《pytorch》专题
-
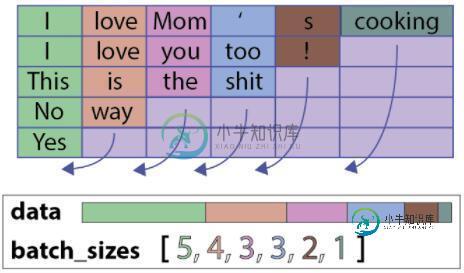 pytorch对可变长度序列的处理方法详解
pytorch对可变长度序列的处理方法详解本文向大家介绍pytorch对可变长度序列的处理方法详解,包括了pytorch对可变长度序列的处理方法详解的使用技巧和注意事项,需要的朋友参考一下 主要是用函数torch.nn.utils.rnn.PackedSequence()和torch.nn.utils.rnn.pack_padded_sequence()以及torch.nn.utils.rnn.pad_packed_sequence()来
-
对pytorch网络层结构的数组化详解
本文向大家介绍对pytorch网络层结构的数组化详解,包括了对pytorch网络层结构的数组化详解的使用技巧和注意事项,需要的朋友参考一下 最近再写openpose,它的网络结构是多阶段的网络,所以写网络的时候很想用列表的方式,但是直接使用列表不能将网络中相应的部分放入到cuda中去。 其实这个问题很简单的,使用moduleList就好了。 1 我先是定义了一个函数,用来根据超参数,建立一个基础网
-
如何在pytorch神经网络中的层中循环创建变量名
问题内容: 我在PyTorch中实现了一个简单的前馈神经传递函数。但是我想知道是否有更好的方法向网络添加灵活的层数?也许是在一个循环中命名它们,但是我听说那不可能吗? 目前我正在这样做 问题答案: 您可以将图层放入容器中: 对于这些层使用pytorch容器非常重要,而不仅仅是简单的python列表。请查看此答案以了解原因。
-
Pytorch torchvision MNIST下载
我是Pytorch和torchvision的新手。我遵循了大约一年前的一个教程,他试图通过python和torchvision下载mnist。 这就是为什么: 现在我的问题是,我得到这个错误: 回溯(最近一次呼叫最后一次): 正在下载http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz到data\MNIST\raw\train-im
-
PyTorch GPU内存不足
我正在PyTorch中运行一个评估脚本。我有许多经过训练的模型(*.pt文件),我将其加载并移动到GPU,总共占用270MB的GPU内存。我使用的批量大小为1。对于每个示例,我加载一个图像并将其移动到GPU。然后,根据样本,我需要运行一系列经过训练的模型。有些模型以张量作为输入和输出。其他模型的输入是张量,输出是字符串。序列中的最终模型总是有一个字符串作为输出。中间张量临时存储在字典中。当模型使用
-
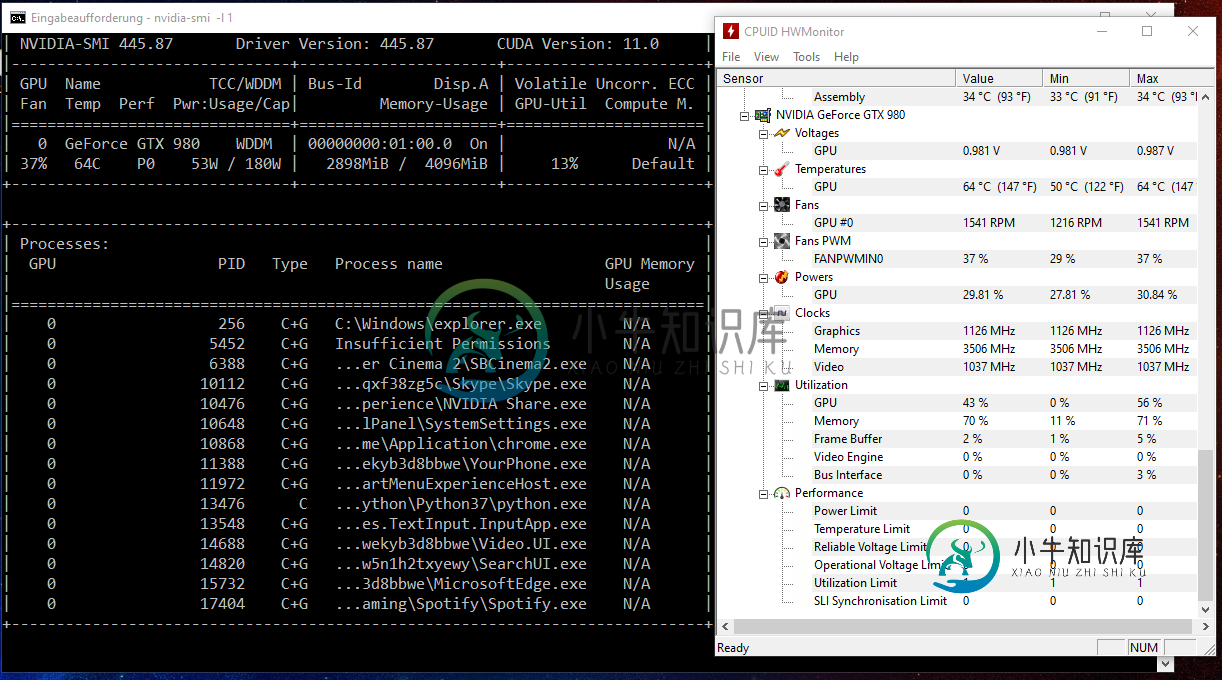 Pytorch GPU通用化
Pytorch GPU通用化因此,我目前正在训练我的DQN在雅达利突破(从OpenAI健身房)。我的问题是速度很慢,但我的GPU似乎没有得到充分利用。我正在使用一个名为的工具以及命令监视它。你知道为什么吗? 以下是一些可能相关的规范: 以下是对我的DQN的一些见解: 还有一件事可能很重要。出于某种原因,用CPU训练比用GPU更快。这些结果是平均超过30分钟的训练。我不能解释为什么我的CPU更快,所以如果有人有线索,我肯定想听
-
输出评估损失后,每n批次,而不是时代与pytorch
我想在每个n批次之后输出它,而不是在每个纪元打印评估损失。 我每个时代大约有15万批。我想每50000批输出一次评估损失。 这可能吗?我正在使用pytorch和huggingface的预训练bert模型。 我的列车循环:
-
在Pytorch中使用自定义损失的培训模型如何设置优化器并运行培训?
