
2. 标准I/O库函数
2. 标准I/O库函数
2.1. 文件的基本概念
我们已经多次用到了文件,例如源文件、目标文件、可执行文件、库文件等,现在学习如何用C标准库对文件进行读写操作,对文件的读写也属于I/O操作的一种,本节介绍的大部分函数在头文件stdio.h中声明,称为标准I/O库函数。
文件可分为文本文件(Text File)和二进制文件(Binary File)两种,源文件是文本文件,而目标文件、可执行文件和库文件是二进制文件。文本文件是用来保存字符的,文件中的字节都是字符的某种编码(例如ASCII或UTF-8),用cat命令可以查看其中的字符,用vi可以编辑其中的字符,而二进制文件不是用来保存字符的,文件中的字节表示其它含义,例如可执行文件中有些字节表示指令,有些字节表示各Section和Segment在文件中的位置,有些字节表示各Segment的加载地址。
在第 5.1 节 “目标文件”中我们用hexdump命令查看过一个二进制文件。我们再做一个小实验,用vi编辑一个文件textfile,在其中输入5678然后保存退出,用ls -l命令可以看到它的长度是5:
$ ls -l textfile -rw-r--r-- 1 akaedu akaedu 5 2009-03-20 10:58 textfile
5678四个字符各占一个字节,vi会自动在文件末尾加一个换行符,所以文件长度是5。用od命令查看该文件的内容:
$ od -tx1 -tc -Ax textfile
000000 35 36 37 38 0a
5 6 7 8 \n
000005-tx1选项表示将文件中的字节以十六进制的形式列出来,每组一个字节,-tc选项表示将文件中的ASCII码以字符形式列出来。和hexdump类似,输出结果最左边的一列是文件中的地址,默认以八进制显示,-Ax选项要求以十六进制显示文件中的地址。这样我们看到,这个文件中保存了5个字符,以ASCII码保存。ASCII码的范围是0~127,所以ASCII码文本文件中每个字节只用到低7位,最高位都是0。以后我们会经常用到od命令。
文本文件是一个模糊的概念。有些时候说文本文件是指用vi可以编辑出来的文件,例如/etc目录下的各种配置文件,这些文件中只包含ASCII码中的可见字符,而不包含像'\0'这种不可见字符,也不包含最高位是1的非ASCII码字节。从广义上来说,只要是专门保存字符的文件都算文本文件,包含不可见字符的也算,采用其它字符编码(例如UTF-8编码)的也算。
2.2. fopen/fclose
在操作文件之前要用fopen打开文件,操作完毕要用fclose关闭文件。打开文件就是在操作系统中分配一些资源用于保存该文件的状态信息,并得到该文件的标识,以后用户程序就可以用这个标识对文件做各种操作,关闭文件则释放文件在操作系统中占用的资源,使文件的标识失效,用户程序就无法再操作这个文件了。
#include <stdio.h> FILE *fopen(const char *path, const char *mode); 返回值:成功返回文件指针,出错返回NULL并设置errno
path是文件的路径名,mode表示打开方式。如果文件打开成功,就返回一个FILE *文件指针来标识这个文件。以后调用其它函数对文件做读写操作都要提供这个指针,以指明对哪个文件进行操作。FILE是C标准库中定义的结构体类型,其中包含该文件在内核中标识(在第 2 节 “C标准I/O库函数与Unbuffered I/O函数”将会讲到这个标识叫做文件描述符)、I/O缓冲区和当前读写位置等信息,但调用者不必知道FILE结构体都有哪些成员,我们很快就会看到,调用者只是把文件指针在库函数接口之间传来传去,而文件指针所指的FILE结构体的成员在库函数内部维护,调用者不应该直接访问这些成员,这种编程思想在面向对象方法论中称为封装(Encapsulation)。像FILE *这样的指针称为不透明指针(Opaque Pointer)或者叫句柄(Handle),FILE *指针就像一个把手(Handle),抓住这个把手就可以打开门或抽屉,但用户只能抓这个把手,而不能直接抓门或抽屉。
下面说说参数path和mode,path可以是相对路径也可以是绝对路径,mode表示打开方式是读还是写。比如fp = fopen("/tmp/file2", "w");表示打开绝对路径/tmp/file2,只做写操作,path也可以是相对路径,比如fp = fopen("file.a", "r");表示在当前工作目录下打开文件file.a,只做读操作,再比如fp = fopen("../a.out", "r");只读打开当前工作目录上一层目录下的a.out,fp = fopen("Desktop/file3", "w");只写打开当前工作目录下子目录Desktop下的file3。相对路径是相对于当前工作目录(Current Working Directory)的路径,每个进程都有自己的当前工作目录,Shell进程的当前工作目录可以用pwd命令查看:
$ pwd /home/akaedu
通常Linux发行版都把Shell配置成在提示符前面显示当前工作目录,例如~$表示当前工作目录是主目录,/etc$表示当前工作目录是/etc。用cd命令可以改变Shell进程的当前工作目录。在Shell下敲命令启动新的进程,则该进程的当前工作目录继承自Shell进程的当前工作目录,该进程也可以调用chdir(2)函数改变自己的当前工作目录。
mode参数是一个字符串,由rwatb+六个字符组合而成,r表示读,w表示写,a表示追加(Append),在文件末尾追加数据使文件的尺寸增大。t表示文本文件,b表示二进制文件,有些操作系统的文本文件和二进制文件格式不同,而在UNIX系统中,无论文本文件还是二进制文件都是由一串字节组成,t和b没有区分,用哪个都一样,也可以省略不写。如果省略t和b,rwa+四个字符有以下6种合法的组合:
"r"只读,文件必须已存在
- "w"
只写,如果文件不存在则创建,如果文件已存在则把文件长度截断(Truncate)为0字节再重新写,也就是替换掉原来的文件内容
- "a"
只能在文件末尾追加数据,如果文件不存在则创建
- "r+"
允许读和写,文件必须已存在
- "w+"
允许读和写,如果文件不存在则创建,如果文件已存在则把文件长度截断为0字节再重新写
- "a+"
允许读和追加数据,如果文件不存在则创建
在打开一个文件时如果出错,fopen将返回NULL并设置errno,errno稍后介绍。在程序中应该做出错处理,通常这样写:
if ( (fp = fopen("/tmp/file1", "r")) == NULL) {
printf("error open file /tmp/file1!\n");
exit(1);
}比如/tmp/file1这个文件不存在,而r打开方式又不会创建这个文件,fopen就会出错返回。
再说说fclose函数。
#include <stdio.h> int fclose(FILE *fp); 返回值:成功返回0,出错返回EOF并设置errno
把文件指针传给fclose可以关闭它所标识的文件,关闭之后该文件指针就无效了,不能再使用了。如果fclose调用出错(比如传给它一个无效的文件指针)则返回EOF并设置errno,errno稍后介绍,EOF在stdio.h中定义:
/* End of file character. Some things throughout the library rely on this being -1. */ #ifndef EOF # define EOF (-1) #endif
