《数据分析这么卷的吗?》专题
-
Oracle硬解析和软解析的区别分析
本文向大家介绍Oracle硬解析和软解析的区别分析,包括了Oracle硬解析和软解析的区别分析的使用技巧和注意事项,需要的朋友参考一下 一、摘要 Oracle硬解析和软解析是我们经常遇到的问题,所以需要考虑何时产生软解析何时产生硬解析,如何判断 SQL的执行过程 当发布一条SQL或PL/SQL命令时,Oracle会自动寻找该命令是否存在于共享池中来决定对当前的语句使用硬解析或软解析。 通常情况下,
-
这个函数中std::bad_alloc的原因是什么?
下面我写了一个C++函数,它通过一个整数向量进行循环。每通过一次,它就从所有的数字中减去最小的数字。它应该在每次传递时返回非零元素的数量(这存储在向量结果中并返回)。然而,每当我尝试运行时,我都会得到“std::bad_alloc”。当删除行“flag=true”时,错误就会消失。我将需要它工作,以便while循环中断。帮我修好这个。
-
为什么这个函数不能typecheck?
预计此函数将无法typeCheck。然而,没有解释发生这种情况的原因。在GHCI中试用时,我得到了以下输出: 为什么会出现这种情况?
-
为什么这个数组出界了?
它将把牌阵的一半分配给玩家和计算机(玩家得到前半部分,计算机得到后半部分)。现在这是先洗牌,所以是的,这似乎是公平的。 我得到的出界错误是这一行:
-
卷积神经网络中滤波器的差分
创建卷积神经网络(CNN)时(如中所述https://cs231n.github.io/convolutional-networks/)输入层与一个或多个过滤器连接,每个过滤器表示一个要素地图。这里,过滤层中的每个神经元只与输入层的几个神经元相连。在最简单的情况下,我的n个过滤器中的每一个都具有相同的维度并使用相同的步幅。 我的问题是: 如何确保过滤器学习不同的特征,尽管它们使用相同的补丁进行训练
-
Elasticsearch分析百分比
问题内容: 我正在使用Elasticsearch 1.7.3累积用于分析报告的数据。 我有一个包含文档的索引,其中每个文档都有一个名为“ duration”的数字字段(请求花费了几毫秒)和一个名为“ component”的字符串字段。可能有许多具有相同组件名称的文档。 例如。 我想生成一份报告,说明每个组件: 此组件的所有“持续时间”字段的总和。 此总和在 所有 文档的总期限中所占的百分比。在我的
-
主成分分析 PCA
目录 综述 01 使用梯度上升法求解主成分 demean 梯度上升法 02 获得前n个主成分 03 从高维数据向低维数据的映射 04 scikit-learn中的PCA 05 使用PCA降噪 手写识别例子 人脸识别 06 特征脸 特征脸 综述 “明道若昧;进道若退;夷道若颣;大方无隅;大器免成;大音希声;大象无形。” 本文采用编译器:jupyter 主成分分析 是一个非监督的机器学习算法
-
分层文件系统和卷装载
我很难理解使用卷存储将如何影响磁盘空间的使用。 我有一个图像A,它是一个基本图像,并带有我的应用程序需要的许多实用程序。我有应用程序B和C,它们是从基本图像A构建的图像。它们安装不同的语言来运行我的两个不同的应用程序。图像A为300MB,B和C各为300MB。 如果我创建10个应用程序A和B的实例,将使用多少磁盘空间? 另外,假设我正在将NFS共享挂载到所有容器,容器中的任何应用程序/进程只会将应
-
