
Slony-I可以来实现PostgreSQL数据库的主从复制。
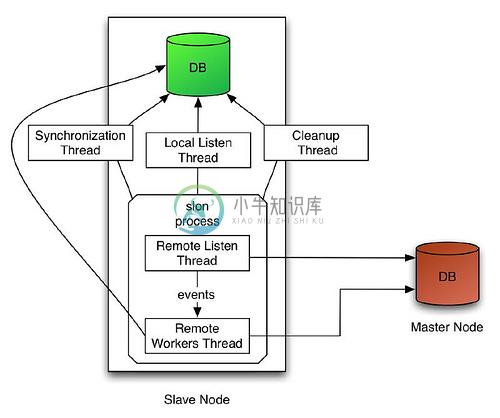
下面是Slony-I 的安装配置简明指南,实现主副数据库的同步。后面我会再介绍Pgbouncer的安装和配置
1. 主副数据库机器
Master:
hostname: M_DB
inet addr:10.0.0.11
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 254772 kB
PgSQL: postgresql-8.3.0
Slave:
hostname:S_DB
inet addr:10.0.0.12
OS: Linux 2.6.9-42.ELsmp
CPU:Intel(R) Xeon(R) CPU L5320 @ 1.86GHz
MemTotal: 514440 kB
PgSQL: postgresql-8.3.0
#在M_DB和S_DB上安装postgresql-8.3.0, 安装和配置过程参见我的上一篇Blog,确保超级用户是postgres,数据库名是URT。
#检查M_DB和S_DB上的超级用户postgres是否可以访问对方的机器
#分别在M_DB和S_DB上执行
sudo -u postgres /home/y/pgsql/bin/createlang plpgsql URT
#分别在M_DB和S_DB上的URT数据库里创建相同的表accounts。
2. 安装Slony-I
#分别在M_DB和S_DB上安装Slony-I
tar xfj slony1-1.2.13.tar.bz2
cd slony1-1.2.13
./configure –with-pgconfigdir=/home/y/pgsql/bin
gmake all
sudo gmake install
3. Slony Config
创建urt_replica_init.sh文件:
##############################
#!/bin/sh
SLONIK=/home/y/pgsql/bin/slonik
#slonik可执行文件位置
CLUSTER=URT
#你的集群的名称
SET_ID=1
#你的复制集的名称
MASTER=1
#主服务器ID
HOST1=M_DB
#源库IP或主机名
DBNAME1=URT
#需要复制的源数据库
SLONY_USER=postgres
#源库数据库超级用户名
SLAVE=2
#从服务器ID
HOST2=S_DB
#目的库IP或主机名
DBNAME2=URT
#需要复制的目的数据库
PGBENCH_USER=postgres
#目的库用户名
$SLONIK <<_EOF_
#这句是定义集群名
cluster name = $CLUSTER;
#这两句是定义复制节点
node $MASTER admin conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER ';
node $SLAVE admin conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ';
#初始化集群和主节点,id从1开始,如果只有一个集群,那么肯定是1
#comment里可以写一些自己的注释,随意
init cluster ( id = $MASTER, comment = 'Primary Node' );
#下面是从节点
store node ( id = $SLAVE, comment = 'Slave Node' );
#配置主从两个节点的连接信息,就是告诉Slave服务器如何来访问Master服务器
#下面是主节点的连接参数
store path ( server = $MASTER, client = $SLAVE,
conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER ');
#下面是从节点的连接参数
store path ( server = $SLAVE, client = $MASTER,
conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ');
#设置复制中角色,主节点是原始提供者,从节点是接受者
store listen ( origin = $MASTER, provider = 1, receiver = 2 );
store listen ( origin = $SLAVE, provider = 2, receiver = 1 );
#创建一个复制集,id也是从1开始
create set ( id = $SET_ID, origin = $MASTER, comment = 'All pgbench tables' );
#向自己的复制集种添加表,每个需要复制的表添加一条set命令,id从1开始,逐次递加,步进为1;
#fully qualified name是表的全称:模式名.表名
#这里的复制集id需要和前面创建的复制集id一致
