
第十一章:字典
本章介绍另一个内建数据类型:字典(dictionary)。 字典是Python中最优秀的特性之一;许多高效、优雅的算法即以此为基础。
字典即映射
字典 与列表类似,但是更加通用。 在列表中,索引必须是整数;但在字典中,它们可以是(几乎)任何类型。
字典包含了一个索引的集合,被称为 键(keys) ,和一个值(values)的集合。 一个键对应一个值。这种一一对应的关联被称为 键值对(key-value pair) , 有时也被称为 项(item)。
在数学语言中,字典表示的是从键到值的 映射,所以你也可以说每一个键 “映射到” 一个值。 举个例子,我们接下来创建一个字典,将英语单词映射至西班牙语单词,因此键和值都是字符串。
dict函数生成一个不含任何项的新字典。 由于 dict 是内建函数名,你应该避免使用它来命名变量。
>>> eng2sp = dict()
>>> eng2sp
{}
花括号 {} 表示一个空字典。你可以使用方括号向字典中增加项:
>>> eng2sp['one'] = 'uno'
这行代码创建一个新项,将键 'one' 映射至值 'uno'。 如果我们再次打印该字典,会看到一个以冒号分隔的键值对:
>>> eng2sp
{'one': 'uno'}
输出的格式同样也是输入的格式。 例如,你可以像这样创建一个包含三个项的字典:
>>> eng2sp = {'one': 'uno', 'two': 'dos', 'three': 'tres'}
但是,如果你打印 eng2sp ,结果可能会让你感到意外:
>>> eng2sp
{'one': 'uno', 'three': 'tres', 'two': 'dos'}
键-值对的顺序和原来不同。 同样的例子在你的电脑上可能有不同的结果。通常来说,字典中项的顺序是不可预知的。
但这没有关系,因为字典的元素不使用整数索引来索引,而是用键来查找对应的值:
>>> eng2sp['two'] 'dos'
键 'two' 总是映射到值 'dos' ,因此项的顺序没有关系。
如果键不存在字典中,会抛出一个异常:
>>> eng2sp['four'] KeyError: 'four'
len函数也适用于字典;它返回键值对的个数:
>>> len(eng2sp) 3
in操作符也适用于字典;它可以用来检验字典中是否存在某个 键 (仅仅有这个值还不够)。
>>> 'one' in eng2sp True >>> 'uno' in eng2sp False
想要知道字典中是否存在某个值,你可以使用 values 方法,它返回值的集合,然后你可以使用 in 操作符来验证:
>>> vals = eng2sp.values() >>> 'uno' in vals True
in操作符对列表和字典采用不同的算法。 对于列表,它按顺序依次查找目标,如搜索一节所示。 随着列表的增长,搜索时间成正比增长。
对于字典,Python使用一种叫做 哈希表(hashtable) 的算法, 这种算法具备一种了不起的特性: 无论字典中有多少项,in 运算符搜索所需的时间都是一样的。我将在第二十一章的哈希表一节中具体解释背后的原理, 但是如果你不再多学习几章内容,现在去看解释的话可能很难理解。
字典作为计数器集合
假设给你一个字符串,你想计算每个字母出现的次数。 有多种方法可以使用:
- 你可以生成26个变量,每个对应一个字母表中的字母。然后你可以遍历字符串,对于 每个字符,递增相应的计数器,你可能会用到链式条件。
- 你可以生成具有26个元素的列表。然后你可以将每个字符转化为一个数字(使用内建函数
ord),使用这些数字作为列表的索引,并递增适当的计数器。 - 你可以生成一个字典,将字符作为键,计数器作为相应的值。字母第一次出现时,你应该向字典中增加一项。 这之后,你应该递增一个已有项的值。
每个方法都是为了做同一件事,但是各自的实现方法不同。
实现 是指执行某种计算的方法;有的实现更好。 例如,使用字典的实现有一个优势,即我们不需要事先知道字符串中有几种字母, 只要在出现新字母时分配空间就好了。
代码可能是这样的:
def histogram(s):
d = dict()
for c in s:
if c not in d:
d[c] = 1
else:
d[c] += 1
return d
函数名叫 histogram (直方图) ,是计数器(或是频率)集合的统计术语。
函数的第一行生成一个空字典。for 循环遍历该字符串。 每次循环,如果字符 c 不在字典中, 我们用键 c 和初始值 1 生成一个新项 (因为该字母出现了一次)。 如果 c 已经在字典中了,那么我们递增 d[c] 。
下面是运行结果:
>>> h = histogram('brontosaurus')
>>> h
{'a': 1, 'b': 1, 'o': 2, 'n': 1, 's': 2, 'r': 2, 'u': 2, 't': 1}
histogram函数表明字母 'a' 和 'b' 出现了一次, 'o' 出现了两次,等等。
字典类有一个 get 方法,接受一个键和一个默认值作为参数。 如果字典中存在该键,则返回对应值;否则返回传入的默认值。例如:
