《数据分析这么卷的吗?》专题
-
分层文件系统和卷装载
我很难理解使用卷存储将如何影响磁盘空间的使用。 我有一个图像A,它是一个基本图像,并带有我的应用程序需要的许多实用程序。我有应用程序B和C,它们是从基本图像A构建的图像。它们安装不同的语言来运行我的两个不同的应用程序。图像A为300MB,B和C各为300MB。 如果我创建10个应用程序A和B的实例,将使用多少磁盘空间? 另外,假设我正在将NFS共享挂载到所有容器,容器中的任何应用程序/进程只会将应
-
计算分层SQL数据中的子代数
问题内容: 对于一个简单的数据结构,例如: 供参考,层次树如下所示: 我想计算每个级别的孩子人数。因此,我将获得一个新列“ NoOfChildren”,如下所示: 我读了一些有关分层数据的内容,但是我不知何故卡在了parentID的多个内部联接上。也许有人可以在这里帮助我。 问题答案: 使用 CTE可以满足您的需求。 递归地遍历所有孩子,记住根。 每个根的项目。 这些再次与您的原始表一起产生结果。
-
TfidfVectorizer如何计算测试数据的分数
在scikit learn中,我们可以拟合训练数据,然后使用相同的矢量器转换测试数据。列车数据转换的输出是一个矩阵,表示给定文档中每个单词的tf idf分数。 然而,安装的矢量器如何计算新输入的分数?我猜: 一个单词在一个新文档中的分数,通过将同一单词在训练集中的文档上的分数进行聚合计算得出 我曾经尝试过从Scikit学习的源代码中推断出这个操作,但不太明白。这是我之前提到的选择之一还是完全不同的
-
数据库是什么
主要内容:关系型数据库,非关系型数据库在学习数据库之前,应该先理解什么是数据。本节先介绍数据以及数据库的概念,再对关系型数据库和非关系型数据库的优缺点进行分析。 描述事物的符号称为 数据。数据有多种表现形式,可以是数字,也可以是文字、图形、图像、声音、语言等。在数据库中数据表示记录,例如,在学生管理数据库中,记录学生的信息包括学号、姓名、性别、年龄、籍贯和联系电话等,这些信息就是数据。 信息是指对数据进行加工处理后提取的对人类社会实践
-
在Pandas数据框中转换分类数据
问题内容: 我有一个具有此类数据的数据框(列过多): 列看起来像这样: 我想像这样将列中的所有值转换为整数: 我通过以下方法解决了这一问题: 现在,我的数据框中有两列-旧列和新列,需要删除旧列。 那是不好的做法。它是可行的,但是在我的数据框中有很多列,我不想手动进行。 pythonic如何巧妙地实现呢? 问题答案: 首先,要将“分类”列转换为其数字代码,可以使用以下命令更轻松地做到这一点。 此外,
-
Spring数据可分页breaking Spring数据JPA OrderBy
我有一个简单的JpaRepository和一个finder,它返回按名为“number”的属性降序排列的记录。“number”属性也是我的实体的@Id。这很好,但是有数千条记录,所以我想返回一个页面而不是列表。 如果我将查找器更改为以下内容,则排序不再起作用。我尝试过使用可分页参数的排序功能,但不起作用。还删除了OrderByNumberDesc,但结果相同。 EDIT-添加控制器方法 以下是我的
-
Spring数据R2DBC如何查询分层数据
我是反应式编程的新手。我必须开发一个简单的Spring启动应用程序来返回一个json响应,其中包含公司及其所有子公司和员工的详细信息 创建了一个Spring Boot应用程序(Spring Webflow Spring data r2dbc) 使用以下数据库表来表示公司和子公司以及员工关系(这是一种与公司和子公司的层次关系,其中一个公司可以有N个子公司,而这些子公司中的每个子公司可以有另N个子公司
-
什么是数值积分?
一、什么是数值积分? 数值积分是计算定积分数值的方法和理论。在数学分析中,给定函数的定积分的计算不总是可行的。许多定积分不能用已知的积分公式得到精确值。数值积分是利用黎曼积分等数学定义,用数值逼近的方法近似计算给定的定积分值。借助于电子计算设备,数值积分可以快速而有效地计算复杂的积分。 数值积分的必要性源自计算函数的原函数的困难性。利用原函数计算定积分的方法建立在牛顿-莱布尼兹公式之上。然而,原函
-
为什么python中的递归这么慢?
