
python实现全排列代码(回溯、深度优先搜索)

从n个不同元素中任取m(m≤n)个元素,按照一定的顺序排列起来,叫做从n个不同元素中取出m个元素的一个排列。当m=n时所有的排列情况叫全排列。
公式:全排列数f(n)=n!(定义0!=1)
1 递归实现全排列(回溯思想)
1.1 思想
举个例子,比如你要对a,b,c三个字符进行全排列,那么它的全排列有abc,acb,bac,bca,cba,cab这六种可能就是当指针指向第一个元素a时,它可以是其本身a(即和自己进行交换),还可以和b,c进行交换,故有3种可能,当第一个元素a确定以后,指针移向第二位置,第二个位置可以和其本身b及其后的元素c进行交换,又可以形成两种排列,当指针指向第三个元素c的时候,这个时候其后没有元素了,此时,则确定了一组排列,输出。但是每次输出后要把数组恢复为原来的样子。
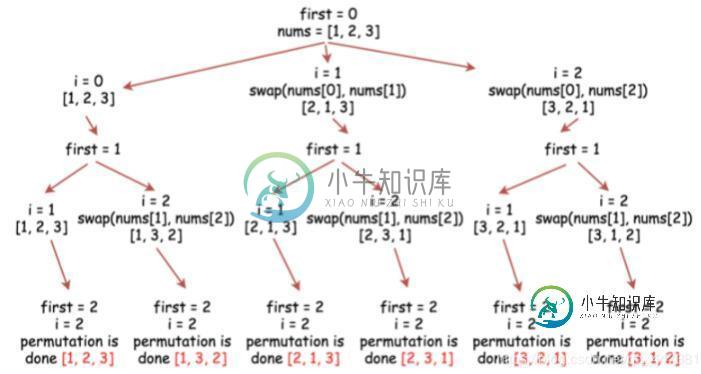
1.2 python实现
def permutations(arr, position, end):
if position == end:
print(arr)
else:
for index in range(position, end):
arr[index], arr[position] = arr[position], arr[index]
permutations(arr, position + 1, end)
arr[index], arr[position] = arr[position], arr[index] # 还原到交换前的状态,为了进行下一次交换
arr = [1, 2, 3, 4]
permutations(arr, 0, len(arr))
2 深度优先搜索(DFS)实现全排列
2.1 思想
定义全排列问题:输入一个长度为n的列表arr,输出arr的全排列。
(1)首先可以确定的是,每一种全排列的结果中包含的列表长度均是n。想象面前有n个空盒子,现在要把这n个数放到这些空盒子里去,每个盒子只能放一个数。那么第一个盒子中可以放的选择是n种,可以使用一个循环来逐个尝试。
for index in range(0, len(arr)):
temp[position] = arr[index]
(2)第一个盒子放完后,就该往第二个盒子里放了。假设第一个盒子里放的是arr的第一个数,那么第二个盒子就只能放第2~n个数了(不能重复)。为此引入visit列表用来标记arr中哪些数字被使用过了。初始化:
visit = [True, True, True, True]
这样,当第一个位置已经使用过时,就在visit里做标记:visit = [False, True, True, True]
因此放第一个盒子的代码可以改写如下:
for index in range(0, len(arr)):
if visit[index] == True:
temp[position] = arr[index]
visit[index] = False
(3)当第k个盒子处理完毕后,处理下一个盒子直接调用dfs(k+1)即可,也就是递归调用。解决了当下该如何做,下一步也就知道怎么做了。
(4)递归调用的一定要注意的问题是递归调用的出口,否则循环调用下去程序会崩溃无法运行。在这个问题中什么时候结束递归调用呢?答案是当这n个盒子都放满了,即处理到第n+1个盒子时结束调用,同时输出此时的排列结果。
2.2 python实现
visit = [True, True, True, True]
temp = ["" for x in range(0, 4)]
def dfs(position):
# 递归出口
if position == len(arr):
print(temp)
return
# 递归主体
for index in range(0, len(arr)):
if visit[index] == True:
temp[position] = arr[index]
visit[index] = False # 试探
dfs(position + 1)
visit[index] = True # 回溯。非常重要
arr = [1, 2, 3, 4]
dfs(0)
注释了“非常重要”的语句是不能省略的,省略后仅出现[1, 2, 3, 4]一条结果。dfs(k+1)前后的两条语句分别称之为试探和回溯。
3 combination和permutations函数的区别
permutations方法重在排列:
import itertools
n=3
a=[str(i) for i in range(n)]
s=""
s=s.join(a)
for i in itertools.permutations(s,n):
print (''.join(i))
# 结果
012
021
102
120
201
210
combinations方法重在组合:
import itertools
n=3
a=[str(i) for i in range(n)]
s=""
s=s.join(a)
for i in itertools.combinations(s,n):
print (''.join(i))
# 结果
012
以上这篇python实现全排列代码(回溯、深度优先搜索)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍C#深度优先遍历实现全排列,包括了C#深度优先遍历实现全排列的使用技巧和注意事项,需要的朋友参考一下 假如让你说出123三个数字的全排列你可以很快说出来123,132,213,231,312,321,但是让你说出1~20总共20个数字的全排列是不是就没那么简单了呢?本篇我们就通过C#运用深度优先算法实现全排列 算法图例 假如有编号为1,2,3的三张扑克牌和编号为1,2,3的三个盒子,
-
本文向大家介绍深度优先搜索,包括了深度优先搜索的使用技巧和注意事项,需要的朋友参考一下 图遍历是按某种系统顺序访问图的所有顶点的问题。遍历图主要有两种方法。 广度优先搜索 深度优先搜索 深度优先搜索(DFS)算法从顶点v开始,然后遍历到之前未访问过的相邻顶点(例如x),并将其标记为“已访问”,然后继续处理x的相邻顶点,依此类推。 如果在任何一个顶点上遇到所有相邻顶点都被访问过,则它将回溯直到找到具
-
主要内容:深度优先搜索(简称“深搜”或DFS),广度优先搜索,总结前边介绍了有关图的 4 种存储方式,本节介绍如何对存储的图中的顶点进行遍历。常用的遍历方式有两种: 深度优先搜索和 广度优先搜索。 深度优先搜索(简称“深搜”或DFS) 图 1 无向图 深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为: 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以
-
我对LeetCode988中的回溯解决方案和DFS解决方案感到困惑(从Leaf开始的最小字符串)。 如果使用StringBuilder实现,则需要这一行代码:,而使用String实现则不需要这一行。 有人能帮我解决困惑吗? 回溯(使用StringBuilder) DFS(使用字符串)
-
本文向大家介绍C++深度优先搜索的实现方法,包括了C++深度优先搜索的实现方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了图的遍历中深度优先搜索的C++实现方法,是一种非常重要的算法,具体实现方法如下: 首先,图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次。注意到树是一种特殊的图,所以树的遍历实际上也可以看作是一种特殊的图的遍历。图
-
3. 深度优先搜索 现在我们用堆栈解决一个有意思的问题,定义一个二维数组: int maze[5][5] = { 0, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0, 0, 0, 0, 1, 0, }; 它表示一个迷宫,其中的1表示墙壁,0表示可以走的路,只能横着走或竖着走,不能斜着走,要求编程序找出从左上角到右下角的路线