《数据分析这么卷的吗?》专题
-
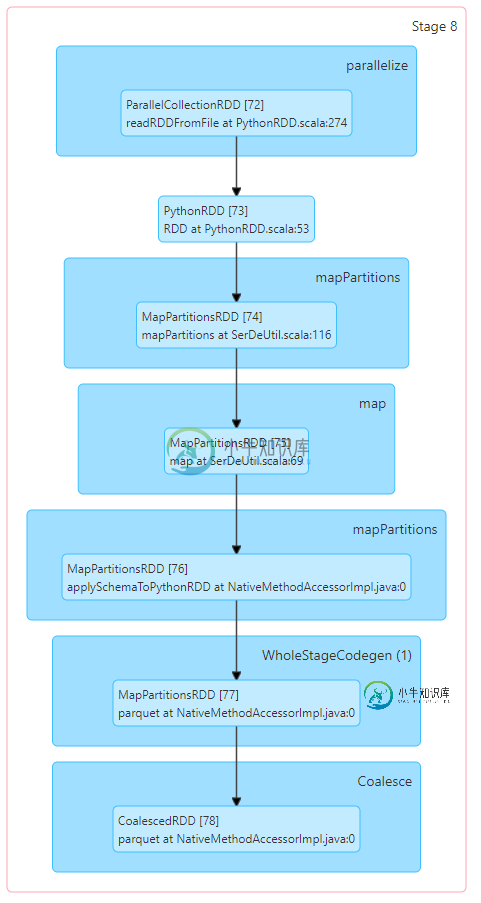 减少分区数量时,为什么spark数据帧重新分区比合并快?
减少分区数量时,为什么spark数据帧重新分区比合并快?我有一个包含100个分区的df,在保存到HDFS之前,我想减少分区的数量,因为拼花文件太小了( 它可以工作,但将过程从每个文件 2-3 秒减慢到每个文件 10-20 秒。当我尝试重新分区时: 这个过程一点也不慢,每个文件2-3秒。 为什么?在减少分区数量时,合并不应该总是更快,因为它避免了完全洗牌吗? 背景: 我将文件从本地存储导入spark集群,并将生成的数据帧保存为拼花文件。每个文件大约100
-
php使用number_format函数截取小数的方法分析
本文向大家介绍php使用number_format函数截取小数的方法分析,包括了php使用number_format函数截取小数的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了php使用number_format函数截取小数的方法。分享给大家供大家参考,具体如下: 大家知道用php的number_format()函数可以将数字按千分组. 但是它会使数字四舍五入, 那有没有办法能让
-
PHP5.6新增加的可变函数参数用法分析
本文向大家介绍PHP5.6新增加的可变函数参数用法分析,包括了PHP5.6新增加的可变函数参数用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP5.6新增加的可变函数参数用法。分享给大家供大家参考,具体如下: 今天无事,看了下PHP手册。发现PHP版本更新增加不少东西。下面就说说其中的PHP5.6更新中新增加的可变函数参数。 代码1: 代码1结果: 代码1解析: 方法函数从PH
-
为什么具有分离数据源的不同持久性单元查询同一数据源?
问题内容: 我正在开发一个Webapp,它需要访问两个不同的数据库服务器(H2和Oracle)。容器是Apache Tomee 1.5.1 ,我正在使用Java EE堆栈以及其中提供的库(JSF,JPA,CDI,EJB等)。 我试图在XA事务中使用两个实体管理器从Oracle数据库中提取数据并将其转换后保留在H2中,但是无论我使用的是实体管理器,所有查询都是针对H2数据库执行的。有什么帮助吗? 编
-
根据字段的值对数据进行分类
问题内容: 我有一张像这样的表: SQL或蜂巢中是否有一种方法可以将其转换为类似表的形式: 我不确定有没有一个词来描述这种操作…任何帮助将不胜感激! 问题答案: 这基本上是一个。您没有指定要使用的RDBMS,但是可以使用聚合函数和语句在任何数据库中获取结果: 参见带有演示的SQL Fiddle 结果:
-
Tensorflow中的卷积神经网络与自有数据进行预测
我是CNN和Tensorflow的初学者。我试图用自己的数据在tensorflow中实现卷积神经网络进行预测,但我遇到了一些问题。我将Deep MNIST for Experts教程转换为此。对于专家来说,深度分类是一种分类,但我正在尝试回归。另一个问题是,该代码为每一步提供的精度为1。错误的原因是什么?如何将此代码转换为回归? 数据集: 代码: 输出: 我对神经网络和机器学习很陌生,所以请原谅我
-
无法从在新卷中完成的恢复中加载数据库
我在使用docker-compose恢复postgres数据库卷时遇到问题。 以下是步骤: 1.备份卷: 2. 创建一个卷(该卷已具有正确的名称,可在之后与 docker 撰写一起使用): 3.还原该卷中的数据库: 然后 正在给予: 以下是合成文件的内容: postgres 映像版本与我从中转储卷的原始容器版本完全相同。 我发现了一个窍门,但也不管用: 在将数据库恢复到新卷后,我没有尝试启动新的撰
-
 ThinkPHP 3.2 数据分页代码分享