它的值是-1。fopen调用应该和fclose调用配对,打开文件操作完之后一定要记得关闭。如果不调用fclose,在进程退出时系统会自动关闭文件,但是不能因此就忽略fclose调用,如果写一个长年累月运行的程序(比如网络服务器程序),打开的文件都不关闭,堆积得越来越多,就会占用越来越多的系统资源。
2.3. stdin/stdout/stderr
我们经常用printf打印到屏幕,也用过scanf读键盘输入,这些也属于I/O操作,但不是对文件做I/O操作而是对终端设备做I/O操作。所谓终端(Terminal)是指人机交互的设备,也就是可以接受用户输入并输出信息给用户的设备。在计算机刚诞生的年代,终端是电传打字机和打印机,现在的终端通常是键盘和显示器。终端设备和文件一样也需要先打开后操作,终端设备也有对应的路径名,/dev/tty就表示和当前进程相关联的终端设备(在第 1.1 节 “终端的基本概念”会讲到这叫进程的控制终端)。也就是说,/dev/tty不是一个普通的文件,它不表示磁盘上的一组数据,而是表示一个设备。用ls命令查看这个文件:
$ ls -l /dev/tty crw-rw-rw- 1 root dialout 5, 0 2009-03-20 19:31 /dev/tty
开头的c表示文件类型是字符设备。中间的5, 0是它的设备号,主设备号5,次设备号0,主设备号标识内核中的一个设备驱动程序,次设备号标识该设备驱动程序管理的一个设备。内核通过设备号找到相应的驱动程序,完成对该设备的操作。我们知道常规文件的这一列应该显示文件尺寸,而设备文件的这一列显示设备号,这表明设备文件是没有文件尺寸这个属性的,因为设备文件在磁盘上不保存数据,对设备文件做读写操作并不是读写磁盘上的数据,而是在读写设备。UNIX的传统是Everything is a file,键盘、显示器、串口、磁盘等设备在/dev目录下都有一个特殊的设备文件与之对应,这些设备文件也可以像普通文件一样打开、读、写和关闭,使用的函数接口是相同的。本书中不严格区分“文件”和“设备”这两个概念,遇到“文件”这个词,读者可以根据上下文理解它是指普通文件还是设备,如果需要强调是保存在磁盘上的普通文件,本书会用“常规文件”(Regular File)这个词。
那为什么printf和scanf不用打开就能对终端设备进行操作呢?因为在程序启动时(在main函数还没开始执行之前)会自动把终端设备打开三次,分别赋给三个FILE *指针stdin、stdout和stderr,这三个文件指针是libc中定义的全局变量,在stdio.h中声明,printf向stdout写,而scanf从stdin读,后面我们会看到,用户程序也可以直接使用这三个文件指针。这三个文件指针的打开方式都是可读可写的,但通常stdin只用于读操作,称为标准输入(Standard Input),stdout只用于写操作,称为标准输出(Standard Output),stderr也只用于写操作,称为标准错误输出(Standard Error),通常程序的运行结果打印到标准输出,而错误提示(例如gcc报的警告和错误)打印到标准错误输出,所以fopen的错误处理写成这样更符合惯例:
if ( (fp = fopen("/tmp/file1", "r")) == NULL) {
fputs("Error open file /tmp/file1\n", stderr);
exit(1);
}fputs函数将在稍后详细介绍。不管是打印到标准输出还是打印到标准错误输出效果是一样的,都是打印到终端设备(也就是屏幕)了,那为什么还要分成标准输出和标准错误输出呢?以后我们会讲到重定向操作,可以把标准输出重定向到一个常规文件,而标准错误输出仍然对应终端设备,这样就可以把正常的运行结果和错误提示分开,而不是混在一起打印到屏幕了。
2.4. errno与perror函数
很多系统函数在错误返回时将错误原因记录在libc定义的全局变量errno中,每种错误原因对应一个错误码,请查阅errno(3)的Man Page了解各种错误码,errno在头文件errno.h中声明,是一个整型变量,所有错误码都是正整数。
如果在程序中打印错误信息时直接打印errno变量,打印出来的只是一个整数值,仍然看不出是什么错误。比较好的办法是用perror或strerror函数将errno解释成字符串再打印。
#include <stdio.h> void perror(const char *s);
perror函数将错误信息打印到标准错误输出,首先打印参数s所指的字符串,然后打印:号,然后根据当前errno的值打印错误原因。例如:
例 25.4. perror
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE *fp = fopen("abcde", "r");
if (fp == NULL) {
perror("Open file abcde");
exit(1);
}
return 0;
}如果文件abcde不存在,fopen返回-1并设置errno为ENOENT,紧接着perror函数读取errno的值,将ENOENT解释成字符串No such file or directory并打印,最后打印的结果是Open file abcde: No such file or directory。虽然perror可以打印出错误原因,传给perror的字符串参数仍然应该提供一些额外的信息,以便在看到错误信息时能够很快定位是程序中哪里出了错,如果在程序中有很多个fopen调用,每个fopen打开不同的文件,那么在每个fopen的错误处理中打印文件名就很有帮助。
如果把上面的程序改成这样:
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
int main(void)
{
FILE *fp = fopen("abcde", "r");
if (fp == NULL) {
perror("Open file abcde");
printf("errno: %d\n", errno);
exit(1);
}
return 0;
}则printf打印的错误号并不是fopen产生的错误号,而是perror产生的错误号。errno是一个全局变量,很多系统函数都会改变它,fopen函数Man Page中的ERRORS部分描述了它可能产生的错误码,perror函数的Man Page中没有ERRORS部分,说明它本身不产生错误码,但它调用的其它函数也有可能改变errno变量。大多数系统函数都有一个Side Effect,就是有可能改变errno变量(当然也有少数例外,比如strcpy),所以一个系统函数错误返回后应该马上检查errno,在检查errno之前不能再调用其它系统函数。
strerror函数可以根据错误号返回错误原因字符串。
#include <string.h> char *strerror(int errnum); 返回值:错误码errnum所对应的字符串
这个函数返回指向静态内存的指针。以后学线程库时我们会看到,有些函数的错误码并不保存在errno中,而是通过返回值返回,就不能调用perror打印错误原因了,这时strerror就派上了用场:
fputs(strerror(n), stderr);
习题
1、在系统头文件中找到各种错误码的宏定义。
2、做几个小练习,看看fopen出错有哪些常见的原因。
打开一个没有访问权限的文件。
fp = fopen("/etc/shadow", "r");
if (fp == NULL) {
perror("Open /etc/shadow");
exit(1);
}fopen也可以打开一个目录,传给fopen的第一个参数目录名末尾可以加/也可以不加/,但只允许以只读方式打开。试试如果以可写的方式打开一个存在的目录会怎么样呢?
