《数据分析这么卷的吗?》专题
-
基于Antlr的永续流数据解析
当“b”输入时-输入规则“fox” 然后是“roun”--什么都没有(2个代币在流中--他们中的任何一个都不为leser所知!) 只有在'f'之后,侦听器才会访问第一个令牌:'quick' 谢了!
-
Spring数据r2dbc和分组依据
我正在使用DatabaseClient执行sql查询,我不知道如何通过以下方式进行分组:
-
使用C#解析JSON数据
问题内容: 我有大约7000行要解析的JSON数据。在这里可以看到其中一部分的示例。我所做的就是利用和把所有的数据转换成字符串。(奇怪的是,它将所有数据放入一条很长的行中)。但是现在我想解析这个,我不确定如何。谁能解释如何使用?我之前已经用Java解析过JSON数据,但是用C#却遇到了麻烦,特别是因为我无法找到带有清晰示例的文档。任何帮助将不胜感激。 问题答案: 尝试使用JSON.Net,如果您还
-
在Jquery中解析Json数据
问题内容: 我是Jquery,Ajax和JSON的新手。我在解析Json数据时遇到问题。我在Stackoverflow上遇到了很多问题 解析HTML表的JSON对象 访问/处理(嵌套的)对象,数组或JSON 在JavaScript中解析JSON? 如何在JQuery中解析此JSON对象? 还有很多… 我仍然无法解析Json数据。 我的Jquery看起来像: 我已经尝试了所有组合来解析此数据,但是j
-
将JSON数据解析为类
类: JSON数据: {“列表”:[{“类型”:0,“文本”:“文本1”},{“类型”:1,“问题”:“文本2”}]} 类来保存列表项: 一切顺利,我为JSON字符串中的type和text获得了正确的值。但逮捕仍为空。
-
1.4.2.1.4 Step4. 数据解析脚本
Step4. 数据解析脚本 概述 编辑脚本内容 保存草稿 脚本模拟运行 提交脚本 Step4. 数据解析脚本 更新时间:2018-03-23 18:15:58 概述 本章节主要针对采用透传/自定义格式上报数据的设备,您如果使用了Alink协议可以跳过,可以直接参考 Alink 协议文档完成设备端的开发和接入,无需编辑数据解析脚本。 Link Develop为开发者提供了用于数据解析的在线脚本编辑器
-
Seata 数据源代理解析
在Seata1.3.0版本中,数据源自动代理和手动代理一定不能混合使用,否则会导致多层代理,从而导致以下问题: 单数据源情况下:导致分支事务提交时,undo_log本身也被代理,即为 undo_log 生成了 undo_log, 假设为undo_log2,此时undo_log将被当作分支事务来处理;分支事务回滚时,因为undo_log2生成的有问题,在undo_log对应的事务分支回滚时会将业务表
-
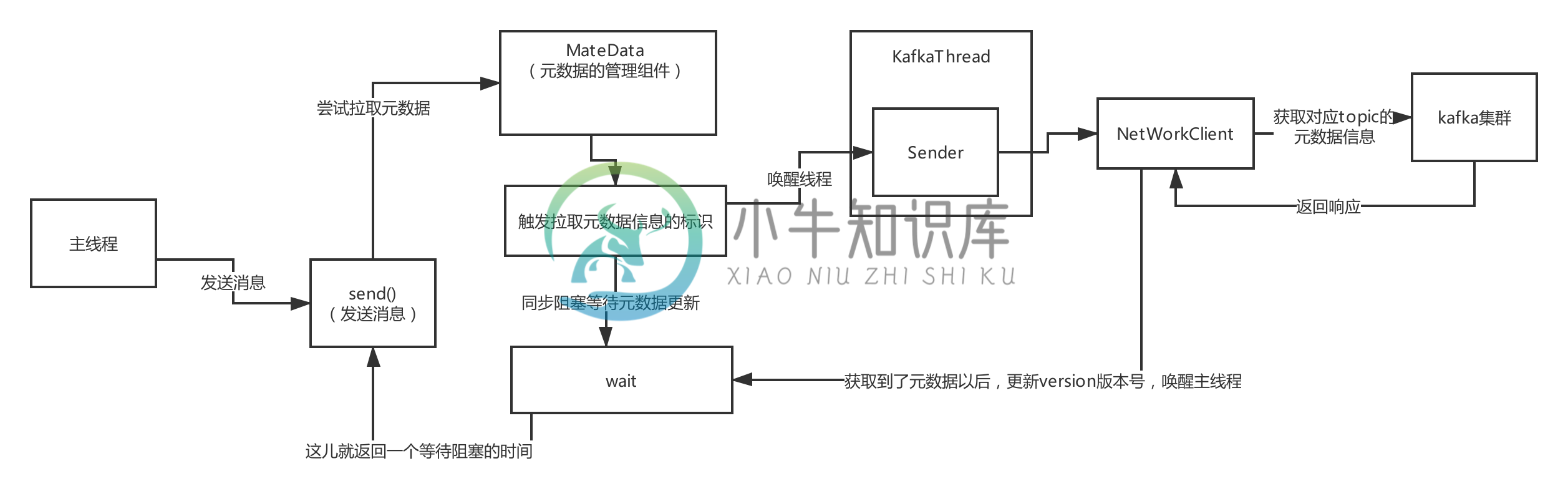 producer拉取元数据剖析
producer拉取元数据剖析主要内容:总体流程图,源码剖析,waitOnMetadata,awaitUpdate,Sender线程方法,步骤一:maybeUpdate,步骤二,步骤三总体流程图 源码剖析 waitOnMetadata awaitUpdate Sender线程方法 再调用run方法 就是poll方法进行拉取 步骤一:maybeUpdate 步骤二 待补充 。。。 步骤三 handleCompletedReceives maybeHandleCompletedReceive handleResponse 最后我
-
如何确定用于图像分类的卷积神经网络的参数?