以用户名注册为例分析三种Action获取数据的方式
本文向大家介绍以用户名注册为例分析三种Action获取数据的方式,包括了以用户名注册为例分析三种Action获取数据的方式的使用技巧和注意事项,需要的朋友参考一下 1.注入属性 直接注入属性: 2.Domain Model 这是一般常用的方式 这里就不重复说明, 3.ModelDriven 第三种方法不常用,只需要了解; 其过程分为4个步骤: (1)action实现ModelDriven<User
-
使用Groovy脚本分析路径中嵌入数据的查询字符串
提前感谢您的时间和帮助。 我正在使用soapUI模拟服务,并尝试编写Groovy脚本。我收到的请求查询URL类似于: 我试图从这个URL中提取的内容是 2.16.840.1.113883.3.42.10012.100001.206,这是社区ID h0102a3727570b14038b349136f2a5fd58e0102,这是文档ID 我只能在Groovy中编码: 我不知道如何继续下去。请帮帮忙
-
springAop实现权限管理数据校验操作日志的场景分析
本文向大家介绍springAop实现权限管理数据校验操作日志的场景分析,包括了springAop实现权限管理数据校验操作日志的场景分析的使用技巧和注意事项,需要的朋友参考一下 前言 作为一个写java的使用最多的轻量级框架莫过于spring,不管是老项目用到的springmvc,还是现在流行的springboot,都离不开spring的一些操作,我在面试的时候问的最多的spring的问题就是我们在
-
计算分层SQL数据中的子代数
问题内容: 对于一个简单的数据结构,例如: 供参考,层次树如下所示: 我想计算每个级别的孩子人数。因此,我将获得一个新列“ NoOfChildren”,如下所示: 我读了一些有关分层数据的内容,但是我不知何故卡在了parentID的多个内部联接上。也许有人可以在这里帮助我。 问题答案: 使用 CTE可以满足您的需求。 递归地遍历所有孩子,记住根。 每个根的项目。 这些再次与您的原始表一起产生结果。
-
TfidfVectorizer如何计算测试数据的分数
在scikit learn中,我们可以拟合训练数据,然后使用相同的矢量器转换测试数据。列车数据转换的输出是一个矩阵,表示给定文档中每个单词的tf idf分数。 然而,安装的矢量器如何计算新输入的分数?我猜: 一个单词在一个新文档中的分数,通过将同一单词在训练集中的文档上的分数进行聚合计算得出 我曾经尝试过从Scikit学习的源代码中推断出这个操作,但不太明白。这是我之前提到的选择之一还是完全不同的
-
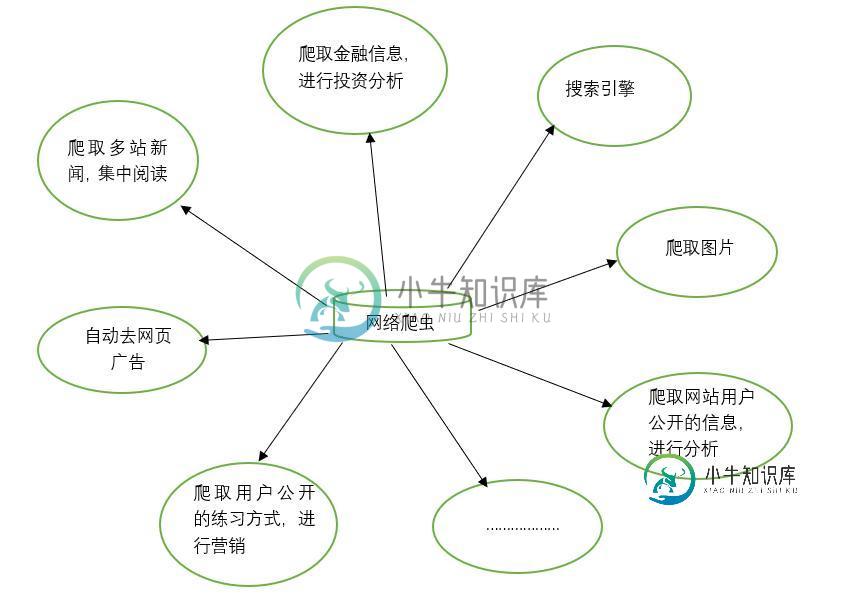 python爬虫爬取网页数据并解析数据
python爬虫爬取网页数据并解析数据本文向大家介绍python爬虫爬取网页数据并解析数据,包括了python爬虫爬取网页数据并解析数据的使用技巧和注意事项,需要的朋友参考一下 1.网络爬虫的基本概念 网络爬虫(又称网络蜘蛛,机器人),就是模拟客户端发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。 只要浏览器能够做的事情,原则上,爬虫都能够做到。 2.网络爬虫的功能 网络爬虫可以代替手工做很多事情,比如可以
-
android Refitfit无法解析数据,将数据变为空
回调类APIInterface 得到回应