《pytorch》专题
-
使用Mongo DB的PyTorch数据加载器
我想知道使用连接到MongoDB的DataLoader是否是一件明智的事情,以及如何实现这一点。 出身背景 我在一个(本地)MongoDB中有大约2000万个文档。超过内存容量的文档太多了。我想在数据上训练一个深层次的神经网络。到目前为止,我一直在首先将数据导出到文件系统,子文件夹被命名为文档的类。但我觉得这种方法是荒谬的。如果数据库中的数据已经得到很好的维护,为什么要先导出(然后删除)。 问题1
-
pytorch中的模型摘要
如何像方法在Keras中的作用:
-
PyTorch dataloader显示字符串数据集的奇怪行为
我正在处理NLP问题,正在使用PyTorch。由于某些原因,我的数据加载器返回了格式错误的批。我有由句子和整数标签组成的输入数据。这些句子可以是句子列表,也可以是标记列表。稍后我将在下游组件中将标记转换为整数。 我创建了以下自定义数据集: 当我以句子列表的形式提供输入时,数据加载器正确地返回成批完整的句子。请注意,: 批次正确地包含两句话和两个标签,因为。 然而,当我将句子作为标记列表的预标记列表
-
用PyTorch数据加载器将三维和一维特征传递给神经网络
我有大小为2x8x8的张量的例子,我使用PyTorch Dataloader。但是现在我想添加一个额外的1微调张量,大小为1(单个数字)作为输入。 所以我有两个神经网络的输入参数,一个是多维的,用于卷积层,另一个是我稍后将连接的。 也许我可以为每个张量形状使用两个数据加载器,但是我不能洗牌它们。 如何将一个PyTorch数据加载器用于这两个不同的输入张量?
-
批量加载一个巨大的数据集来训练pytorch
我正在训练一个LSTM,以便将时间序列数据分类为2类(0和1)。我在驱动器上有巨大的数据集,其中0类和1类数据位于不同的文件夹中。我试图通过创建一个Dataset类并将DataLoader包装在它周围来批量使用LSTM。我必须做整形等预处理。这是我的密码 ' `我在运行此代码时遇到此错误 RuntimeError:Traceback(最后一次调用):文件“/usr/local/lib/python
-
在pytorch的seq2seq模型中,批处理是如何工作的?
我试图在Pytorch中实现seq2seq模型,我对批处理有一些问题。例如,我有一批数据,其尺寸是 [batch_sizesequence_lengthsencoding_dimension] 其中,批次中每个示例的序列长度不同。 现在,我通过将批处理中的每个元素填充到最长序列的长度来完成编码部分。 通过这种方式,如果我向我的网络输入一个与上述形状相同的批次,我会得到以下输出: 输出,形状 隐藏状
-
pytorch dataloader和/或_getitem__________函数中的浅拷贝和深拷贝
我遇到了一个自定义pytorch dataloader的问题,我认为它与函数中的浅拷贝和深拷贝有关。但是,有些行为我不理解。我不知道它是来自pytorch dataloader类还是其他地方。 我根据自己的复杂用例创建了一个最小的工作示例。最初,我将一个数据集保存为,并将其加载到中。对于NN,我希望元素归一化为1(我除以它们的总和),并分别返回总和。: 我得到以下输出: 在第一个历元之后,应该给出
-
pytorch Dataloader-如果输入数据返回多个训练实例
我有以下问题: 我想使用pytorchs DataLoader(类似于这里),但我的设置有所不同: 在我的datafolder中,我有不同街道状况的图像(称为),我想使用裁剪后的图像(称为在离摄像机足够近的人周围。因此,有些图像可能会给我一张或多张裁剪过的图像,而另一些图像会给我零张图像,因为它们没有显示任何人或它们离我很远。 由于我有很多图像,我希望使实现尽可能高效。 我希望可以使用这样的东西:
