
7.9.实现广度优先搜索
通过构建图,我们现在可以将注意力转向我们将使用的算法来找到字梯问题的最短解。我们将使用的图算法称为“宽度优先搜索”算法。宽度优先搜索(BFS)是用于搜索图的最简单的算法之一。它也作为几个其他重要的图算法的原型,我们将在以后研究。
给定图 G 和起始顶点 s,广度优先搜索通过探索图中的边以找到 G 中的所有顶点,其中存在从 s 开始的路径。通过广度优先搜索,它找到和 s 相距 k 的所有顶点,然后找到距离为 k + 1 的所有顶点。可视化广度优先搜索算法一个好方法是想象它正在建一棵树,一次建一层。广度优先搜索先从其他起始顶点开始添加它的所有子节点,然后再添加其子节点的子节点。
为了跟踪进度,BFS 将每个顶点着色为白色,灰色或黑色。当它们被构造时,所有顶点被初始化为白色。白色顶点是未发现的顶点。当一个顶点最初被发现时它变成灰色的,当 BFS 完全探索完一个顶点时,它被着色为黑色。这意味着一旦顶点变黑色,就没有与它相邻的白色顶点。另一方面,灰色节点可能有与其相邻的一些白色顶点,表示仍有额外的顶点要探索。
下面 Listing 2 中所示的广度优先搜索算法使用我们先前开发的邻接表表示。此外,它使用一个 Queue,一个关键的地方,决定下一个探索的顶点。
此外,BFS 算法使用 Vertex 类的扩展版本。这个新的顶点类添加了三个新的实例变量:distance,predecessor和 color 。这些实例变量中的每一个还具有适当的 getter 和 setter 方法。这个扩展的顶点类代码包含在pythonds包中,但我们不会在这里展示它,因为没有新的需要学习的点。
BFS 从起始顶点开始,颜色从灰色开始,表明它正在被探索。另外两个值,即距离和前导,对于起始顶点分别初始化为 0 和 None 。最后,放到一个队列中。下一步是开始系统地检查队列前面的顶点。我们通过迭代它的邻接表来探索队列前面的每个新节点。当检查邻接表上的每个节点时,检查其颜色。如果它是白色的,顶点是未开发的,有四件事情发生:
- 新的,未开发的顶点 nbr,被着色为灰色。
- nbr 的前导被设置为当前节点
currentVert - 到 nbr 的距离设置为到
currentVert + 1的距离 - nbr 被添加到队列的末尾。 将 nbr 添加到队列的末尾有效地调度此节点以进行进一步探索,但不是直到
currentVert的邻接表上的所有其他顶点都被探索。
from pythonds.graphs import Graph, Vertex
from pythonds.basic import Queue
def bfs(g,start):
start.setDistance(0)
start.setPred(None)
vertQueue = Queue()
vertQueue.enqueue(start)
while (vertQueue.size() > 0):
currentVert = vertQueue.dequeue()
for nbr in currentVert.getConnections():
if (nbr.getColor() == 'white'):
nbr.setColor('gray')
nbr.setDistance(currentVert.getDistance() + 1)
nbr.setPred(currentVert)
vertQueue.enqueue(nbr)
currentVert.setColor('black')Listing 2
让我们看看 bfs 函数如何构造对应于 Figure 1 中的图的广度优先树。开始我们取所有与 fool 相邻的节点,并将它们添加到树中。 相邻节点包括 pool, foil, foul, cool。 这些节点被添加到新节点的队列以进行扩展。 Figure 3 展示了在此步骤之后树以及队列的状态。

Figure 3
在下一步骤中,bfs 从队列的前面删除下一个节点(pool),并对其所有相邻节点重复该过程。 然而,当 bfs 检查节点 cool 时,它发现 cool 的颜色已经改变为灰色。这表明有一条较短的路径到 cool,并且 cool 已经在队列上进一步扩展。在检查 pool 期间添加到队列的唯一新节点是 poll。 树和队列的新状态如 Figure 4所示。
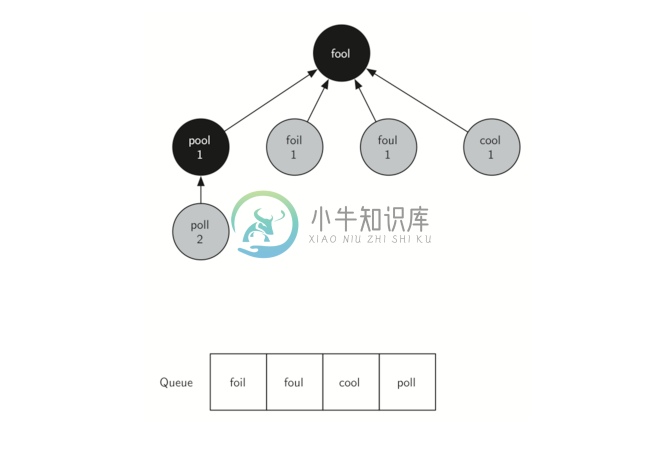
Figure 4
队列上的下一个顶点是 foil。 foil 可以添加到树中的唯一新节点是 fail。 当 bfs 继续处理队列时,接下来的两个节点都不向队列或树添加新内容。 Figure 5 展示了在树的第二级上展开所有顶点之后的树和队列。

Figure 5-6
你应该自己继续完成算法,以便能够熟练使用它。Figure 6 展示了在 Figure 3 中的所有顶点都被扩展之后的最终广度优先搜索树。关于广度优先搜索解决方案的令人惊讶的事情是,我们不仅解决了我们开始的 FOOL-SAGE 问题,还解决了许多其他问题。 我们可以从广度优先搜索树中的任何顶点开始,并沿着前导箭头回到根,找到从任何字回到 fool 的最短的词梯。 下面的函数(Listing 3)展示了如何按前导链接打印出字梯。
def traverse(y):
x = y
while (x.getPred()):
print(x.getId())
x = x.getPred()
print(x.getId())
traverse(g.getVertex('sage'))Listing 3