所属的适当年份创建一个列。 我做的方式是非常手动的(见下文)。有没有更高效的编码方式?
-
猫头鹰旋转木马未捕获的类型错误:未定义的是不是一个函数在WordPress[重复]
我是一个开发自己的WordPress主题。我在用猫头鹰旋转木马 但获取此错误,并且不显示任何转盘项目。对不起,我的英语不好。