我是pytorch的新手,我正在尝试运行我找到的github模型并对其进行测试。因此,作者提供了模型和损失函数。 像这样: 数据加载 假设我想训练这个模型15个时代。这就是我到目前为止所做的:我正在尝试设置优化器和训练,但我不确定如何将自定义丢失和数据加载绑定到模型,并正确设置15个历元训练。 有什么建议吗?
-
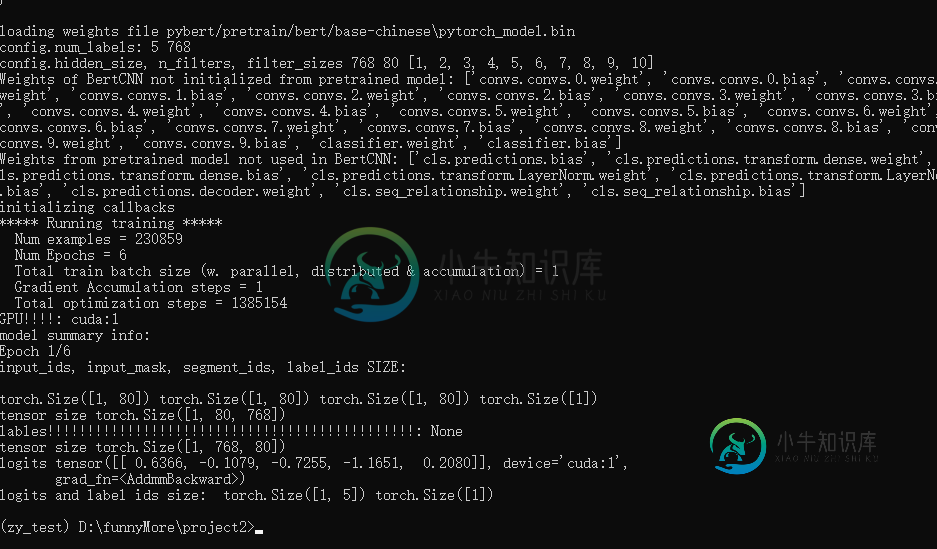 pytorch cnn模型停在loss.backward()没有任何提示?
pytorch cnn模型停在loss.backward()没有任何提示?我的目标是做一个五类文本分类 我正在使用模型运行bert微调,但我的项目在在中没有任何提示。 我的程序在中成功运行,例如和。 但是当我运行一些模型时,会出现一个奇怪的bug。 我的cnn型号代码: 我的列车代码: 修改batchsize为1错误仍然发生 step1登录: 罗吉斯张量([0.8831,-0.0368,-0.2206,-2.3484,-1.3595]),装置='cuda:1',梯度fn
-
尝试使用Torch/PyTorch创建docker映像时出现MemoryError
我遵循本教程为烧瓶应用程序创建Docker映像。应用程序取决于Torch/PyTorch。因此,我的文件如下所示。 我的Dockerfile如下所示。 当我输入命令
-
Onnxruntime vs PyTorch
我已经训练活在当下-v3微小在我的自定义数据集使用PyTorch。为了比较推论时间,我在CPU上尝试了onnxruntime以及PyTorch GPU和PyTorch CPU。平均运行时间约为: onnxruntime cpu:110毫秒-cpu使用率:60%Pytorch GPU:50毫秒Pytorch cpu:165毫秒-cpu使用率:40%,所有型号都使用批量大小为1的产品。 然而,我不明白
-
Pytorch的mean和std调查实例
本文向大家介绍Pytorch的mean和std调查实例,包括了Pytorch的mean和std调查实例的使用技巧和注意事项,需要的朋友参考一下 如下所示: 结论: 下面调查均值文件和方差文件是如何生成的: 结果: 使用matlab检测是如何计算mean_file和std_file的: 均值计算的过程也可以遵循标准差的计算过程。为 了简单,例如对于一个矩阵,所有元素的均值,等于两个方向上先后均值。所
-
 pytorch 图像预处理之减去均值,除以方差的实例
pytorch 图像预处理之减去均值,除以方差的实例本文向大家介绍pytorch 图像预处理之减去均值,除以方差的实例,包括了pytorch 图像预处理之减去均值,除以方差的实例的使用技巧和注意事项,需要的朋友参考一下 如下所示: 以上这篇pytorch 图像预处理之减去均值,除以方差的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
pytorch实现focal loss的两种方式小结
本文向大家介绍pytorch实现focal loss的两种方式小结,包括了pytorch实现focal loss的两种方式小结的使用技巧和注意事项,需要的朋友参考一下 我就废话不多说了,直接上代码吧! 以上这篇pytorch实现focal loss的两种方式小结就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持呐喊教程。
-
 pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解本文向大家介绍pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解,包括了pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解的使用技巧和注意事项,需要的朋友参考一下 公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果。这里只给出公式,关于CrossEntropy