set add table ( set id = $SET_ID, origin = $MASTER,
id = 1, fully qualified name = 'public.accounts',
comment = 'Table accounts' );
_EOF_
########################
#在M_DB或者S_DB上执行
./urt_replica_init.sh
4. Slony Start
创建Master.slon文件:
########################
cluster_name="URT"
conn_info="dbname=URT host=M_DB user=postgres"
########################
创建Slave.slon文件:
########################
cluster_name="URT"
conn_info="dbname=URT host=S_DB user=postgres"
########################
#在M_DB上执行
/home/y/pgsql/bin/slon -f master.slon >> master.log &
#在S_DB上执行
/home/y/pgsql/bin/slon -f slave.slon >> slave.log &
5. Slony Subscribe
创建urt_replica_subscribe.sh文件:
########################
#!/bin/sh
SLONIK=/home/y/pgsql/bin/slonik
#slonik可执行文件位置
CLUSTER=URT
#你的集群的名称
SET_ID=1
#你的复制集的名称
MASTER=1
#主服务器ID
HOST1=M_DB
#源库IP或主机名
DBNAME1=URT
#需要复制的源数据库
SLONY_USER=postgres
#源库数据库超级用户名
SLAVE=2
#从服务器ID
HOST2=S_DB
#目的库IP或主机名
DBNAME2=URT
#需要复制的目的数据库
PGBENCH_USER=postgres
#目的库用户名
$SLONIK <<_EOF_
#这句是定义集群名
cluster name = $CLUSTER;
#这两句是定义复制节点
node $MASTER admin conninfo = 'dbname=$DBNAME1 host=$HOST1 user=$SLONY_USER';
node $SLAVE admin conninfo = 'dbname=$DBNAME2 host=$HOST2 user=$PGBENCH_USER ';
#提交复制集
subscribe set ( id = $SET_ID, provider = $MASTER, receiver = $SLAVE, forward = no);
_EOF_
########################
#在M_DB或者S_DB上执行
./urt_replica_subscribe.sh
6. 测试
修改M_DB上URT数据里的accounts表,S_DB上的accounts表也会随之改变
-
Linux下的 Postgresql的slony-i的数据同步配置 1、安装slony(两台服务器都需要安装) 去slony官网:http://www.slony.info/中下载合适的版本 例如:slony1-2.1.4.tar.bz2 解压: tar xvf slony1-2.1.4.tar.bz2 编译方法分三步: ./configure -with-perltools make make
-
一、Slony-I环境搭建 1.Slony-I下载地址://www.slony.info/downloads/ 2.编译安装: ./configure --prefix=/usr/local/slony --with-pgconfigdir=/usr/local/slony/bin --with-perltools --with-pgpkglibdir=/usr/local/slony/pg
-
工具下载 下载:http://www.slony.info/ 两边都需要安装且同步的表提前创建好! 解压缩 tar -jxvf slony1-2.1.4.tar.bz2 源端:192.168.1.100 目标端:192.168.1.101 编译安装 [highgo@pg962 slony1-2.1.4]$ ./configure --with-pgconfigdir=/home/highgo/hg
-
客户的问题是: 向Slony-I运行环境中,增加新的slaveDB节点的时候发生错误。 log中反复出现错误,然后再重新开始(重新开始部分的log省略): CONFIG remoteWorkerThread_1: connected to provider DB CONFIG remoteWorkerThread_1: prepare to copy table "tst"."a_tbl" CON
-