fp = fopen("/home/akaedu/", "r+");
if (fp == NULL) {
perror("Open /home/akaedu");
exit(1);
}请读者自己设计几个实验,看看你还能测试出哪些错误原因?
2.5. 以字节为单位的I/O函数
fgetc函数从指定的文件中读一个字节,getchar从标准输入读一个字节,调用getchar()相当于调用fgetc(stdin)。
#include <stdio.h> int fgetc(FILE *stream); int getchar(void); 返回值:成功返回读到的字节,出错或者读到文件末尾时返回EOF
注意在Man Page的函数原型中FILE *指针参数有时会起名叫stream,这是因为标准I/O库操作的文件有时也叫做流(Stream),文件由一串字节组成,每次可以读或写其中任意数量的字节,以后介绍TCP协议时会对流这个概念做更详细的解释。
对于fgetc函数的使用有以下几点说明:
要用
fgetc函数读一个文件,该文件的打开方式必须是可读的。系统对于每个打开的文件都记录着当前读写位置在文件中的地址(或者说距离文件开头的字节数),也叫偏移量(Offset)。当文件打开时,读写位置是0,每调用一次
fgetc,读写位置向后移动一个字节,因此可以连续多次调用fgetc函数依次读取多个字节。fgetc成功时返回读到一个字节,本来应该是unsigned char型的,但由于函数原型中返回值是int型,所以这个字节要转换成int型再返回,那为什么要规定返回值是int型呢?因为出错或读到文件末尾时fgetc将返回EOF,即-1,保存在int型的返回值中是0xffffffff,如果读到字节0xff,由unsigned char型转换为int型是0x000000ff,只有规定返回值是int型才能把这两种情况区分开,如果规定返回值是unsigned char型,那么当返回值是0xff时无法区分到底是EOF还是字节0xff。如果需要保存fgetc的返回值,一定要保存在int型变量中,如果写成unsigned char c = fgetc(fp);,那么根据c的值又无法区分EOF和0xff字节了。注意,fgetc读到文件末尾时返回EOF,只是用这个返回值表示已读到文件末尾,并不是说每个文件末尾都有一个字节是EOF(根据上面的分析,EOF并不是一个字节)。
fputc函数向指定的文件写一个字节,putchar向标准输出写一个字节,调用putchar(c)相当于调用fputc(c, stdout)。
#include <stdio.h> int fputc(int c, FILE *stream); int putchar(int c); 返回值:成功返回写入的字节,出错返回EOF
对于fputc函数的使用也要说明几点:
要用
fputc函数写一个文件,该文件的打开方式必须是可写的(包括追加)。每调用一次
fputc,读写位置向后移动一个字节,因此可以连续多次调用fputc函数依次写入多个字节。但如果文件是以追加方式打开的,每次调用fputc时总是将读写位置移到文件末尾然后把要写入的字节追加到后面。
下面的例子演示了这四个函数的用法,从键盘读入一串字符写到一个文件中,再从这个文件中读出这些字符打印到屏幕上。
例 25.5. 用fputc/fget读写文件和终端
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE *fp;
int ch;
if ( (fp = fopen("file2", "w+")) == NULL) {
perror("Open file file2\n");
exit(1);
}
while ( (ch = getchar()) != EOF)
fputc(ch, fp);
rewind(fp);
while ( (ch = fgetc(fp)) != EOF)
putchar(ch);
fclose(fp);
return 0;
}从终端设备读有点特殊。当调用getchar()或fgetc(stdin)时,如果用户没有输入字符,getchar函数就阻塞等待,所谓阻塞是指这个函数调用不返回,也就不能执行后面的代码,这个进程阻塞了,操作系统可以调度别的进程执行。从终端设备读还有一个特点,用户输入一般字符并不会使getchar函数返回,仍然阻塞着,只有当用户输入回车或者到达文件末尾时getchar才返回[34]。这个程序的执行过程分析如下:
$ ./a.out hello(输入hello并回车,这时第一次调用getchar返回,读取字符h存到文件中,然后连续调用getchar五次,读取ello和换行符存到文件中,第七次调用getchar又阻塞了) hey(输入hey并回车,第七次调用getchar返回,读取字符h存到文件中,然后连续调用getchar三次,读取ey和换行符存到文件中,第11次调用getchar又阻塞了) (这时输入Ctrl-D,第11次调用getchar返回EOF,跳出循环,进入下一个循环,回到文件开头,把文件内容一个字节一个字节读出来打印,直到文件结束) hello hey
从终端设备输入时有两种方法表示文件结束,一种方法是在一行的开头输入Ctrl-D(如果不在一行的开头则需要连续输入两次Ctrl-D),另一种方法是利用Shell的Heredoc语法:
$ ./a.out <<END > hello > hey > END hello hey
<<END表示从下一行开始是标准输入,直到某一行开头出现END时结束。<<后面的结束符可以任意指定,不一定得是END,只要和输入的内容能区分开就行。
在上面的程序中,第一个while循环结束时fp所指文件的读写位置在文件末尾,然后调用rewind函数把读写位置移到文件开头,再进入第二个while循环从头读取文件内容。
习题
1、编写一个简单的文件复制程序。
$ ./mycp dir1/fileA dir2/fileB
运行这个程序可以把dir1/fileA文件拷贝到dir2/fileB文件。注意各种出错处理。
2、虽然我说getchar要读到换行符才返回,但上面的程序并没有提供证据支持我的说法,如果看成每敲一个键getchar就返回一次,也能解释程序的运行结果。请写一个小程序证明getchar确实是读到换行符才返回的。
2.6. 操作读写位置的函数
我们在上一节的例子中看到rewind函数把读写位置移到文件开头,本节介绍另外两个操作读写位置的函数,fseek可以任意移动读写位置,ftell可以返回当前的读写位置。
#include <stdio.h> int fseek(FILE *stream, long offset, int whence); 返回值:成功返回0,出错返回-1并设置errno long ftell(FILE *stream); 返回值:成功返回当前读写位置,出错返回-1并设置errno void rewind(FILE *stream);
fseek的whence和offset参数共同决定了读写位置移动到何处,whence参数的含义如下:
SEEK_SET从文件开头移动
offset个字节SEEK_CUR从当前位置移动
offset个字节SEEK_END从文件末尾移动
offset个字节