我正在使用卷积神经网络(无监督特征学习检测特征Softmax回归分类器)进行图像分类。我已经阅读了Andrew NG在这方面的所有教程。(http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial)。 我开发的网络有一个: 输入层-大小8x8(64个神经元) 隐藏层-大小为400个神经元 输出层-大小3 我已经学习了使用稀疏自动编码器将输入层连接
-
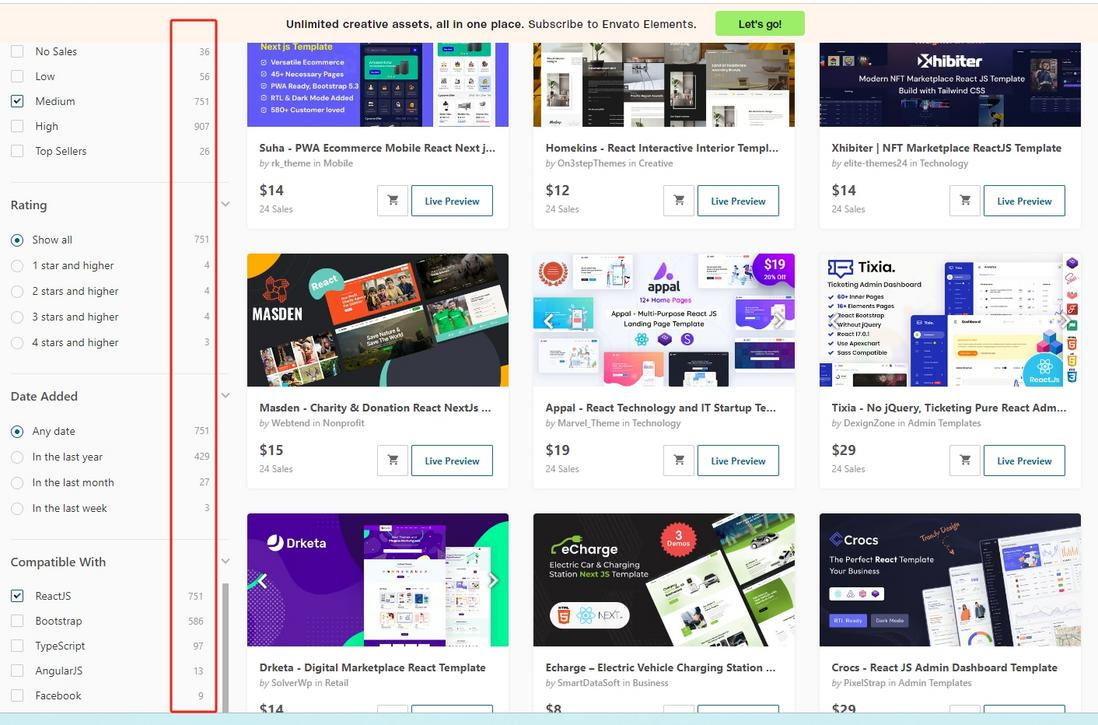 sql - 这样的网站过滤显示多少条的数据需要怎么实现?
sql - 这样的网站过滤显示多少条的数据需要怎么实现?https://themeforest.net/category/site-templates?sort=sales&vi... 主要是旁边显示的条数,这个要怎么统计出来? 第一种:这样一条一条SQL统计,应该可以组合几万种吧,不现实? 第二种:一开始把所有的记录全部查出来再去计算,那这个要是有几十万的数据,一下查出几十万条,是不是也不现实,那分页就没意义了? 具体思路是什么,要怎么做?
-
为什么这个简单的Haskell程序这么慢?[重复]
在这个打印从1到10000000的所有数字、Haskell版本和C版本的简单程序中,为什么Haskell版本如此缓慢,以及哪些命令有助于学习如何提高Haskell程序的性能? 下面是一份报告,包含重现我激动人心的事件所需的所有细节,制作报告时会打印出来源,包括Makefile的来源:
-
Docker,这是什么,目的是什么
我几天前听说了Docker的事,想过去看看。 但事实上,我不知道这个“容器”的用途是什么? 什么是容器? 它能取代一个专门用于开发的虚拟机吗? 简单地说,在公司中使用Docker的目的是什么?主要的优势?
-
如何从javafx webview解析html并将这些数据转移到Jsoup文档?
我正在尝试解析某个文档站点的侧栏TOC(组件表)。 J汤 我试过jsoup。我无法获得TOC元素,因为这个标记中的HTML内容不是初始HTML的一部分,而是在加载页面后由JavaScript设置的。 但我不知道如何检索加载的网站的HTML代码,并将这些数据转移到Jsoup文档中?感谢任何建议。
-
卷积网络的输入通道数
我正在关注TensorFlow的“专家深度列表”教程:https://www.tensorflow.org/tutorials/mnist/pros/ 第二卷积层具有形状【5、5、32、64】;也就是说,它有32个输入,而第一个卷积层有1个输入(该输入是我了解原始图像的灰度值)。 第二个卷积层有32个输入通道意味着什么?这是否意味着在第二层中学习的64个过滤器将全部应用(移位)到每像素具有32个点
-
如果基类析构函数是虚的,那么派生类的析构函数默认是虚的吗?
我最近在读虚函数和虚析构函数,下面的问题引起了我的兴趣。 例如,我有以下继承链。 我知道基类的虚函数在派生类中默认是隐式虚的。所以,我认为这同样适用于析构函数。 我想知道,派生类的析构函数是否默认是虚拟的。如果没有,如果您提供一些解释,我将很高兴。