
减少分区数量时,为什么spark数据帧重新分区比合并快?

我有一个包含100个分区的df,在保存到HDFS之前,我想减少分区的数量,因为拼花文件太小了(
df.coalesce(3).write.mode("append").parquet(OUTPUT_LOC)
它可以工作,但将过程从每个文件 2-3 秒减慢到每个文件 10-20 秒。当我尝试重新分区时:
df.repartition(3).write.mode("append").parquet(OUTPUT_LOC)
这个过程一点也不慢,每个文件2-3秒。
为什么?在减少分区数量时,合并不应该总是更快,因为它避免了完全洗牌吗?
背景:
我将文件从本地存储导入spark集群,并将生成的数据帧保存为拼花文件。每个文件大约100-200MB。文件位于“spark driver”机器上,我在客户端部署模式下运行spark submit。我正在驱动器中逐个读取文件:
data = read_lines(file_name)
rdd = sc.parallelize(data,100)
rdd2 = rdd.flatMap(lambda j: myfunc(j))
df = rdd2.toDF(mySchema)
df.repartition(3).write.mode("append").parquet(OUTPUT_LOC)
Spark版本是3.1.1
Spark/HDFS集群有5个工作人员,8CPU,32GB RAM
每个执行器有4个内核和15GB RAM,总共有10个执行器。
编辑:
当我使用coalesce(1)时,我得到spark.rpc.message.max大小限制违反错误,但当我使用重新分区(1)时没有。这可能是一个线索吗?
附加DAG可视化..看起来WholeStageCodegen部分在合并Dag上花费了太长时间?
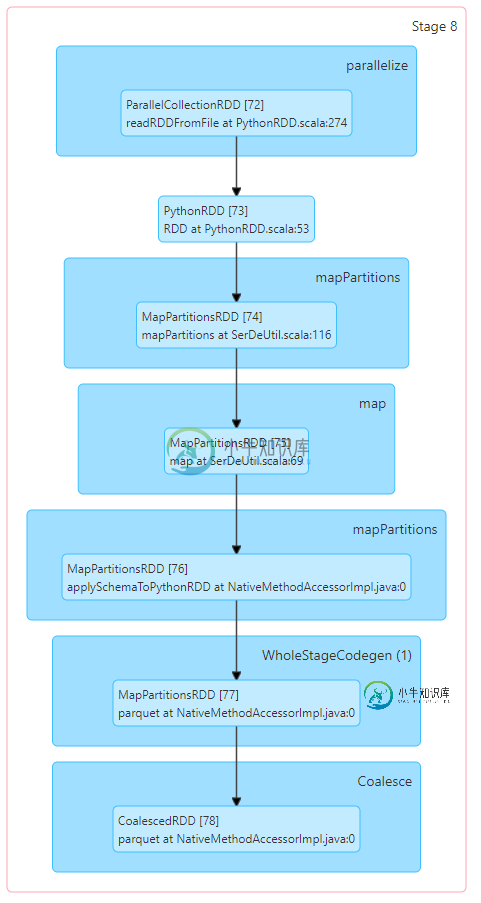
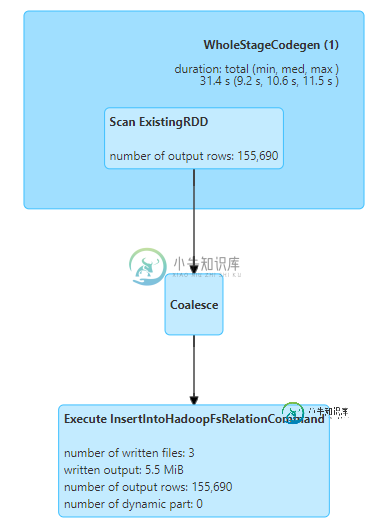
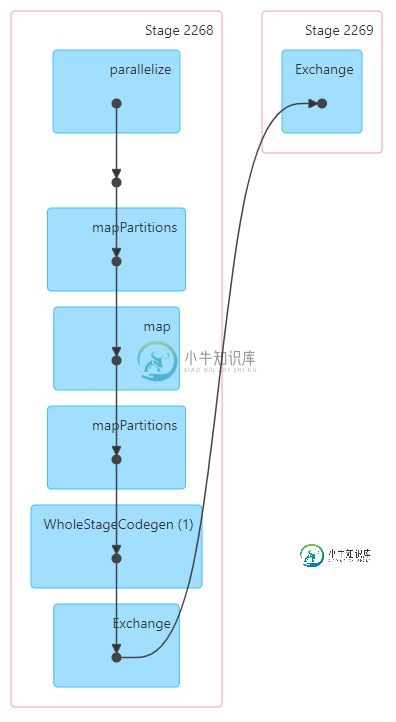
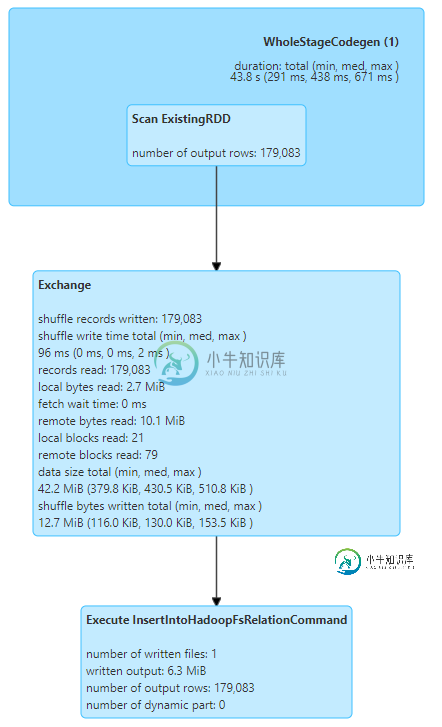
共有1个答案

如果您的数据分布不均匀,有时会发生这种情况,当您合并数据时,它会尝试通过合并小分区来减少分区,以减少完全混排,但其中一个分区中仍可能存在一些数据倾斜,并且该分区将占用大部分时间。
当您重新分区时,数据几乎均匀地分布在所有分区上,因为它会进行完全随机播放,并且所有任务几乎可以同时完成。