offset可正可负,负值表示向前(向文件开头的方向)移动,正值表示向后(向文件末尾的方向)移动,如果向前移动的字节数超过了文件开头则出错返回,如果向后移动的字节数超过了文件末尾,再次写入时将增大文件尺寸,从原来的文件末尾到fseek移动之后的读写位置之间的字节都是0。
先前我们创建过一个文件textfile,其中有五个字节,5678加一个换行符,现在我们拿这个文件做实验。
例 25.6. fseek
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
FILE* fp;
if ( (fp = fopen("textfile","r+")) == NULL) {
perror("Open file textfile");
exit(1);
}
if (fseek(fp, 10, SEEK_SET) != 0) {
perror("Seek file textfile");
exit(1);
}
fputc('K', fp);
fclose(fp);
return 0;
}运行这个程序,然后查看文件textfile的内容:
$ ./a.out
$ od -tx1 -tc -Ax textfile
000000 35 36 37 38 0a 00 00 00 00 00 4b
5 6 7 8 \n \0 \0 \0 \0 \0 K
00000bfseek(fp, 10, SEEK_SET)将读写位置移到第10个字节处(其实是第11个字节,从0开始数),然后在该位置写入一个字符K,这样textfile文件就变长了,从第5到第9个字节自动被填充为0。
2.7. 以字符串为单位的I/O函数
fgets从指定的文件中读一行字符到调用者提供的缓冲区中,gets从标准输入读一行字符到调用者提供的缓冲区中。
#include <stdio.h> char *fgets(char *s, int size, FILE *stream); char *gets(char *s); 返回值:成功时s指向哪返回的指针就指向哪,出错或者读到文件末尾时返回NULL
gets函数无需解释,Man Page的BUGS部分已经说得很清楚了:Never use gets()。gets函数的存在只是为了兼容以前的程序,我们写的代码都不应该调用这个函数。gets函数的接口设计得很有问题,就像strcpy一样,用户提供一个缓冲区,却不能指定缓冲区的大小,很可能导致缓冲区溢出错误,这个函数比strcpy更加危险,strcpy的输入和输出都来自程序内部,只要程序员小心一点就可以避免出问题,而gets读取的输入直接来自程序外部,用户可能通过标准输入提供任意长的字符串,程序员无法避免gets函数导致的缓冲区溢出错误,所以唯一的办法就是不要用它。
现在说说fgets函数,参数s是缓冲区的首地址,size是缓冲区的长度,该函数从stream所指的文件中读取以'\n'结尾的一行(包括'\n'在内)存到缓冲区s中,并且在该行末尾添加一个'\0'组成完整的字符串。
如果文件中的一行太长,fgets从文件中读了size-1个字符还没有读到'\n',就把已经读到的size-1个字符和一个'\0'字符存入缓冲区,文件中剩下的半行可以在下次调用fgets时继续读。
如果一次fgets调用在读入若干个字符后到达文件末尾,则将已读到的字符串加上'\0'存入缓冲区并返回,如果再次调用fgets则返回NULL,可以据此判断是否读到文件末尾。
注意,对于fgets来说,'\n'是一个特别的字符,而'\0'并无任何特别之处,如果读到'\0'就当作普通字符读入。如果文件中存在'\0'字符(或者说0x00字节),调用fgets之后就无法判断缓冲区中的'\0'究竟是从文件读上来的字符还是由fgets自动添加的结束符,所以fgets只适合读文本文件而不适合读二进制文件,并且文本文件中的所有字符都应该是可见字符,不能有'\0'。
fputs向指定的文件写入一个字符串,puts向标准输出写入一个字符串。
#include <stdio.h> int fputs(const char *s, FILE *stream); int puts(const char *s); 返回值:成功返回一个非负整数,出错返回EOF
缓冲区s中保存的是以'\0'结尾的字符串,fputs将该字符串写入文件stream,但并不写入结尾的'\0'。与fgets不同的是,fputs并不关心的字符串中的'\n'字符,字符串中可以有'\n'也可以没有'\n'。puts将字符串s写到标准输出(不包括结尾的'\0'),然后自动写一个'\n'到标准输出。
习题
1、用fgets/fputs写一个拷贝文件的程序,根据本节对fgets函数的分析,应该只能拷贝文本文件,试试用它拷贝二进制文件会出什么问题。
2.8. 以记录为单位的I/O函数
#include <stdio.h> size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream); size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream); 返回值:读或写的记录数,成功时返回的记录数等于nmemb,出错或读到文件末尾时返回的记录数小于nmemb,也可能返回0
fread和fwrite用于读写记录,这里的记录是指一串固定长度的字节,比如一个int、一个结构体或者一个定长数组。参数size指出一条记录的长度,而nmemb指出要读或写多少条记录,这些记录在ptr所指的内存空间中连续存放,共占size * nmemb个字节,fread从文件stream中读出size * nmemb个字节保存到ptr中,而fwrite把ptr中的size * nmemb个字节写到文件stream中。
nmemb是请求读或写的记录数,fread和fwrite返回的记录数有可能小于nmemb指定的记录数。例如当前读写位置距文件末尾只有一条记录的长度,调用fread时指定nmemb为2,则返回值为1。如果当前读写位置已经在文件末尾了,或者读文件时出错了,则fread返回0。如果写文件时出错了,则fwrite的返回值小于nmemb指定的值。下面的例子由两个程序组成,一个程序把结构体保存到文件中,另一个程序和从文件中读出结构体。
例 25.7. fread/fwrite
/* writerec.c */
#include <stdio.h>
#include <stdlib.h>
struct record {
char name[10];
int age;
};
int main(void)
{
struct record array[2] = {{"Ken", 24}, {"Knuth", 28}};
FILE *fp = fopen("recfile", "w");
if (fp == NULL) {
perror("Open file recfile");
exit(1);
}
fwrite(array, sizeof(struct record), 2, fp);
fclose(fp);
return 0;
}/* readrec.c */
#include <stdio.h>
#include <stdlib.h>
struct record {
char name[10];
int age;
};
int main(void)
{
struct record array[2];