>>> h = histogram('a')
>>> h
{'a': 1}
>>> h.get('a', 0)
1
>>> h.get('b', 0)
0
我们做个练习,试着用 get 简化 histogram 函数。你应该能够不再使用 if 语句。
循环和字典
在 for 循环中使用字典会遍历其所有的键。 例如,下面的 print_hist 会打印所有键与对应的值:
def print_hist(h):
for c in h:
print(c, h[c])
输出类似:
>>> h = histogram('parrot')
>>> print_hist(h)
a 1
p 1
r 2
t 1
o 1
重申一遍,字典中的键是无序的。 如果要以确定的顺序遍历字典,你可以使用内建方法 sorted:
>>> for key in sorted(h): ... print(key, h[key]) a 1 o 1 p 1 r 2 t 1
逆向查找
给定一个字典 d 以及一个键 t ,很容易找到相应的值 v = d[k] 。 该运算被称作 查找(lookup) 。
但是如果你想通过 v 找到 k 呢? 有两个问题:第一,可能有不止一个的键其映射到值v。 你可能可以找到唯一一个,不然就得用 list 把所有的键包起来。 第二,没有简单的语法可以完成 逆向查找(reverse lookup);你必须搜索。
下面这个函数接受一个值并返回映射到该值的第一个键:
def reverse_lookup(d, v):
for k in d:
if d[k] == v:
return k
raise LookupError()
该函数是搜索模式的另一个例子,但是它使用了一个我们之前没有见过的特性,raise。 raise 语句 能触发异常,这里它触发了 ValueError,这是一个表示查找操作失败的内建异常。
如果我们到达循环结尾,这意味着字典中不存在 v 这个值,所以我们触发一个异常。
下面是一个成功逆向查找的例子:
>>> h = histogram('parrot')
>>> key = reverse_lookup(h, 2)
>>> key
'r'
和一个失败的例子:
>>> key = reverse_lookup(h, 3) Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 5, in reverse_lookup LookupError
你触发的异常和 Python 触发的产生效果一样:都打印一条回溯和错误信息。
raise语句接受一个详细的错误信息作为可选的实参。 例如:
>>> raise LookupError('value does not appear in the dictionary')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
LookupError: value does not appear in the dictionary
逆向查找比正向查找慢得多; 如果你频繁执行这个操作或是字典很大,程序性能会变差。
字典和列表
在字典中,列表可以作为值出现。 例如,如果你有一个从字母映射到频率的字典, 而你想倒转它; 也就是生成一个从频率映射到字母的字典。 因为可能有些字母具有相同的频率,所以在倒转字典中的每个值应该是一个字母组成的列表。
下面是一个倒转字典的函数:
def invert_dict(d):
inverse = dict()
for key in d:
val = d[key]
if val not in inverse:
inverse[val] = [key]
else:
inverse[val].append(key)
return inverse
每次循环,key 从 d 获得一个键和相应的值 val 。 如果 val 不在 inverse 中,意味着我们之前没有见过它, 因此我们生成一个新项并用一个 单元素集合(singleton) (只包含一个元素的列表)初始化它。 否则就意味着之前已经见过该值,因此将其对应的键添加至列表。
举个例子:
>>> hist = histogram('parrot')
>>> hist
{'a': 1, 'p': 1, 'r': 2, 't': 1, 'o': 1}
>>> inverse = invert_dict(hist)
>>> inverse
{1: ['a', 'p', 't', 'o'], 2: ['r']}
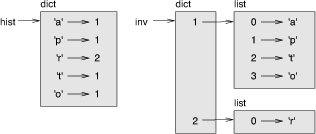
图11-1:状态图
图11-1:状态图是关于 hist 与 inverse 的状态图。字典用标有类型dict的方框表示,方框中是键值对。如果值是整数、浮点数或字符串, 我就把它们画在方框内部,但我通常把列表画在方框外面,目的只是为了不让图表变复杂。
如本例所示,列表可以作为字典中的值,但是不能是键。 下面演示了这样做的结果:
