
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解

公式
首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的:

其中,其中yi表示真实的分类结果。这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文。
测试代码(一维)
import torch
import torch.nn as nn
import math
criterion = nn.CrossEntropyLoss()
output = torch.randn(1, 5, requires_grad=True)
label = torch.empty(1, dtype=torch.long).random_(5)
loss = criterion(output, label)
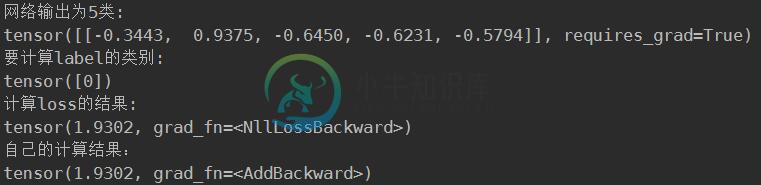
print("网络输出为5类:")
print(output)
print("要计算label的类别:")
print(label)
print("计算loss的结果:")
print(loss)
first = 0
for i in range(1):
first = -output[i][label[i]]
second = 0
for i in range(1):
for j in range(5):
second += math.exp(output[i][j])
res = 0
res = (first + math.log(second))
print("自己的计算结果:")
print(res)

测试代码(多维)
import torch
import torch.nn as nn
import math
criterion = nn.CrossEntropyLoss()
output = torch.randn(3, 5, requires_grad=True)
label = torch.empty(3, dtype=torch.long).random_(5)
loss = criterion(output, label)
print("网络输出为3个5类:")
print(output)
print("要计算loss的类别:")
print(label)
print("计算loss的结果:")
print(loss)
first = [0, 0, 0]
for i in range(3):
first[i] = -output[i][label[i]]
second = [0, 0, 0]
for i in range(3):
for j in range(5):
second[i] += math.exp(output[i][j])
res = 0
for i in range(3):
res += (first[i] + math.log(second[i]))
print("自己的计算结果:")
print(res/3)
nn.CrossEntropyLoss()中的计算方法
注意:在计算CrossEntropyLosss时,真实的label(一个标量)被处理成onehot编码的形式。
在pytorch中,CrossEntropyLoss计算公式为:

CrossEntropyLoss带权重的计算公式为(默认weight=None):

以上这篇pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持小牛知识库。
-
本文向大家介绍交叉熵公式相关面试题,主要包含被问及交叉熵公式时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 交叉熵:设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是: 在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。 互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自
-
本文向大家介绍交叉熵 kl散度相关面试题,主要包含被问及交叉熵 kl散度时的应答技巧和注意事项,需要的朋友参考一下 https://www.zhihu.com/question/41252833 表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。 交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分
-
本文向大家介绍Pytorch 的损失函数Loss function使用详解,包括了Pytorch 的损失函数Loss function使用详解的使用技巧和注意事项,需要的朋友参考一下 1.损失函数 损失函数,又叫目标函数,是编译一个神经网络模型必须的两个要素之一。另一个必不可少的要素是优化器。 损失函数是指用于计算标签值和预测值之间差异的函数,在机器学习过程中,有多种损失函数可供选择,典型的有距离
-
定理14:一个系集的带宽为W,其熵为(每自由度),如果使该系集通过一个特性函数为的滤波器,则输出系集的熵为: 。 此滤波器的运算实际上就是坐标系的线性变换。如果将不同的频率分量看作原坐标系,则新的频率分量实际上就是原频率分量乘以相应的因子。坐标变换矩阵的对角线元素实际上就是这些坐标。该变换的雅可比行列式为(对于n个正弦分量和n个余弦分量): 其中在带宽W内等间隔分布。因此,上式变为极限值: 。 由
-
我正在处理ISCXVPN2016数据集,它由一些pcap文件组成(每个pcap都是特定应用程序(如skype、youtube等)的流量捕获),我已将它们转换为pickle文件,然后使用以下代码将其写入文本文件: file.txt: b'\x80\x03]q\x00(cnumpy.core.multiarray\n'b'_reconstruct\n'b'q\x01cNumpy\n'b'ndarray
-
本文向大家介绍神经网络为啥用交叉熵。相关面试题,主要包含被问及神经网络为啥用交叉熵。时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 通过神经网络解决多分类问题时,最常用的一种方式就是在最后一层设置n个输出节点,无论在浅层神经网络还是在CNN中都是如此,比如,在AlexNet中最后的输出层有1000个节点,而即便是ResNet取消了全连接层,也会在最后有一个1000个节点的输出层。 一般情况