FILE *fp = fopen("recfile", "r");
if (fp == NULL) {
perror("Open file recfile");
exit(1);
}
fread(array, sizeof(struct record), 2, fp);
printf("Name1: %s\tAge1: %d\n", array[0].name, array[0].age);
printf("Name2: %s\tAge2: %d\n", array[1].name, array[1].age);
fclose(fp);
return 0;
}$ gcc writerec.c -o writerec
$ gcc readrec.c -o readrec
$ ./writerec
$ od -tx1 -tc -Ax recfile
000000 4b 65 6e 00 00 00 00 00 00 00 00 00 18 00 00 00
K e n \0 \0 \0 \0 \0 \0 \0 \0 \0 030 \0 \0 \0
000010 4b 6e 75 74 68 00 00 00 00 00 00 00 1c 00 00 00
K n u t h \0 \0 \0 \0 \0 \0 \0 034 \0 \0 \0
000020
$ ./readrec
Name1: Ken Age1: 24
Name2: Knuth Age2: 28我们把一个struct record结构体看作一条记录,由于结构体中有填充字节,每条记录占16字节,把两条记录写到文件中共占32字节。该程序生成的recfile文件是二进制文件而非文本文件,因为其中不仅保存着字符型数据,还保存着整型数据24和28(在od命令的输出中以八进制显示为030和034)。注意,直接在文件中读写结构体的程序是不可移植的,如果在一种平台上编译运行writebin.c程序,把生成的recfile文件拷到另一种平台并在该平台上编译运行readbin.c程序,则不能保证正确读出文件的内容,因为不同平台的大小端可能不同(因而对整型数据的存储方式不同),结构体的填充方式也可能不同(因而同一个结构体所占的字节数可能不同,age成员在name成员之后的什么位置也可能不同)。
2.9. 格式化I/O函数
现在该正式讲一下printf和scanf函数了,这两个函数都有很多种形式。
#include <stdio.h> int printf(const char *format, ...); int fprintf(FILE *stream, const char *format, ...); int sprintf(char *str, const char *format, ...); int snprintf(char *str, size_t size, const char *format, ...); #include <stdarg.h> int vprintf(const char *format, va_list ap); int vfprintf(FILE *stream, const char *format, va_list ap); int vsprintf(char *str, const char *format, va_list ap); int vsnprintf(char *str, size_t size, const char *format, va_list ap); 返回值:成功返回格式化输出的字节数(不包括字符串的结尾'\0'),出错返回一个负值
printf格式化打印到标准输出,而fprintf打印到指定的文件stream中。sprintf并不打印到文件,而是打印到用户提供的缓冲区str中并在末尾加'\0',由于格式化后的字符串长度很难预计,所以很可能造成缓冲区溢出,用snprintf更好一些,参数size指定了缓冲区长度,如果格式化后的字符串长度超过缓冲区长度,snprintf就把字符串截断到size-1字节,再加上一个'\0'写入缓冲区,也就是说snprintf保证字符串以'\0'结尾。snprintf的返回值是格式化后的字符串长度(不包括结尾的'\0'),如果字符串被截断,返回的是截断之前的长度,把它和实际缓冲区中的字符串长度相比较就可以知道是否发生了截断。
上面列出的后四个函数在前四个函数名的前面多了个v,表示可变参数不是以...的形式传进来,而是以va_list类型传进来。下面我们用vsnprintf包装出一个类似printf的带格式化字符串和可变参数的函数。
例 25.8. 实现格式化打印错误的err_sys函数
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <stdarg.h>
#include <string.h>
#define MAXLINE 80
void err_sys(const char *fmt, ...)
{
int err = errno;
char buf[MAXLINE+1];
va_list ap;
va_start(ap, fmt);
vsnprintf(buf, MAXLINE, fmt, ap);
snprintf(buf+strlen(buf), MAXLINE-strlen(buf), ": %s", strerror(err));
strcat(buf, "\n");
fputs(buf, stderr);
va_end(ap);
exit(1);
}
int main(int argc, char *argv[])
{
FILE *fp;
if (argc != 2) {
fputs("Usage: ./a.out pathname\n", stderr);
exit(1);
}
fp = fopen(argv[1], "r");
if (fp == NULL)
err_sys("Line %d - Open file %s", __LINE__, argv[1]);
printf("Open %s OK\n", argv[1]);
fclose(fp);
return 0;
}有了err_sys函数,不仅简化了main函数的代码,而且可以把fopen的错误提示打印得非常清楚,有源代码行号,有打开文件的路径名,一看就知道哪里出错了。
现在总结一下printf格式化字符串中的转换说明的有哪些写法。在这里只列举几种常用的格式,其它格式请参考Man Page。每个转换说明以%号开头,以转换字符结尾,我们以前用过的转换说明仅包含%号和转换字符,例如%d、%s,其实在这两个字符中间还可以插入一些可选项。
表 25.1. printf转换说明的可选项
| 选项 | 描述 | 举例 |
|---|---|---|
| # | 八进制前面加0(转换字符为o),十六进制前面加0x(转换字符为x)或0X(转换字符为X)。 | printf("%#x", 0xff)打印0xff,printf("%x", 0xff)打印ff。 |
| - | 格式化后的内容居左,右边可以留空格。 | 见下面的例子 |