>>> t = [1, 2, 3] >>> d = dict() >>> d[t] = 'oops' Traceback (most recent call last): File "<stdin>", line 1, in ? TypeError: list objects are unhashable
我之前提过,字典使用哈希表实现,这意味着键必须是 可哈希的(hashable) 。
哈希(hash) 函数接受一个值(任何类型)并返回一个整数。 字典使用被称作哈希值的这些整数,来存储和查找键值对。
如果键是不可变的,那么这种实现可以很好地工作。 但是如果键是可变的,如列表,那么就会发生糟糕的事情。 例如,当你生成一个键值对时,Python哈希该键并将其存储在相应的位置。 如果你改变键然后再次哈希它,它将被存储到另一个位置。 在那种情况下,对于相同的键,你可能有两个值, 或者你可能无法找到一个键。 无论如何,字典都不会正确的工作。
这就是为什么键必须是可哈希的,以及为什么如列表这种可变类型不能作为键。 绕过这种限制最简单的方法是使用元组, 我们将在下一章中介绍。
因为字典是可变的,因此它们不能作为键,但是 可以 用作值。
备忘录
如果你在 再举一例一节中接触过 fibonacci 函数,你可能注意到输入的实参越大,函数运行就需要越多时间。 而且运行时间增长得非常快。
要理解其原因,思考 图11-2:调用图,它展示了当 n=4 时 fibonacci 的 调用图(call graph) :
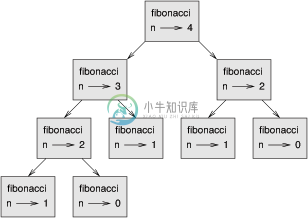
图11-2:调用图
调用图中列出了一系列函数栈帧,每个栈帧之间通过线条与调用它的函数栈帧相连。 在图的顶端,n=4 的 fibonacci 调用 n=3 和 n=2 的 fibonacci 。 接着,n=3 的 fibonacci 调用 n=2 和 n=1 的 fibonacci 。以此类推。
数数 fibonacci(0) 和 fibonacci(1) 总共被调用了几次。 对该问题,这不是一个高效的解,并且随着实参的变大会变得更糟。
一个解决办法是保存已经计算过的值,将它们存在一个字典中。 存储之前计算过的值以便今后使用,它被称作 备忘录(memo) 。 下面是使用备忘录(memoized)的 fibonacci 的实现:
known = {0:0, 1:1}
def fibonacci(n):
if n in known:
return known[n]
res = fibonacci(n-1) + fibonacci(n-2)
known[n] = res
return res
known是一个字典,记录了我们已经计算过的斐波纳契数字。 它一开始包含两个项:0映射到0,1映射到1。
当 fibonacci 被调用时,它先检查 known 。 如果结果存在,则立即返回。 否则,它必须计算新的值,将其加入字典,并返回它。
将两个版本的 fibonacci 函数比比看,你就知道后者快了很多。
全局变量
在前面的例子中,known 是在函数的外部创建的, 因此它属于被称作 __main__ 的特殊帧。 因为 __main__ 中的变量可以被任何函数访问,它们也被称作 全局变量(global) 。 与函数结束时就会消失的局部变量不同,不同函数调用时全局变量一直都存在。
全局变量普遍用作 标记(flag); 也就是说明(标记)一个条件是否为真的布尔变量。 例如,一些程序使用一个被称作 verbose 的标记来控制输出的丰富程度:
verbose = True
def example1():
if verbose:
print('Running example1')
如果你试图对一个全局变量重新赋值,结果可能出乎意料。 下面的例子本应该记录函数是否已经被调用过了:
been_called = False
def example2():
been_called = True # 错误
但是如果你运行它,你会发现 been_called 的值并未发生改变。 问题在于 example2 生成了一个新的被称作 been_called 的局部变量。 当函数结束的时候,该局部变量也消失了,并且对全局变量没有影响。
要在函数内对全局变量重新赋值,你必须在使用之前 声明(declare) 该全局变量:
been_called = False
def example2():
global been_called
been_called = True
global 语句 告诉编译器,“在这个函数里,当我说 been_called 时,我指的是那个全局变量,别生成局部变量”。
下面是一个试图更新全局变量的例子:
count = 0
def example3():
count = count + 1 # 错误
一旦运行,你会发现:
UnboundLocalError: local variable 'count' referenced before assignment
Python默认 count 是局部变量,在这个假设下,你这是在未写入任何东西前就试图读取。 解决方法还是声明 count 是全局变量。
def example3():
global count
count += 1
