
如何确定用于图像分类的卷积神经网络的参数?

我正在使用卷积神经网络(无监督特征学习检测特征Softmax回归分类器)进行图像分类。我已经阅读了Andrew NG在这方面的所有教程。(http://ufldl.stanford.edu/wiki/index.php/UFLDL_Tutorial)。
我开发的网络有一个:
- 输入层-大小8x8(64个神经元)
- 隐藏层-大小为400个神经元
- 输出层-大小3
我已经学习了使用稀疏自动编码器将输入层连接到隐藏层的权重,因此有400个不同的特征。
通过从任何输入图像(64x64)中提取连续的8x8面片并将其馈送到输入层,我得到了400个大小为57x57的特征贴图。
然后,我使用最大池和大小为19 x 19的窗口来获得400个大小为3x3的特征图。
我将此功能映射提供给softmax层,将其分为3个不同的类别。
这些参数,例如隐藏层的数量(网络深度)和每层神经元的数量,在教程中被建议,因为它们已成功地用于所有图像大小为64x64的特定数据集。
我想将其扩展到我自己的数据集,其中的图像要大得多(比如400x400)。我如何决定
>
层数。
每层神经元的数量。
池化窗口的大小(最大池化)。
共有2个答案

简而言之,您可以确定参数的可能值,并使用这些值运行一系列建模模拟,然后进行预测,以选择最佳参数值,从而使预测误差最小,模型更简单。
在数据分析方面,我们使用坚持、交叉验证和引导来确定模型参数的值,因为以无偏的方式进行预测很重要。

隐藏层的数量:所需的隐藏层数量取决于数据集的内在复杂性,这可以通过查看每个层实现的功能来理解:
>
零隐藏层允许网络仅建模线性函数。这对于大多数图像识别任务来说是不够的。
一个隐藏层允许网络建模任意复杂的函数。这对于许多图像识别任务来说是足够的。
理论上,两个隐藏层比单层没有什么好处,但是,在实践中,一些任务可能会发现额外的层是有益的。这应该谨慎对待,因为第二层可能会导致过度拟合。使用两个以上的隐藏层几乎从来没有好处仅对特别复杂的任务或有大量训练数据可用时有益(根据Evgeni Sergeev评论更新)。
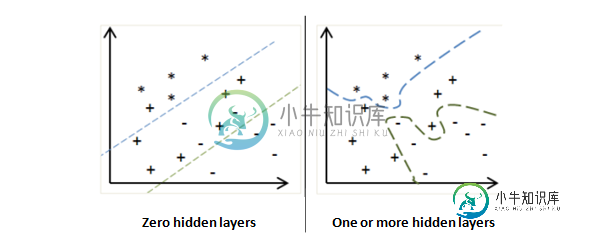
长话短说,如果你有时间,那么测试一个和两个隐藏层,看看哪个能达到最令人满意的结果。如果你没有时间,那么你应该在一个隐藏层上下注,你不会错得太远。
卷积层的数量:根据我的经验,卷积层越多越好(在合理范围内,因为每个卷积层都会将输入特征的数量减少到完全连接的层),尽管在大约两层或三层之后,精度增益变得非常小,所以你需要决定你的主要重点是泛化精度还是训练时间。这就是说,所有的图像识别任务都是不同的,所以最好的方法是简单地尝试一次增加一个卷积层的数量,直到您对结果感到满意为止。
每个隐藏层的节点数:...同样,没有神奇的公式来决定节点数,每个任务都不一样。一个粗略的指南是使用前一层大小的2/3的节点数,第一层是最终特征图大小的2/3。然而,这只是一个粗略的指南,再次取决于数据集。另一个常用的选择是从过多的节点数开始,然后通过修剪删除不必要的节点。
最大池窗口大小:我总是在卷积之后直接应用最大池,所以我可能没有资格对应该使用的窗口大小提出建议。也就是说,19x19最大池似乎过于严重,因为它实际上会丢弃大部分数据。也许您应该看看更传统的LeNet网络布局:
http://deeplearning.net/tutorial/lenet.html
https://www.youtube.com/watch?v=n6hpQwq7Inw
在这种情况下,重复执行卷积(通常为5x5或3x3),然后执行最大池化(通常使用2x2池化窗口,尽管对于大型输入图像可能需要4x4)。
总之,找到合适的网络布局的最佳方法就是进行试错测试。很多测试。没有一刀切的网络,只有您知道数据集的内在复杂性。执行大量必要测试的最有效方法是交叉验证。
-
我正在尝试运行一个CNN(卷积神经网络),具有1通道/灰度图像,大小为28x28像素。当我尝试训练模型时,它说: ValueError:图层sequential_5输入0与图层不兼容:: 预期min_ndim=4,发现ndim=3。完整形状收到:[无,28,28]
-
我在吴恩达的深度学习课程中看到了一种在图像上定位单个对象的方法:https://www.youtube.com/watch?v=GSwYGkTfOKk。据我所知,您可以将一个点绑定到对象的特定部分,将坐标:x,y作为标签y并训练CNN。 我想训练一个CNN神经网络来定位我的眼睛(而不是分类)。我拍了200张我的照片:灰度60x60像素。我标记左眼和右眼,标记眼的每个坐标被归一化为0-1。y标签为:
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Kriz
-
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络
-
我应用批量标准化技术来提高我的cnn模型的准确性。没有批量归一化的模型精度仅为46%,但应用批量归一化后,精度超过了83%,但这里出现了一个bif过拟合问题,模型给出的验证精度仅为15%。也请告诉我如何决定没有过滤器的步幅在卷积层和没有单位在登斯层
-
我正在试图理解卷积神经网络中的维度是如何表现的。在下图中,输入为带1个通道的28乘28矩阵。然后是32个5乘5的过滤器(高度和宽度步幅为2)。所以我理解结果是14乘14乘32。但是在下一个卷积层中,我们有64个5×5的滤波器(同样是步幅2)。那么为什么结果是7乘7乘64而不是7乘7乘32*64呢?我们不是将64个滤波器中的每一个应用于32个通道中的每一个吗?