《数据分析这么卷的吗?》专题
-
将数据从文件解析为Java,然后解析为mysql数据库
问题内容: 我有以上述格式给出的.Data文件。我正在用Java编写程序,该程序将从.data文件中获取值并将其放入缓冲区中。我的Java程序通过JDBC连接到Mysql(windows)。所以我需要从上述格式的文件中读取值,并将其放入缓冲区 这样,我将存储这些值,并且jdbc将填充Mysql(windows)上的数据库表。请告诉我最好的方法。 问题答案: 查看此问题的答案,以读取文件行并将其拆分
-
为什么会这样。拆分导致数组越界错误?[重复]
我正在使用Java8。 预期输出为3。
-
词法分析器和语法分析器的界线
因为词法规则可以使用递归,所以词法解析器在技术上和语法解析器一样强大。那意味着我们甚至可以在词法分析器中匹配语法结构。或者,在另一个极端,我们可以把字符当作记号,使用语法分析器去把语法结构应用到字符流(这种被称为无扫描语法分析器)。这导致什么在词法分析器中匹配和什么在语法分析器中匹配的界线在哪里并不是很明显。幸运的是,有几条经验法则可以让我们做出判断: 在词法分析器中匹配和丢弃任何语法分析器根本不
-
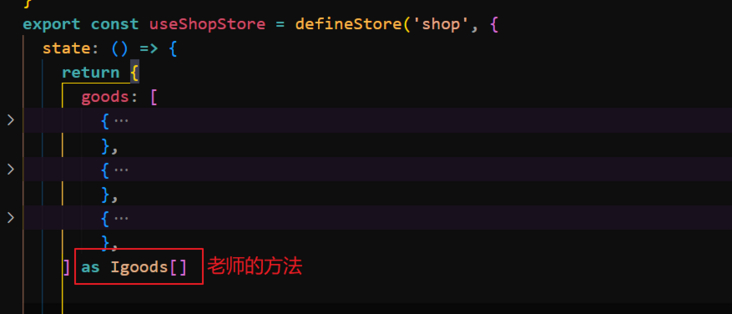 前端 - ts-请问怎么用接口约束这个返回的数据呢?
前端 - ts-请问怎么用接口约束这个返回的数据呢?现在就是我定义了一个接口Igoods,但是我不知道怎么用它来约束下面返回的goods这个数组,老师写的方法是在数组后面加上了as Igoods[],请问还有其他的方法吗?感谢各位大佬! 代码部分:
-
Firebase实时数据库的这些默认安全规则意味着什么?
我在Firebase上创建了一个新项目,并在其中创建了一个实时数据库。当被问及数据库的安全规则时,我选择了在测试模式下启动。 现在,Firebase控制台中我的数据库的安全规则显示为: 这些规则意味着什么?我怎样才能把它们改得更安全呢?
-
如何按连续数据分组(在这种情况下为日期)
问题内容: 我有一个表和一个表,该表记录着给定产品在每个日期售出了多少个项目。当然,并非所有产品每天都有销售。 我需要生成一个报告,告诉我产品 连续 几天销售(从最新日期到过去),以及仅在那几天销售了多少物品。 我想告诉您到目前为止我已经尝试了多少方法,但是唯一成功(缓慢,递归)的方法是应用程序内部的解决方案,而不是SQL内部的解决方案,这就是我想要的。 我还浏览了关于SO的几个类似问题,但没有找
-
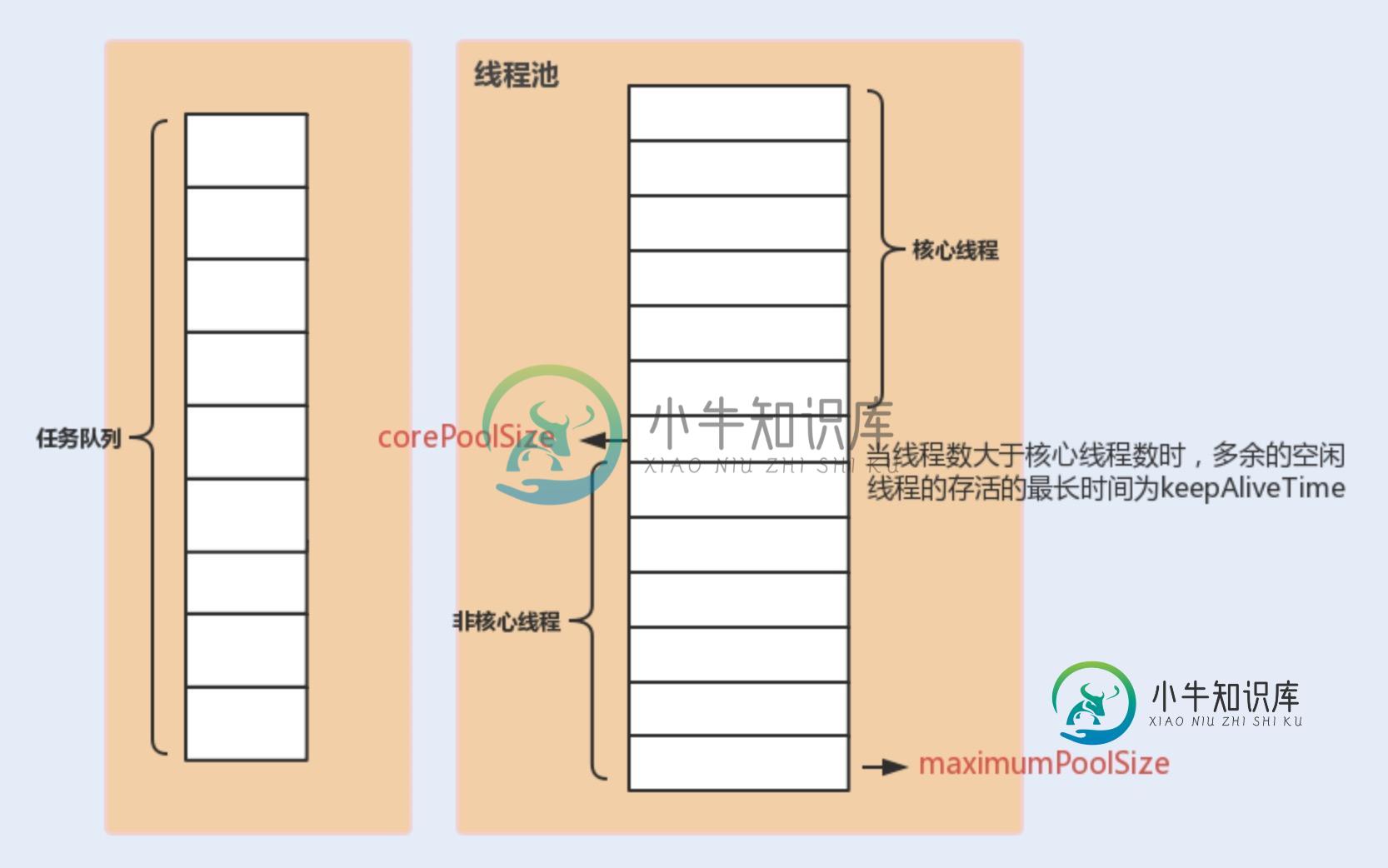 ThreadPoolExecutor 构造函数重要参数分析?