os: centos 7.4.1708 db: postgresql 11.8 Slony-I: 2.2.8 192.168.56.111 n1 192.168.56.112 n2 192.168.56.113 n3 这3个节点都需要安装 postgresql 11 及 Slony-I 本次实现同步 n1 节点某个表数据到 n2 节点。 版本 # cat /etc/centos-rele
-
环境: 主机 win7 CPU:Intel(R) Core(TM) i5 2.5GHz 内存:4G VMware虚拟2台 CentOS(512M 20G) Master IP:192.168.20.138 Slaver IP:192.168.20.139 软件:slony1-2.1.0.tar.bz2 postgresql-9.0.4.tar.bz2 一、源码安装postgreSQL数据库
-
近期,利用Slony给系统布设了数从数据复制方案。在方案末尾,需要探究一下,主DB的表结构变化,是否会导致数据复制出现异常,以及如何应对。 果不其然,主DB中的原始数据表,增加了一个字段,就导致针对该表的复制/数据同步,戛然而止了。不过,不必惊慌,这与slony文档所说的,由于Slony核心机制是基于表上的触发器,因此并不负责表结构的搬家,因此表结构的同步需要自行完成,并且可以将DDL语句委托给s
-
os: centos 7.4.1708 db: postgresql 11.8 Slony-I: 2.2.8 192.168.56.111 n1 192.168.56.112 n2 192.168.56.113 n3 这3个节点都需要安装 postgresql 11 及 Slony-I <<Slony-I 之二 master 节点 + 1目标节点>> 上篇 blog 实现了1对1的功能,
-
第一部分 在一个主机上创建多个 postgresql实例 步骤一:安装postgresql软件 安装 postgresql实例,从postgresql官网上 https://www.postgresql.org/ 下载postgresql安装软件,解压缩,创建postgres用户和组,添加环境变量。 我这里下载的版本是 pgsql9.5.1。 创建postgresql实例 安装了postg
-
本文向大家介绍PostgreSQL中Slony-I同步复制部署教程,包括了PostgreSQL中Slony-I同步复制部署教程的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要介绍了关于PostgreSQL中Slony-I同步复制部署的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 本次测试环境 IP 10.189.102.118 10.189.100.195 10
-
问题内容: 为什么以下代码在Python中表现异常? 我正在使用Python 2.5.2。尝试使用某些不同版本的Python,Python 2.3.3似乎在99到100之间显示了上述行为。 基于以上所述,我可以假设Python是内部实现的,因此“小”整数的存储方式与大整数的存储方式不同,并且is运算符可以分辨出这种差异。为什么要泄漏抽象?当我事先不知道它们是否为数字时,比较两个任意对象以查看它们是
-
本文向大家介绍从发展历程、产品机制、运营机制、发展瓶颈等方面对2-3个产品进行比较。备选的有头条系的抖音、火山,快手、小红书、微博、朋友圈、B站、Ins等等。相关面试题,主要包含被问及从发展历程、产品机制、运营机制、发展瓶颈等方面对2-3个产品进行比较。备选的有头条系的抖音、火山,快手、小红书、微博、朋友圈、B站、Ins等等。时的应答技巧和注意事项,需要的朋友参考一下 抖音vs快手 从发展历程、产
-
本文向大家介绍jQuery.fn的init方法返回的this指的是什么对象?为什么要返回this?相关面试题,主要包含被问及jQuery.fn的init方法返回的this指的是什么对象?为什么要返回this?时的应答技巧和注意事项,需要的朋友参考一下 [jQuery] jQuery.fn的init方法返回的this指的是什么对象?为什么要返回this?
-
问题内容: 我有桌子 我还有一张桌子 我要插入两个远程怪物:一个被称为 “弓箭妖精” ,攻击距离为 10 ,另一个被称为 “龙” ,攻击距离为 50 。我怎样才能在一条指令中做到这一点? 到目前为止,我已经尝试过了: 最坏的方法 这很不好,因为name列允许重复,并且检索到的记录可能不止一次。。。也不得不两次写出怪物的名字似乎不是一个好习惯。 插入…返回 如果表仅具有的列(外键),那么我可以使用以
-
问题内容: 我必须在表target_table中插入/更新一些记录。这些记录是一个source_table。 我正在使用MERGE更新/插入target_table。 我想在更新中添加一些特定条件。 那么就应该只有更新,否则就没有更新或插入。 问题答案: 您可以简单地在中添加子句。在oracle docs中有更多关于它的信息。 因此,在您的情况下,它应如下所示: