
为什么会这样scipy.optimize.curve\u fit曲线拟合不符合数据?

我试着用指数拟合一些数据已经有一段时间了scipy.optimize.curve\u fit曲线拟合但我真的有困难。我真的看不见有什么理由不起作用,但它只是产生了一条海峡线,不知道
为什么?
任何帮助都将不胜感激
from __future__ import division
import numpy
from scipy.optimize import curve_fit
import matplotlib.pyplot as pyplot
def func(x,a,b,c):
return a*numpy.exp(-b*x)-c
yData = numpy.load('yData.npy')
xData = numpy.load('xData.npy')
trialX = numpy.linspace(xData[0],xData[-1],1000)
# Fit a polynomial
fitted = numpy.polyfit(xData, yData, 10)[::-1]
y = numpy.zeros(len(trailX))
for i in range(len(fitted)):
y += fitted[i]*trialX**i
# Fit an exponential
popt, pcov = curve_fit(func, xData, yData)
yEXP = func(trialX, *popt)
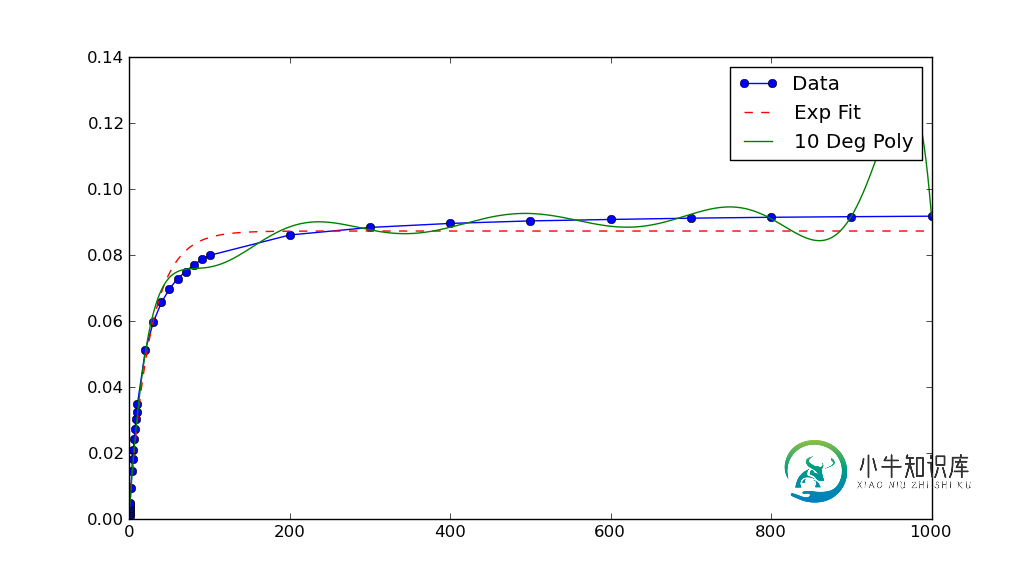
pyplot.figure()
pyplot.plot(xData, yData, label='Data', marker='o')
pyplot.plot(trialX, yEXP, 'r-',ls='--', label="Exp Fit")
pyplot.plot(trialX, y, label = '10 Deg Poly')
pyplot.legend()
pyplot.show()
xData = [1e-06, 2e-06, 3e-06, 4e-06,
5e-06, 6e-06, 7e-06, 8e-06,
9e-06, 1e-05, 2e-05, 3e-05,
4e-05, 5e-05, 6e-05, 7e-05,
8e-05, 9e-05, 0.0001, 0.0002,
0.0003, 0.0004, 0.0005, 0.0006,
0.0007, 0.0008, 0.0009, 0.001,
0.002, 0.003, 0.004, 0.005,
0.006, 0.007, 0.008, 0.009, 0.01]
yData =
[6.37420666067e-09, 1.13082012115e-08,
1.52835756975e-08, 2.19214493931e-08, 2.71258852882e-08, 3.38556130078e-08, 3.55765277358e-08,
4.13818145846e-08, 4.72543475372e-08, 4.85834751151e-08, 9.53876562077e-08, 1.45110636413e-07,
1.83066627931e-07, 2.10138415308e-07, 2.43503982686e-07, 2.72107045549e-07, 3.02911771395e-07,
3.26499455951e-07, 3.48319349445e-07, 5.13187669283e-07, 5.98480176303e-07, 6.57028222701e-07,
6.98347073045e-07, 7.28699930335e-07, 7.50686502279e-07, 7.7015576866e-07, 7.87147246927e-07,
7.99607141001e-07, 8.61398763228e-07, 8.84272900407e-07, 8.96463883243e-07, 9.04105135329e-07,
9.08443443149e-07, 9.12391264185e-07, 9.150842683e-07, 9.16878548643e-07, 9.18389990067e-07]
问题答案:
数值算法往往更好地工作时,没有饲料非常小(或
(大)数字。
在本例中,图表显示数据的x和y值非常小。如果
如果缩放它们,拟合效果会更好:
xData = np.load('xData.npy')*10**5
yData = np.load('yData.npy')*10**5
from __future__ import division
import os
os.chdir(os.path.expanduser('~/tmp'))
import numpy as np
import scipy.optimize as optimize
import matplotlib.pyplot as plt
def func(x,a,b,c):
return a*np.exp(-b*x)-c
xData = np.load('xData.npy')*10**5
yData = np.load('yData.npy')*10**5
print(xData.min(), xData.max())
print(yData.min(), yData.max())