-
Pytorch DataLoader中的采样器参数
在使用Pytorch的DataLoader实用程序时,在sampler中,的用途是什么?在中有一个参数。
-
PyTorch数据集/数据加载程序批处理
对于在时间序列数据上实现PyTorch数据管道的“最佳实践”,我有点困惑。 我有一个HD5文件,我使用自定义DataLoader读取。似乎我应该返回数据样本作为一个(特征,目标)元组,每个元组的形状是(L,C),其中L是seq_len,C是通道数-即不要在数据加载器中预制批处理,只需返回一个表。 PyTorch模块似乎需要一个批处理暗淡,即。Conv1D期望(N,C,L)。 我的印象是,类将预先处
-
 PyTorch面试题面经
PyTorch面试题面经1.conv2d的参数及含义 2.pytorch如何微调fine tuning:在加载了预训练模型参数之后,需要finetuning模型,可以使用不同的方式finetune 局部微调:加载了模型参数后,只想调节最后几层,其它层不训练,也就是不进行梯度计算,pytorch提供的requires_grad使得对训练的控制变得非常简单 全局微调:对全局微调时,只不过我们希望改换过的层和其他层的学习速率不
-
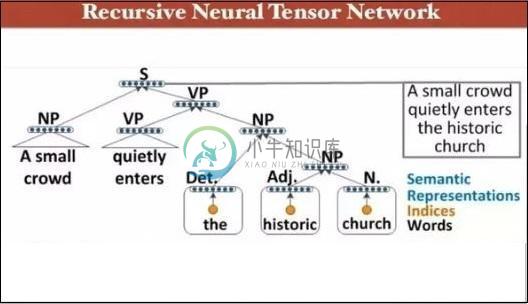 PyTorch递归神经网络
PyTorch递归神经网络深度神经网络具有独特的功能,可以帮助机器学习突破自然语言的过程。 据观察,这些模型中的大多数将语言视为单词或字符的平坦序列,并使用一种称为递归神经网络或RNN的模型。 许多研究人员得出的结论是,对于短语的分层树,语言最容易被理解。 此类型包含在考虑特定结构的递归神经网络中。 PyTorch有一个特定的功能,有助于使这些复杂的自然语言处理模型更容易。 它是一个功能齐全的框架,适用于各种深度学习,并为
-
PyTorch单词嵌入
在本章中,我们将了解单词嵌入模型—。Word2vec模型用于在相关模型组的帮助下生成单词嵌入。Word2vec模型使用纯C代码实现,并且手动计算梯度。 PyTorch中word2vec模型的实现在以下步骤中解释 - 第1步 在以下库中实现单词嵌入,如下所述 - 第2步 使用名为word2vec的类实现单词嵌入的Skip Gram模型。它包括:,,,类型的属性。 第3步 实现main方法,以正确的方
-
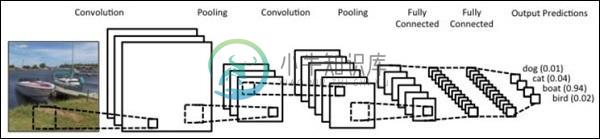 PyTorch Convent进行序列处理
PyTorch Convent进行序列处理在本章中,提出了一种替代方法,它依赖于跨两个序列的单个2D卷积神经网络。网络的每一层都根据到目前为止产生的输出序列重新编码源令牌。因此,类似注意的属性在整个网络中普遍存在。 在这里,将专注于使用数据集中包含的值创建具有特定池的顺序网络。此过程也最适用于“图像识别模块”。 以下步骤用于使用PyTorch创建带有Convent的序列处理模型 - 第1步 使用convent导入必要的模块以执行序列处理。
-
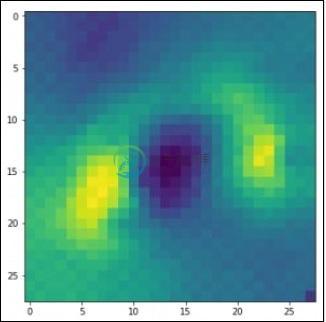 PyTorch Convents可视化
PyTorch Convents可视化在本章中,我们将在Convents的帮助下专注于数据可视化模型。需要以下步骤才能使用传统的神经网络获得完美的可视化图像。 第1步 导入必要的模块,这对于传统神经网络的可视化非常重要。 第2步 要通过训练和测试数据来停止潜在的随机性,请调用以下代码中给出的相应数据集 - 第3步 使用以下代码绘制必要的图像,以完美的方式定义训练和测试数据 - 输出显示如下 -