ThinkPHP 3.2 数据分页代码分享本文向大家介绍ThinkPHP 3.2 数据分页代码分享,包括了ThinkPHP 3.2 数据分页代码分享的使用技巧和注意事项,需要的朋友参考一下 TP3.2框架手册,有一个数据分页,不过每次都要写太多的代码,还有中文设置等有些麻烦,做为程序开发者,有必要整理下: O、先看效果图 一、分页方法 getpage方法可以放在TP框架的 Application/Common/Common/functio
-
SpringBoot中前端数据库(JPA)对象与数据的分离
作为一个爱好项目,我目前正在开发一个全堆栈的web应用程序。 我的技术堆栈是: MySql数据库 我已经对数据库进行了建模,并为数据库中的所有表创建了jpa实体。数据模型包括一些双向关系(多对多关系)。然后,我开始为前端创建一些APIendpoint进行交互,但我在决定如何序列化数据并将其发送到前端时遇到了一些问题。 在大多数教程和示例中,与数据库对象直接相似的对象被序列化,然后发送到前端。但我不
-
卷曲错误18-传输关闭,剩余未读数据
问题内容: 使用curl从URL检索数据时,有时(在80%的情况下) 错误18:传输关闭,剩余未读数据 然后缺少部分返回的数据。奇怪的是,当CURLOPT_RETURNTRANSFER设置为false时,这永远不会发生,即curl_exec函数不会返回数据而是直接显示内容。 可能是什么问题呢?我可以设置一些选项来避免这种行为吗? 问题答案: 我敢打赌这与同行发送的错误标题有关。我的建议是让curl
-
使用Docker for Windows备份、恢复或迁移数据卷
我正在尝试备份mysql docker容器卷的数据。我找到了这篇文章,但它还不适合我。我使用git bash,因此可以使用unix工具。 问题是,我无法访问docker VM上的卷数据(磁盘映像位置为)。 我试过了 错误地退出 <代码>/var/lib/docker/卷/ 一个空的tar文件/备份sql。焦油产生了。 是否有人成功地使用docker for windows备份和恢复了docker卷
-
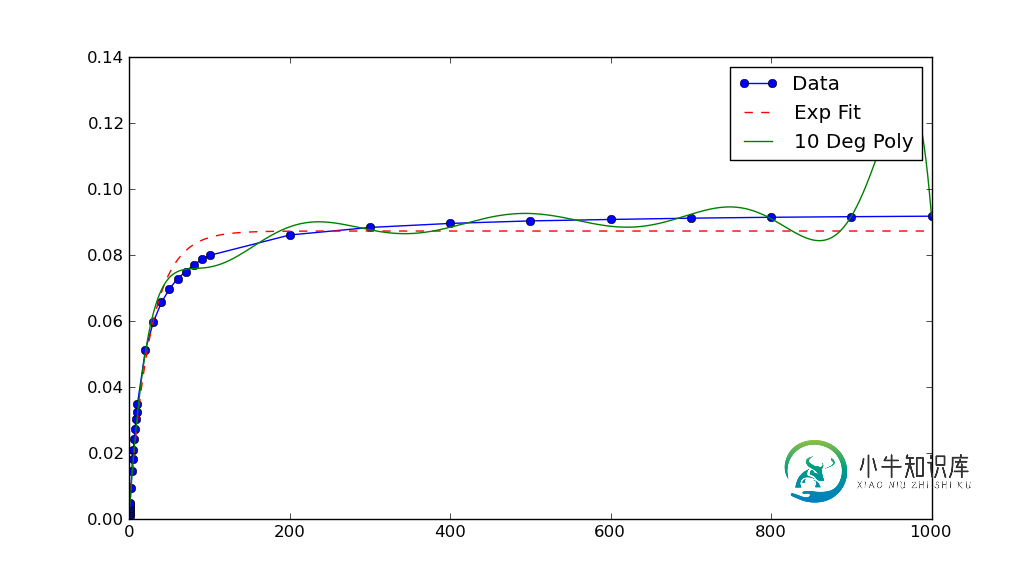 为什么会这样scipy.optimize.curve\u fit曲线拟合不符合数据?
为什么会这样scipy.optimize.curve\u fit曲线拟合不符合数据?问题内容: 我试着用指数拟合一些数据已经有一段时间了scipy.optimize.curve\u fit曲线拟合但我真的有困难。我真的看不见有什么理由不起作用,但它只是产生了一条海峡线,不知道 为什么? 任何帮助都将不胜感激 问题答案: 数值算法往往更好地工作时,没有饲料非常小(或 (大)数字。 在本例中,图表显示数据的x和y值非常小。如果 如果缩放它们,拟合效果会更好: Note that af
-
 奇安信|大数据面经|这公司现在还能去么?😂
奇安信|大数据面经|这公司现在还能去么?😂模型开发的流程,需求调研过程中有哪些人员参加,调研过程,你会输出什么文档? 如何保障数据质量(准确性)? spark有什么优缺点?在使用过程如何规避缺点? spark内存模型? spark和MR为什么会进行shuffle,如何减少shuffle? 小文件治理的方式? 主题域建设的流程? 大表join大表的优化(10亿与1千万数据关联)? 为什么存在ods穿透? 为什么离职,旧公司工作强度如何? 这
-
“列的数据太长”-为什么?
我已经编写了一个MySQL脚本,为假设的医院记录创建一个数据库,并用数据填充它。其中一个表Department有一个名为Description的列,该列声明为varchar(200)类型。对Description I执行INSERT命令时,出现错误: 错误1406:数据对于第1行的列“描述”来说太长。 我插入的所有字符串都小于150个字符。 以下是声明:< br > 下面是插入命令: 显然,这应该
-
11.6.1 怎么搜索我的数据?
在地图主界面的右上角有一个搜索的图标,点击即可进入搜索 搜索框中输入关键字点击搜索,搜索结果会展现本地数据与在线数据, 本地数据:就是自己标注在地图上的数据 在线数据:就是公共的POI数据,也可以保存为自己的数据