| 宽度 | 用一个整数指定格式化后的最小长度,如果格式化后的内容没有这么长,可以在左边留空格,如果前面指定了-号就在右边留空格。宽度有一种特别的形式,不指定整数值而是写成一个*号,表示取一个int型参数作为宽度。 | printf("-%10s-", "hello")打印-␣␣␣␣␣hello-,printf("-%-*s-", 10, "hello")打印-hello␣␣␣␣␣-。 |
| . | 用于分隔上一条提到的最小长度和下一条要讲的精度。 | 见下面的例子 |
| 精度 | 用一个整数表示精度,对于字符串来说指定了格式化后保留的最大长度,对于浮点数来说指定了格式化后小数点右边的位数,对于整数来说指定了格式化后的最小位数。精度也可以不指定整数值而是写成一个*号,表示取下一个int型参数作为精度。 | printf("%.4s", "hello")打印hell,printf("-%6.4d-", 100)打印-␣␣0100-,printf("-%*.*f-", 8, 4, 3.14)打印-␣␣3.1400-。 |
| 字长 | 对于整型参数,hh、h、l、ll分别表示是char、short、long、long long型的字长,至于是有符号数还是无符号数则取决于转换字符;对于浮点型参数,L表示long double型的字长。 | printf("%hhd", 255)打印-1。 |
常用的转换字符有:
表 25.2. printf的转换字符
| 转换字符 | 描述 | 举例 |
|---|---|---|
| d i | 取int型参数格式化成有符号十进制表示,如果格式化后的位数小于指定的精度,就在左边补0。 | printf("%.4d", 100)打印0100。 |
| o u x X | 取unsigned int型参数格式化成无符号八进制(o)、十进制(u)、十六进制(x或X)表示,x表示十六进制数字用小写abcdef,X表示十六进制数字用大写ABCDEF,如果格式化后的位数小于指定的精度,就在左边补0。 | printf("%#X", 0xdeadbeef)打印0XDEADBEEF,printf("%hhu", -1)打印255。 |
| c | 取int型参数转换成unsigned char型,格式化成对应的ASCII码字符。 | printf("%c", 256+'A')打印A。 |
| s | 取const char *型参数所指向的字符串格式化输出,遇到'\0'结束,或者达到指定的最大长度(精度)结束。 | printf("%.4s", "hello")打印hell。 |
| p | 取void *型参数格式化成十六进制表示。相当于%#x。 | printf("%p", main)打印main函数的首地址0x80483c4。 |
| f | 取double型参数格式化成[-]ddd.ddd这样的格式,小数点后的默认精度是6位。 | printf("%f", 3.14)打印3.140000,printf("%f", 0.00000314)打印0.000003。 |
| e E | 取double型参数格式化成[-]d.ddde±dd(转换字符是e)或[-]d.dddE±dd(转换字符是E)这样的格式,小数点后的默认精度是6位,指数至少是两位。 | printf("%e", 3.14)打印3.140000e+00。 |
| g G | 取double型参数格式化,精度是指有效数字而非小数点后的数字,默认精度是6。如果指数小于-4或大于等于精度就按%e(转换字符是g)或%E(转换字符是G)格式化,否则按%f格式化。小数部分的末尾0去掉,如果没有小数部分,小数点也去掉。 | printf("%g", 3.00)打印3,printf("%g", 0.00001234567)打印1.23457e-05。 |
| % | 格式化成一个%。 | printf("%%")打印一个%。 |
我们在第 6 节 “可变参数”讲过可变参数的原理,printf并不知道实际参数的类型,只能按转换说明指出的参数类型从栈帧上取参数,所以如果实际参数和转换说明的类型不符,结果可能会有些意外,上面也举过几个这样的例子。另外,如果s指向一个字符串,用printf(s)打印这个字符串可能得到错误的结果,因为字符串中可能包含%号而被printf当成转换说明,printf并不知道后面没有传其它参数,照样会从栈帧上取参数。所以比较保险的办法是printf("%s", s)。
下面看scanf函数的各种形式。
#include <stdio.h> int scanf(const char *format, ...); int fscanf(FILE *stream, const char *format, ...); int sscanf(const char *str, const char *format, ...); #include <stdarg.h> int vscanf(const char *format, va_list ap); int vsscanf(const char *str, const char *format, va_list ap); int vfscanf(FILE *stream, const char *format, va_list ap); 返回值:返回成功匹配和赋值的参数个数,成功匹配的参数可能少于所提供的赋值参数,返回0表示一个都不匹配,出错或者读到文件或字符串末尾时返回EOF并设置errno
scanf从标准输入读字符,按格式化字符串format中的转换说明解释这些字符,转换后赋给后面的参数,后面的参数都是传出参数,因此必须传地址而不能传值。fscanf从指定的文件stream中读字符,而sscanf从指定的字符串str中读字符。后面三个以v开头的函数的可变参数不是以...的形式传进来,而是以va_list类型传进来。
现在总结一下scanf的格式化字符串和转换说明,这里也只列举几种常用的格式,其它格式请参考Man Page。scanf用输入的字符去匹配格式化字符串中的字符和转换说明,如果成功匹配一个转换说明,就给一个参数赋值,如果读到文件或字符串末尾就停止,或者如果遇到和格式化字符串不匹配的地方(比如转换说明是%d却读到字符A)就停止。如果遇到不匹配的地方而停止,scanf的返回值可能小于赋值参数的个数,文件的读写位置指向输入中不匹配的地方,下次调用库函数读文件时可以从这个位置继续。
格式化字符串中包括:
空格或Tab,在处理过程中被忽略。
普通字符(不包括
%),和输入字符中的非空白字符相匹配。输入字符中的空白字符是指空格、Tab、\r、\n、\v、\f。转换说明,以
%开头,以转换字符结尾,中间也有若干个可选项。
转换说明中的可选项有:
*号,表示这个转换说明只是用来匹配一段输入字符,但匹配结果并不赋给后面的参数。用一个整数指定的宽度N。表示这个转换说明最多匹配N个输入字符,或者匹配到输入字符中的下一个空白字符结束。
对于整型参数可以指定字长,有
hh、h、l、ll(也可以写成一个L),含义和printf相同。但l和L还有一层含义,当转换字符是e、f、g时,表示赋值参数的类型是float *而非double *,这一点跟printf不同(结合以前讲的类型转换规则思考一下为什么不同),这时前面加上l或L分别表示double *或long double *型。
常用的转换字符有:
表 25.3. scanf的转换字符
| 转换字符 | 描述 |
|---|---|
| d | 匹配十进制整数(开头可以有负号),赋值参数的类型是int *。 |