ThreadPoolExecutor 构造函数重要参数分析?本文向大家介绍ThreadPoolExecutor 构造函数重要参数分析?相关面试题,主要包含被问及ThreadPoolExecutor 构造函数重要参数分析?时的应答技巧和注意事项,需要的朋友参考一下 : : 核心线程数线程数定义了最小可以同时运行的线程数量。 : 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。 : 当新任务来的时候会先判断当前运行的线程数量是否
-
为什么分报告中不同维度的数据相加会大于网站概况的数据
使用指南 - 疑难问题 - 数据矛盾问题 - 为什么分报告中不同维度的数据相加会大于网站概况的数据 每个报告的分析维度不同,因此去重逻辑也不同。网站概况,以及趋势报告中的数据是以整个站点为维度去重的,是了解站点整体流量和访问量的地方。 例如:访客 X 通过百度搜索进入网站后又通过直接访问进入网站,此时,“搜索引擎”报告和“直接访问”报告会各记录一个独立访客数据,但是网站概况中只会记录一个独立访客数
-
Java中Json解析的方法分析
本文向大家介绍Java中Json解析的方法分析,包括了Java中Json解析的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Java中Json解析的方法。分享给大家供大家参考,具体如下: 首先准备一个JSON格式的字符串 下面是一个Json解析的程序代码 PS:关于json操作,这里再为大家推荐几款比较实用的json在线工具供大家参考使用: 在线JSON代码检验、检验、美化、格式
-
JSR-310-解析可变长度的秒分数
问题内容: 有没有一种方法可以创建JSR-310格式器,该格式器能够以可变的秒分数来解析以下两个日期/时间? 要么 示例代码: 问题答案: 这样可以解决问题: JiriS的答案不正确,因为它使用,而正确的方法是使用(它也处理小数点)。差异可以在第二个系统中看到,其中错误地解析了“2015-05-07T13:20:22.000276”。 在大多数情况下,解析时比直接使用格式化程序更整洁。 使用生成器
-
php中mkdir()函数的权限问题分析
本文向大家介绍php中mkdir()函数的权限问题分析,包括了php中mkdir()函数的权限问题分析的使用技巧和注意事项,需要的朋友参考一下 问题描述: 使用以下php代码创建了一个目录,期望目录的权限是0777,实际结果是0755 mkdir('./aa/',0777); 分析与测试结果: 1.mkdir()函数指定的目录权限只能小于等于系统umask设定的默认权限。 如linux默认的uma
-
Firebase分析中的事件“ first_open”如何计数?
