
交叉熵公式

参考回答:
交叉熵:设p(x)、q(x)是X中取值的两个概率分布,则p对q的相对熵是:
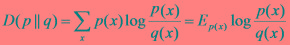
在一定程度上,相对熵可以度量两个随机变量的“距离”,且有D(p||q) ≠D(q||p)。另外,值得一提的是,D(p||q)是必然大于等于0的。
互信息:两个随机变量X,Y的互信息定义为X,Y的联合分布和各自独立分布乘积的相对熵,用I(X,Y)表示:
且有I(X,Y)=D(P(X,Y)||P(X)P(Y))。下面,咱们来计算下H(Y)-I(X,Y)的结果,如下:
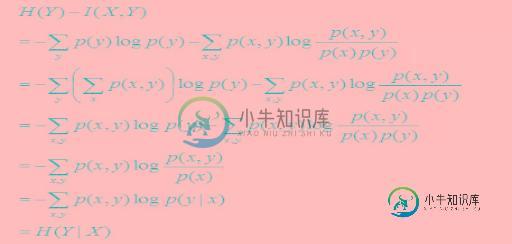
-
本文向大家介绍交叉熵 kl散度相关面试题,主要包含被问及交叉熵 kl散度时的应答技巧和注意事项,需要的朋友参考一下 https://www.zhihu.com/question/41252833 表示2个函数或概率分布的差异性:差异越大则相对熵越大,差异越小则相对熵越小,特别地,若2者相同则熵为0。 交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分
-
本文向大家介绍神经网络为啥用交叉熵。相关面试题,主要包含被问及神经网络为啥用交叉熵。时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 通过神经网络解决多分类问题时,最常用的一种方式就是在最后一层设置n个输出节点,无论在浅层神经网络还是在CNN中都是如此,比如,在AlexNet中最后的输出层有1000个节点,而即便是ResNet取消了全连接层,也会在最后有一个1000个节点的输出层。 一般情况
-
问题内容: 我正在尝试训练数据不平衡的网络。我有A(198个样本),B(436个样本),C(710个样本),D(272个样本),并且我已经阅读了有关“weighted_cross_entropy_with_logits”的信息,但是我发现的所有示例都是针对二进制分类的,因此我不太了解对如何设置这些权重充满信心。 样本总数:1616 A_weight:198/1616 = 0.12? 如果我理解的话
-
本文向大家介绍pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解,包括了pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解的使用技巧和注意事项,需要的朋友参考一下 公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果。这里只给出公式,关于CrossEntropy
-
本文向大家介绍请你说一说交叉熵,也可以再说一下其他的你了解的熵相关面试题,主要包含被问及请你说一说交叉熵,也可以再说一下其他的你了解的熵时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 为了更好的理解,需要了解的概率必备知识有: 大写字母X表示随机变量,小写字母x表示随机变量X的某个具体的取值; P(X)表示随机变量X的概率分布,P(X,Y)表示随机变量X、Y的联合概率分布,P(Y|X)表示
-
熵 有关熵的介绍,我在《自己动手做聊天机器人 十五-一篇文章读懂拿了图灵奖和诺贝尔奖的概率图模型》中做过简单的介绍,熵的英文是entropy,本来是一个热力学术语,表示物质系统的混乱状态。 我们都知道信息熵计算公式是H(U)=-∑(p logp),但是却不知道为什么,下面我们深入熵的本源来证明这个公式 假设下图是一个孤立的由3个分子构成一罐气体 那么这三个分子所处的位置有如下几种可能性: 图中不同