trialX = np.linspace(xData[0], xData[-1], 1000)
# Fit a polynomial
fitted = np.polyfit(xData, yData, 10)[::-1]
y = np.zeros(len(trialX))
for i in range(len(fitted)):
y += fitted[i]*trialX**i
# Fit an exponential
popt, pcov = optimize.curve_fit(func, xData, yData)
print(popt)
yEXP = func(trialX, *popt)
plt.figure()
plt.plot(xData, yData, label='Data', marker='o')
plt.plot(trialX, yEXP, 'r-',ls='--', label="Exp Fit")
plt.plot(trialX, y, label = '10 Deg Poly')
plt.legend()
plt.show()
Note that after rescaling xData and yData, the parameters returned by
curve_fit must also be rescaled. In this case, a, b and c each must be
divided by 10**5 to obtain fitted parameters for the original data.
One objection you might have to the above is that the scaling has to be chosen
rather “carefully”. (Read: Not every reasonable choice of scale works!)
You can improve the robustness of curve_fit by providing a reasonable
initial guess for the parameters. Usually you have some a priori knowledge
about the data which can motivate ballpark / back-of-the envelope type guesses
for reasonable parameter values.
For example, calling curve_fit with
guess = (-1, 0.1, 0)
popt, pcov = optimize.curve_fit(func, xData, yData, guess)
helps improve the range of scales on which curve_fit succeeds in this case.
-
错误:C:\用户\Aidan\Anaconda3\lib\site-包\sepy\优化\minpack.py:794: OptimizeWarning:参数的协方差无法估计 类别=OptimizeWarning) ---------------------------------------------------------------------------()14 plt中的TypeErro
-
本教程演示了如何使用TensorFlow.js运算符重头构建小型玩具模型. 我们将使用多项式函数生成一些合成数据的曲线. 先决条件 本教程假设您熟悉TensorFlow.js的基本构建块介绍在TensorFlow.js中的核心概念:张量,变量和操作.我们建议在完成本教程之前完成核心概念。 运行代码 本教程重点介绍用于构建模型和其系数的TensorFlow.js代码.可以在此处找到本教程的完整代码(
-
问题内容: 我有一组近似于2D曲线的点。我想将Python与numpy和scipy配合使用,以找到近似适合这些点的三次贝塞尔曲线路径,在该路径中,我指定两个端点的确切坐标,并返回其他两个控制点的坐标。 我最初以为可以做我想做的事,但是似乎迫使曲线穿过每个数据点(因为我想您希望进行插值)。我以为我走错了路。 我的问题与此相似:如何将贝塞尔曲线拟合到一组数据?,除了他们说他们不想使用numpy。我的偏
-
问题内容: 为什么我要有一个数组并在其中放入一堆不同大小的类型… …除了和.... 文档说明: “ AnyObject可以代表任何类类型的实例” 但是,当我命令点击,或者看到这些类型的标准库定义,我看到他们都值。 这里的根本问题是什么?为什么这样设计? 问题答案: Swift中有两种类型的东西- 可以真正容纳任何东西-结构,枚举或类,以及只能容纳类。 有时似乎可以保留结构的原因是,某些特定类型会根
-
我为SHA-256编写了一个字符串: 使用此工具运行SHA-256得到的输出为,但当我自己运行它时,得到的是
-
问题内容: 对于使用6阶多项式插值非线性数据,我有一个非常具体的要求。我看过numpy / scipy例程(scipy.interpolate.InterpolatedUnivariateSpline),这些例程最多只能进行5级插值。 即使没有直接函数可以执行此操作,是否有办法在Python中复制Excel的LINEST线性回归算法?LINEST允许进行6度曲线拟合,但是我不希望将Excel用于任