您可以使用spark UI来查看为什么当您合并任务时会发生什么,以及您是否看到任何单个任务长时间运行。
-
我想将数据帧“df1”划分为3列。此数据帧正好有990个针对这3列的唯一组合: 为了优化这个数据帧的处理,我想对df1进行分区,以获得990个分区,每个分区对应一个密钥: 我写了一个简单的方法来计算每个分区中的行数: 我注意到,实际上我得到的是628个带有一个或多个键值的分区,以及362个空分区。 我假设spark会以一种均匀的方式(1个键值=1个分区)重新分区,但这似乎不是这样,我觉得这种重新分
-
我需要使用 spark-sql 加载一个 Hive 表,然后对其运行一些机器学习算法。我是这样写的: 它工作得很好,但如果我想增加数据集数据帧的分区数,我该怎么做?使用普通RDD,我可以写: 我想要有N个分区。 谢谢
-
有人能解释一下将为Spark Dataframe创建的分区数量吗。 我知道对于RDD,在创建它时,我们可以提到如下分区的数量。 但是对于创建时的Spark数据帧,看起来我们没有像RDD那样指定分区数量的选项。 我认为唯一的可能性是,在创建数据帧后,我们可以使用重新分区API。 有人能告诉我在创建数据帧时,我们是否可以指定分区的数量。
-
我在这里浏览了文档:https://spark . Apache . org/docs/latest/API/python/py spark . SQL . html 它说: 重新分区:生成的DataFrame是哈希分区的 对于repartitionByRange:结果DataFrame是范围分区的 而且之前的一个问题也提到了。然而,我仍然不明白它们到底有什么不同,当选择一个而不是另一个时会有什么
-
我是scala/sark世界的新手,最近开始了一项任务,它读取一些数据,处理数据并将其保存在S3上。我阅读了一些关于stackoverflow的主题/问题,这些主题/问题涉及重分区/合并性能和最佳分区数(如本例)。假设我有正确的分区数,我的问题是,在将rdd转换为数据帧时,对它进行重新分区是个好主意吗?下面是我的代码目前的样子: 这是我打算做的(过滤后重新分区数据): 我的问题是,这样做是个好主意
-
根据Spark 1.6.3的文档,应该保留结果数据表中的分区数: 返回由给定分区表达式分区的新DataFrame,保留现有的分区数 Edit:这个问题并不涉及在Apache Spark中删除空DataFrame分区的问题(例如,如何在不产生空分区的情况下沿列重新分区),而是为什么文档所说的内容与我在示例中观察到的内容不同