
有没有更简单的方法将多个Excel工作簿读取到单个熊猫数据框中?[重复]

我需要读取三个不同年份(2019年、2020年和2021年)的SKU列表,所有这些都存在于Excel工作簿中,每个工作簿都有一个标记为年份的工作表。我想将所有三个工作表读取到一个数据框中,并为SKU所属的适当年份创建一个列。
我做的方式是非常手动的(见下文)。有没有更高效的编码方式?
'''
Read in the yearly SKU worksheets
'''
df2019= pd.read_excel('test.xlsx', sheet_name='2019', index_col=None, header=0)
df2019['Year'] = '2019'
df2020= pd.read_excel('test.xlsx', sheet_name='2020', index_col=None, header=0)
df2020['Year'] = '2020'
df2021= pd.read_excel('test.xlsx', sheet_name='2021', index_col=None, header=0)
df2021['Year'] = '2021'
df_all=pd.concat([df2019, df2020, df2021])
df_all.head(9)
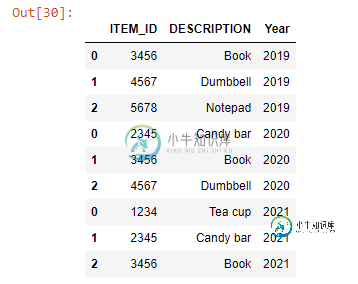
共有1个答案

您可以使用<code>熊猫。read_excel并使sheet_name=None在键是表名时返回数据帧的dict。
试试这个:
dict_df_all = pd.read_excel('test.xlsx', sheet_name=None, index_col=None, header=0)
for k, v in dict_df_all.items():
v['Year'] = k
df_all = pd.concat(dict_df_all, ignore_index=True)
-
然后另一个问题是工作簿的名称都不同,所有300个。是否有一个宏可以复制我打开的工作簿,而不是每次都输入实际的名称?
-
我对宏是新手,需要帮助。我在一个文件夹中有几个工作簿,每个工作簿有四个工作表。现在我想要一个mocro它复制数据从每个工作簿(工作表明智)和过去在我的主工作簿(工作表明智)意味着数据1应该被粘贴一个在另一个下面在我的主工作簿在工作表1和工作表2分别。*工作簿名称可以是文件夹中的任何东西。有人能帮我完成整个代码吗?我有宏从一张表到我分配的表的数据,但它复制粘贴数据从打开的表,而不是按表名明智的。有人
-
我有一个很大的电子表格文件(.xlsx),我正在使用python处理它。碰巧我需要那个大文件中两个选项卡(工作表)中的数据。其中一个选项卡包含大量数据,而另一个选项卡只有几个方形单元格。 当我使用,我觉得整个文件都已加载(不仅仅是我感兴趣的工作表)。因此,当我使用该方法两次(每张工作表一次)时,我实际上不得不忍受整个工作簿被读取两次(即使我们只使用指定的工作表)。 如何仅加载特定的工作表与?
-
所以在COL D中,我必须只粘贴COL A和COL C相等的值,如果这些值不相等,则跳过或粘贴COL D中的任何东西 我写过类似这样的代码,但不幸的是它粘贴了一切!!
-
问题内容: 刚开始使用pandas和python。 我有一个工作表,已读入数据框并应用了前向填充(ffill)方法。 然后,我想创建一个包含两个工作表的Excel文档。 在应用填充方法之前,一个工作表将在数据框中包含数据,而在下一个工作表将应用了填充方法的数据框。 最终,我打算为数据框的特定列中的每个数据唯一实例创建一个工作表。 然后,我想对结果应用某些vba格式-但我不确定哪个dll或插件,或者
-
2,3和6-12被跳过。下面是我的代码: 我认为这个问题与行“wb1.sheets(1).Range(”a“&Range(”a1“).end(xlDown).row+1)”有关,但我不知道如何解决这个问题。有什么建议吗?谢谢!