| i | 匹配整数(开头可以有负号),赋值参数的类型是int *,如果输入字符以0x或0X开头则匹配十六进制整数,如果输入字符以0开头则匹配八进制整数。 |
| o u x | 匹配八进制、十进制、十六进制整数(开头可以有负号),赋值参数的类型是unsigned int *。 |
| c | 匹配一串字符,字符的个数由宽度指定,缺省宽度是1,赋值参数的类型是char *,末尾不会添加'\0'。如果输入字符的开头有空白字符,这些空白字符并不被忽略,而是保存到参数中,要想跳过开头的空白字符,可以在格式化字符串中用一个空格去匹配。 |
| s | 匹配一串非空白字符,从输入字符中的第一个非空白字符开始匹配到下一个空白字符之前,或者匹配到指定的宽度,赋值参数的类型是char *,末尾自动添加'\0'。 |
| e f g | 匹配符点数(开头可以有负号),赋值参数的类型是float *,也可以指定double *或long double *的字长。 |
| % | 转换说明%%匹配一个字符%,不做赋值。 |
下面几个例子出自[K&R]。第一个例子,读取用户输入的浮点数累加起来。
例 25.9. 用scanf实现简单的计算器
#include <stdio.h>
int main(void) /* rudimentary calculator */
{
double sum, v;
sum = 0;
while (scanf("%lf", &v) == 1)
printf("\t%.2f\n", sum += v);
return 0;
}如果我们要读取25 Dec 1988这样的日期格式,可以这样写:
char *str = "25 Dec 1988"; int day, year; char monthname[20]; sscanf(str, "%d %s %d", &day, monthname, &year);
如果str中的空白字符再多一些,比如" 25 Dec 1998",仍然可以正确读取。如果格式化字符串中的空格和Tab再多一些,比如"%d %s %d ",也可以正确读取。scanf函数是很强大的,但是要用对了不容易,需要多练习,通过练习体会空白字符的作用。
如果要读取12/25/1998这样的日期格式,就需要在格式化字符串中用/匹配输入字符中的/:
int day, month, year;
scanf("%d/%d/%d", &month, &day, &year);scanf把换行符也看作空白字符,仅仅当作字段之间的分隔符,如果输入中的字段个数不确定,最好是先用fgets按行读取,然后再交给sscanf处理。如果我们的程序需要同时识别以上两种日期格式,可以这样写:
while (fgets(line, sizeof(line), stdin) > 0) {
if (sscanf(line, "%d %s %d", &day, monthname, &year) == 3)
printf("valid: %s\n", line); /* 25 Dec 1988 form */
else if (sscanf(line, "%d/%d/%d", &month, &day, &year) == 3)
printf("valid: %s\n", line); /* mm/dd/yy form */
else
printf("invalid: %s\n", line); /* invalid form */
}2.10. C标准库的I/O缓冲区
用户程序调用C标准I/O库函数读写文件或设备,而这些库函数要通过系统调用把读写请求传给内核(以后我们会看到与I/O相关的系统调用),最终由内核驱动磁盘或设备完成I/O操作。C标准库为每个打开的文件分配一个I/O缓冲区以加速读写操作,通过文件的FILE结构体可以找到这个缓冲区,用户调用读写函数大多数时候都在I/O缓冲区中读写,只有少数时候需要把读写请求传给内核。以fgetc/fputc为例,当用户程序第一次调用fgetc读一个字节时,fgetc函数可能通过系统调用进入内核读1K字节到I/O缓冲区中,然后返回I/O缓冲区中的第一个字节给用户,把读写位置指向I/O缓冲区中的第二个字符,以后用户再调fgetc,就直接从I/O缓冲区中读取,而不需要进内核了,当用户把这1K字节都读完之后,再次调用fgetc时,fgetc函数会再次进入内核读1K字节到I/O缓冲区中。在这个场景中用户程序、C标准库和内核之间的关系就像在第 5 节 “Memory Hierarchy”中CPU、Cache和内存之间的关系一样,C标准库之所以会从内核预读一些数据放在I/O缓冲区中,是希望用户程序随后要用到这些数据,C标准库的I/O缓冲区也在用户空间,直接从用户空间读取数据比进内核读数据要快得多。另一方面,用户程序调用fputc通常只是写到I/O缓冲区中,这样fputc函数可以很快地返回,如果I/O缓冲区写满了,fputc就通过系统调用把I/O缓冲区中的数据传给内核,内核最终把数据写回磁盘。有时候用户程序希望把I/O缓冲区中的数据立刻传给内核,让内核写回设备,这称为Flush操作,对应的库函数是fflush,fclose函数在关闭文件之前也会做Flush操作。
下图以fgets/fputs示意了I/O缓冲区的作用,使用fgets/fputs函数时在用户程序中也需要分配缓冲区(图中的buf1和buf2),注意区分用户程序的缓冲区和C标准库的I/O缓冲区。
图 25.1. C标准库的I/O缓冲区
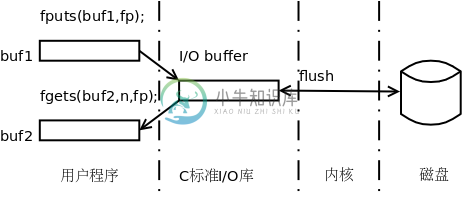
C标准库的I/O缓冲区有三种类型:全缓冲、行缓冲和无缓冲。当用户程序调用库函数做写操作时,不同类型的缓冲区具有不同的特性。
- 全缓冲
如果缓冲区写满了就写回内核。常规文件通常是全缓冲的。
- 行缓冲
如果用户程序写的数据中有换行符就把这一行写回内核,或者如果缓冲区写满了就写回内核。标准输入和标准输出对应终端设备时通常是行缓冲的。
- 无缓冲
用户程序每次调库函数做写操作都要通过系统调用写回内核。标准错误输出通常是无缓冲的,这样用户程序产生的错误信息可以尽快输出到设备。
下面通过一个简单的例子证明标准输出对应终端设备时是行缓冲的。
#include <stdio.h>
int main()
{
printf("hello world");
while(1);
return 0;
}运行这个程序,会发现hello world并没有打印到屏幕上。用Ctrl-C终止它,去掉程序中的while(1);语句再试一次:
$ ./a.out hello world$
hello world被打印到屏幕上,后面直接跟Shell提示符,中间没有换行。
我们知道main函数被启动代码这样调用:exit(main(argc, argv));。main函数return时启动代码会调用exit,exit函数首先关闭所有尚未关闭的FILE *指针(关闭之前要做Flush操作),然后通过_exit系统调用进入内核退出当前进程[35]。