问题内容: 因此,我在闲逛时使用了递归,我发现使用递归的循环比常规的while循环要慢得多,我想知道是否有人知道为什么。我已经包括了我下面所做的测试: 但是,在上一次测试中,我注意到如果删除该语句,则表明速度略有提高,因此我想知道if语句是否是造成循环速度差异的原因? 问题答案: 您已将函数编写为尾递归。在许多命令式和函数式语言中,这将触发尾部递归消除,在这种情况下,编译器用简单的JUMP替换了C
-
单线程的 Redis 为什么这么快?
本文向大家介绍单线程的 Redis 为什么这么快?相关面试题,主要包含被问及单线程的 Redis 为什么这么快?时的应答技巧和注意事项,需要的朋友参考一下 Redis 有多快?官方给出的答案是读写速度 10万/秒,如果说这是在单线程情况下跑出来的成绩,你会不会惊讶?为什么单线程的 Redis 速度这么快?原因有以下几点: 纯内存操作:Redis 是完全基于内存的,所以读写效率非常的高,当然 Red
-
为什么我的mongodb调用这么慢?
-
为什么是Spring的jdbcTemplate。batchUpdate()这么慢?
我正试图找到更快的批量插入方法。 我试图用jdbcTemplate.update(String sql)插入几个批次,其中sql是由StringBuilder构建的,看起来像: 批量大小正好是1000。我插入了将近100批。我用秒表查看了时间,发现了插入时间: 我很高兴,但我想让我的代码更好。 之后,我尝试使用jdbcTemplate.batch更新的方式如下: sql是什么样子的 我很失望!jd
-
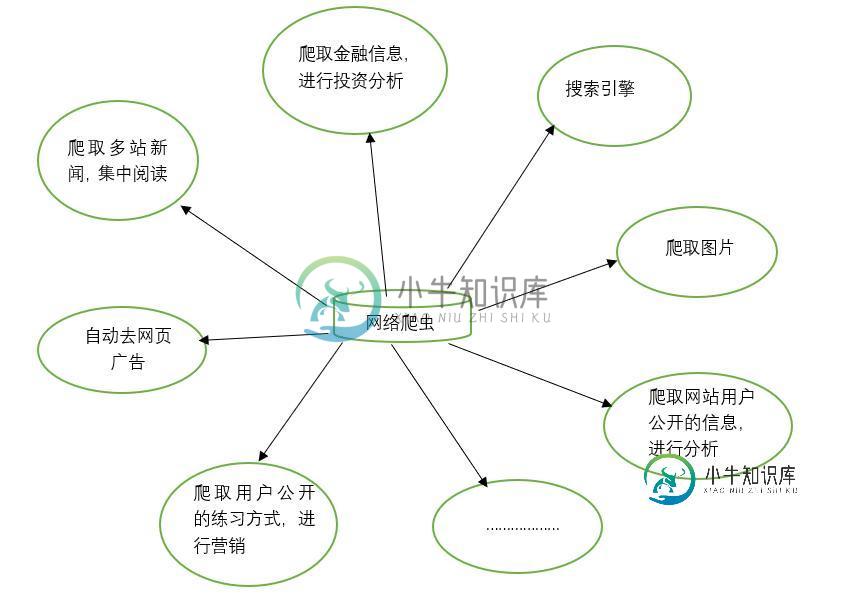 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
android Refitfit无法解析数据,将数据变为空
回调类APIInterface 得到回应
-
为什么具有分离数据源的不同持久性单元查询同一数据源?
问题内容: 我正在开发一个Webapp,它需要访问两个不同的数据库服务器(H2和Oracle)。容器是Apache Tomee 1.5.1 ,我正在使用Java EE堆栈以及其中提供的库(JSF,JPA,CDI,EJB等)。 我试图在XA事务中使用两个实体管理器从Oracle数据库中提取数据并将其转换后保留在H2中,但是无论我使用的是实体管理器,所有查询都是针对H2数据库执行的。有什么帮助吗? 编