问题内容: 在我的Firebase分析事件中,“ first_open”显示7月7日之前有489个下载,但在游戏商店统计中显示7月7日之前有347个下载,我不知道为什么没有这些。是不同的。 first_open的定义是:- 用户首次打开应用程序时。 当用户将应用下载到设备上时,不会触发此事件,而是在用户首次使用时触发。要查看原始下载数量,请在Google Play开发者控制台或iTunesConn
-
 Perl与JS的对比分析(数组、哈希)
Perl与JS的对比分析(数组、哈希)本文向大家介绍Perl与JS的对比分析(数组、哈希),包括了Perl与JS的对比分析(数组、哈希)的使用技巧和注意事项,需要的朋友参考一下 上一篇列出了Perl中定义数组,对象的方式与JS的异同。这里继续补充数组,哈希的相关操作。 一、数组 可以对数组进行增删,插入。与JS不同的是这些函数都是全局的,JS则是挂在Array.prototype上。 1,对数组尾部的操作pop(删除最后的元素)、pu
-
 jQuery学习笔记之jQuery.fn.init()的参数分析
jQuery学习笔记之jQuery.fn.init()的参数分析本文向大家介绍jQuery学习笔记之jQuery.fn.init()的参数分析,包括了jQuery学习笔记之jQuery.fn.init()的参数分析的使用技巧和注意事项,需要的朋友参考一下 从return new jQuery.fn.init( selector, context, rootjQuery )中可以看出 参数selector和context是来自我们在调用jQuery方法时传过来的
-
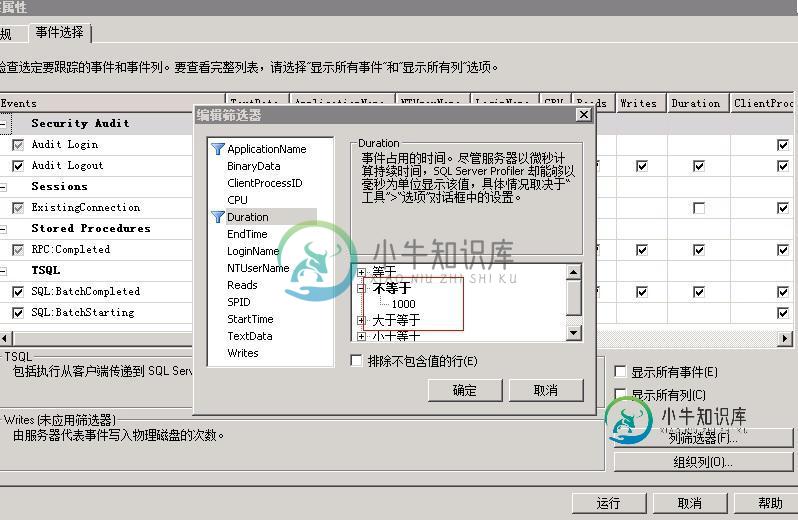 sqlserver数据库优化解析(图文剖析)
sqlserver数据库优化解析(图文剖析)本文向大家介绍sqlserver数据库优化解析(图文剖析),包括了sqlserver数据库优化解析(图文剖析)的使用技巧和注意事项,需要的朋友参考一下 下面通过图文并茂的方式展示如下: 一、SQL Profiler 事件类 Stored Procedures\RPC:Completed TSQL\SQL:BatchCompleted 事件关键字段 EventSequence、EventClass