在上面的例子中,由于标准输出是行缓冲的,printf("hello world");打印的字符串中没有换行符,所以只把字符串写到标准输出的I/O缓冲区中而没有写回内核(写到终端设备),如果敲Ctrl-C,进程是异常终止的,并没有调用exit,也就没有机会Flush I/O缓冲区,因此字符串最终没有打印到屏幕上。如果把打印语句改成printf("hello world\n");,有换行符,就会立刻写到终端设备,或者如果把while(1);去掉也可以写到终端设备,因为程序退出时会调用exitFlush所有I/O缓冲区。在本书的其它例子中,printf打印的字符串末尾都有换行符,以保证字符串在printf调用结束时就写到终端设备。
我们再做个实验,在程序中直接调用_exit退出。
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("hello world");
_exit(0);
}结果也不会把字符串打印到屏幕上,如果把_exit调用改成exit就可以打印到屏幕上。
除了写满缓冲区、写入换行符之外,行缓冲还有一种情况会自动做Flush操作。如果:
用户程序调用库函数从无缓冲的文件中读取
或者从行缓冲的文件中读取,并且这次读操作会引发系统调用从内核读取数据
那么在读取之前会自动Flush所有行缓冲。例如:
#include <stdio.h>
#include <unistd.h>
int main()
{
char buf[20];
printf("Please input a line: ");
fgets(buf, 20, stdin);
return 0;
}虽然调用printf并不会把字符串写到设备,但紧接着调用fgets读一个行缓冲的文件(标准输入),在读取之前会自动Flush所有行缓冲,包括标准输出。
如果用户程序不想完全依赖于自动的Flush操作,可以调fflush函数手动做Flush操作。
#include <stdio.h> int fflush(FILE *stream); 返回值:成功返回0,出错返回EOF并设置errno
对前面的例子再稍加改动:
#include <stdio.h>
int main()
{
printf("hello world");
fflush(stdout);
while(1);
}虽然字符串中没有换行,但用户程序调用fflush强制写回内核,因此也能在屏幕上打印出字符串。fflush函数用于确保数据写回了内核,以免进程异常终止时丢失数据。作为一个特例,调用fflush(NULL)可以对所有打开文件的I/O缓冲区做Flush操作。
2.11. 本节综合练习
1、编程读写一个文件test.txt,每隔1秒向文件中写入一行记录,类似于这样:
1 2009-7-30 15:16:42 2 2009-7-30 15:16:43
该程序应该无限循环,直到按Ctrl-C终止。下次再启动程序时在test.txt文件末尾追加记录,并且序号能够接续上次的序号,比如:
1 2009-7-30 15:16:42 2 2009-7-30 15:16:43 3 2009-7-30 15:19:02 4 2009-7-30 15:19:03 5 2009-7-30 15:19:04
这类似于很多系统服务维护的日志文件,例如在我的机器上系统服务进程acpid维护一个日志文件/var/log/acpid,就像这样:
$ cat /var/log/acpid [Sun Oct 26 08:44:46 2008] logfile reopened [Sun Oct 26 10:11:53 2008] exiting [Sun Oct 26 18:54:39 2008] starting up ...
每次系统启动时acpid进程就以追加方式打开这个文件,当有事件发生时就追加一条记录,包括事件发生的时刻以及事件描述信息。
获取当前的系统时间需要调用time(2)函数,返回的结果是一个time_t类型,其实就是一个大整数,其值表示从UTC(Coordinated Universal Time)时间1970年1月1日00:00:00(称为UNIX系统的Epoch时间)到当前时刻的秒数。然后调用localtime(3)将time_t所表示的UTC时间转换为本地时间(我们是+8区,比UTC多8个小时)并转成struct tm类型,该类型的各数据成员分别表示年月日时分秒,具体用法请查阅Man Page。调用sleep(3)函数可以指定程序睡眠多少秒。
2、INI文件是一种很常见的配置文件,很多Windows程序都采用这种格式的配置文件,在Linux系统中Qt程序通常也采用这种格式的配置文件。比如:
;Configuration of http [http] domain=www.mysite.com port=8080 cgihome=/cgi-bin ;Configuration of db [database] server = mysql user = myname password = toopendatabase
一个配置文件由若干个Section组成,由[]括号括起来的是Section名。每个Section下面有若干个key = value形式的键值对(Key-value Pair),等号两边可以有零个或多个空白字符(空格或Tab),每个键值对占一行。以;号开头的行是注释。每个Section结束时有一个或多个空行,空行是仅包含零个或多个空白字符(空格或Tab)的行。INI文件的最后一行后面可能有换行符也可能没有。
现在XML兴起了,INI文件显得有点土。现在要求编程把INI文件转换成XML文件。上面的例子经转换后应该变成这样:
<!-- Configuration of http -->
<http>
<domain>www.mysite.com</domain>
<port>8080</port>
<cgihome>/cgi-bin</cgihome>
</http>
<!-- Configuration of db -->
<database>
<server>mysql</server>
<user>myname</user>
<password>toopendatabase</password>
</database>3、实现类似gcc的-M选项的功能,给定一个.c文件,列出它直接和间接包含的所有头文件,例如有一个main.c文件:
#include <errno.h>
#include "stack.h"
int main()
{
return 0;
}你的程序读取这个文件,打印出其中包含的所有头文件的绝对路径:
$ ./a.out main.c /usr/include/errno.h /usr/include/features.h /usr/include/bits/errno.h /usr/include/linux/errno.h ... /home/akaedu/stack.h: cannot find
如果有的头文件找不到,就像上面例子那样打印/home/akaedu/stack.h: cannot find。首先复习一下第 2.2 节 “头文件”讲过的头文件查找顺序,本题目不必考虑-I选项指定的目录,只在.c文件所在的目录以及系统目录/usr/include中查找。
[34] 这些特性取决于终端的工作模式,终端可以配置成一次一行的模式,也可以配置成一次一个字符的模式,默认是一次一行的模式(本书的实验都是在这种模式下做的),关于终端的配置可参考[APUE2e]。
[35] 其实在调_exit进内核之前还要调用户程序中通过atexit(3)注册的退出处理函数,本书不做详细介绍,读者可参考[APUE2e]。