
pytorch cnn模型停在loss.backward()没有任何提示?

我的目标是做一个五类文本分类
我正在使用cnnbase模型运行bert微调,但我的项目在丢失时停止。backward()在cmd中没有任何提示。
我的程序在rnn base中成功运行,例如lstm和rcnn。
但是当我运行一些cnnbase模型时,会出现一个奇怪的bug。
我的cnn型号代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
# from ..Models.Conv import Conv1d
from transformers.modeling_bert import BertPreTrainedModel, BertModel
n_filters = 200
filter_sizes = [2,3,4]
class BertCNN(BertPreTrainedModel):
def __init__(self, config):
super(BertPreTrainedModel, self).__init__(config)
self.num_filters = n_filters
self.filter_sizes = filter_sizes
self.bert = BertModel(config)
for param in self.bert.parameters():
param.requires_grad = True
self.convs = nn.ModuleList(
[nn.Conv2d(1, self.num_filters, (k, config.hidden_size))
for k in self.filter_sizes])
self.dropout = nn.Dropout(config.hidden_dropout_prob)
self.fc_cnn = nn.Linear(self.num_filters *
len(self.filter_sizes), config.num_labels)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, input_ids,
attention_mask=None, token_type_ids=None, head_mask=None):
outputs = self.bert(input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
head_mask=head_mask)
encoder_out, text_cls = outputs
out = encoder_out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv)
for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc_cnn(out)
return out
我的列车代码:
for step, batch in enumerate(data):
self.model.train()
batch = tuple(t.to(self.device) for t in batch)
input_ids, input_mask, segment_ids, label_ids = batch
print("input_ids, input_mask, segment_ids, label_ids SIZE: \n")
print(input_ids.size(), input_mask.size(),segment_ids.size(), label_ids.size())
# torch.Size([2, 80]) torch.Size([2, 80]) torch.Size([2, 80]) torch.Size([2])
logits = self.model(input_ids, segment_ids, input_mask)
print("logits and label ids size: ",logits.size(), label_ids.size())
# torch.Size([2, 5]) torch.Size([2])
loss = self.criterion(output=logits, target=label_ids)
if len(self.n_gpu) >= 2:
loss = loss.mean()
if self.gradient_accumulation_steps > 1:
loss = loss / self.gradient_accumulation_steps
if self.fp16:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
clip_grad_norm_(amp.master_params(self.optimizer), self.grad_clip)
else:
loss.backward() # I debug find that the program stop at this line without any error prompt
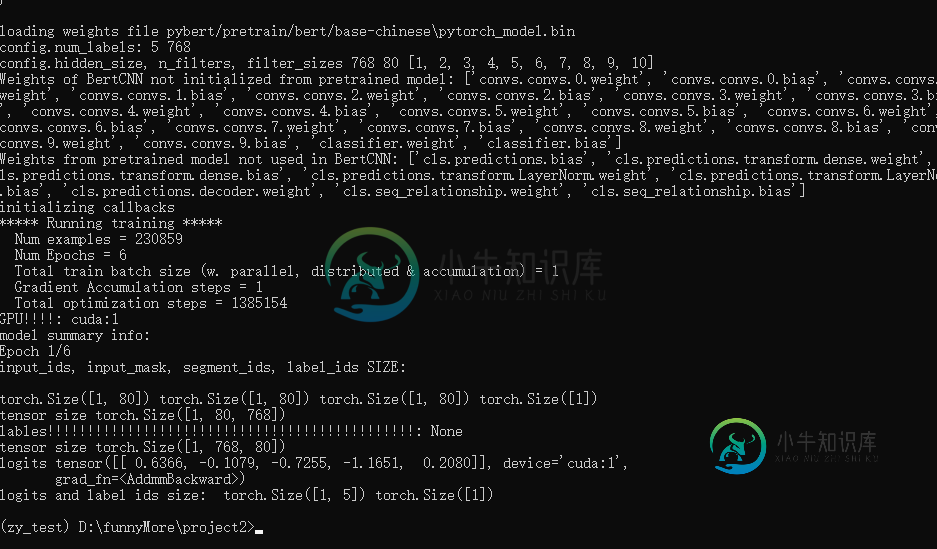
修改batchsize为1错误仍然发生
step1登录:
罗吉斯张量([0.8831,-0.0368,-0.2206,-2.3484,-1.3595]),装置='cuda:1',梯度fn=)
第一步损失:
张量(1.5489,器件='cuda: 1',grad_fn=NllLossBackward
但为什么不能失去。向后()?
共有2个答案

我也遇到了同样的问题。就我而言,这个问题源于pytorch的版本兼容性。当我将pytorch升级到最新版本(1.5.1-

-
问题内容: 我查看了以前的文章,但似乎找不到解决此问题的方法。所有三行代码都给出“类型’Any’没有下标成员”错误。对此还很陌生,因此不胜感激。 问题答案: 的类型为。下标是一种特殊的函数,它使用将值括在大括号中的语法。此下标功能由实现。 因此,这里发生的是,作为开发人员的YOU知道这是一个,但是编译器却没有。它不会让您调用该函数,因为您试图在type的值上调用它并且未实现。为此,您必须告诉编译器
-
问题内容: 我想为模块(类“模块”)添加(Python3)类型提示。该包不提供一个,并且是返回模块对象为特定名称的构造器。 例: 至少在PyCharm中导致“在types.pyi中找不到引用ModuleType”。 请注意,使用Python输入模块类型不会回答我的问题,因为它不能解释ModuleType既是构造函数又是类型,如下所示。 问题答案: 并且是构造函数。 没关系 就像和are一样,仍然是
-
问题内容: 我收到此错误:尝试运行此代码块时,“类型’Any’没有下标成员”: 我一直在寻找答案,但找不到用FireBase解决此问题的答案。我该如何解决这个错误? 问题答案: 具有类型,因此您需要将其强制转换为基础类型,然后才能对其进行下标。由于is ,请使用可选的强制类型转换来建立类型,然后您可以访问字典中的值: 或者,您也可以单线执行此操作:
-
我在videorequest应用程序中制作简单模型 当我试图运行python manage时,代码cmd中显示了什么错误。py运行服务器查询 由启动的线程中存在未处理的异常。0x0446E7C8处的包装器
-
我在tensorflow中实现了一个简单的线性回归。如果我将值的数量保持得非常小(小于8),它就可以正常工作。但是,一旦我做了大量(8个或更多样本),我就会得到NaN的。 这令人困惑,因为这是一个简单的回归,没有除法。成本是均方误差:仅除以固定整数(样本数)。此外,切换到平方和误差也会导致相同的问题。 Tensorflow NaN bug?不会有帮助,因为我的代码中没有分区或登录。 最后,添加会导
-
是否有任何方法可以检测一个类是正常类型还是包含非类型参数的模板类型(元类型)的实例化?我想出了这个解决方案: 但是,对于混合了非类型和类型的模板,例如 除了必须显式指定重载中的类型之外,我无法提出任何解决方案。当然,由于组合爆炸,这是不合理的。 相关问题(不是欺骗):是否可以仅通过标识符检查成员模板的存在?