如果全局变量是可变的,你可以不加声明地修改它:
known = {0:0, 1:1}
def example4():
known[2] = 1
因此你可以增加、删除和替代全局列表或者字典的元素, 但是如果你想对变量重新赋值,你必须声明它:
def example5():
global known
known = dict()
全局变量有时是很有用的,但如果你的程序中有很多全局变量,而且修改频繁, 这样会增加程序调试的难度。
调试
当你操作较大的数据集时,通过打印并手工检查数据来调试很不方便。 下面是针对调试大数据集的一些建议:
缩小输入:
如果可能,减小数据集合的大小。 例如,如果程序读入一个文本文件,从前10行开始分析,或是找到更小的样例。 你可以选择编辑读入的文件,或是(最好)修改程序使它只读入前 n 行。
如果出错了,你可以将 n 缩小为会导致该错误的最小值,然后在查找和解决错误的同时,逐步增加 n 的值。
检查摘要和类型:
考虑打印数据的摘要,而不是打印并检查全部数据集合: 例如,字典中项的数目或者数字列表的总和。
运行时错误的一个常见原因,是值的类型不正确。 为了调试此类错误,打印值的类型通常就足够了。
编写自检代码:
有时你可以写代码来自动检查错误。 例如,如果你正在计算数字列表的平均数,你可以检查其结果是不是大于列表中最大的元素,或者小于最小的元素。 这被称 作“合理性检查”,因为它能检测出“不合理的”结果。
另一类检查是比较两个不同计算的结果,来看一下它们是否一致。这被称作“一致性检查”。
格式化输出:
格式化调试输出能够更容易定位一个错误。 我们在调试一节中看过一个示例。pprint模块提供了一个pprint函数,它可以更可读的格式显示内建类型(pprint代表 “pretty print”)。
重申一次,你花在搭建脚手架上的时间能减少你花在调试上的时间。
术语表
映射(mapping):
一个集合中的每个元素对应另一个集合中的一个元素的关系。
字典(dictionary):
将键映射到对应值的映射。
键值对(key-value pair):
键值之间映射关系的呈现形式。
项(item):
在字典中,这是键值对的另一个名称。
键(key):
字典中作为键值对第一部分的对象。
值(value):
字典中作为键值对第二部分的对象。它比我们之前所用的“值”一词更具体。
实现(implementation):
执行计算的一种形式。
哈希表(hashtable):
用来实现Python字典的算法。
哈希函数(hash function):
哈希表用来计算键的位置的函数。
可哈希的(hashable):
具备哈希函数的类型。诸如整数、浮点数和字符串这样的不可变类型是可哈希的;诸如列表和字典这样的可变对象是不可哈希的。
查找(lookup):
接受一个键并返回相应值的字典操作。
逆向查找(reverse lookup):
接受一个值并返回一个或多个映射至该值的键的字典操作。
raise语句:
专门印发异常的一个语句。
单元素集合(singleton):
只有一个元素的列表(或其他序列)。
调用图(call graph):
绘出程序执行过程中创建的每个栈帧的调用图,其中的箭头从调用者指向被调用者。
备忘录(memo):
一个存储的计算值,避免之后进行不必要的计算。
全局变量(global variable):
在函数外部定义的变量。任何函数都可以访问全局变量。
global语句:
将变量名声明为全局变量的语句。
标记(flag):
用于说明一个条件是否为真的布尔变量。
声明(declaration):
类似global这种告知解释器如何处理变量的语句。
练习题
习题11-1
编写一函数,读取 words.txt 中的单词并存储为字典中的键。值是什么无所谓。 然后,你可以使用 in 操作符检查一个字符串是否在字典中。
如果你做过习题10-10,可以比较一下 in 操作符 和二分查找的速度。
习题11-2
查看字典方法 setdefault 的文档,并使用该方法写一个更简洁的 invert_dict 。
答案: http://thinkpython2.com/code/invert_dict.py 。
习题11-3
将习题6-2中的Ackermann函数备忘录化(memoize),看看备忘录化(memoization)是否可以支持解决更大的参数。没有提示!
答案: http://thinkpython2.com/code/ackermann_memo.py 。
习题11-4
如果你做了习题10-7,你就已经写过一个叫 has_duplicates 的函数,它接受一个列表作为参数,如果其中有某个对象在列表中出现不止一次就返回True。
用字典写个更快、更简单的版本。
答案: http://thinkpython2.com/code/has_duplicates.py 。
习题11-5
两个单词如果反转其中一个就会得到另一个,则被称作“反转对”(参见习题8-5中的 rotate_word )。
编写一程序,读入单词表并找到所有反转对。
答案: http://thinkpython2.com/code/rotate_pairs.py 。
习题11-6
下面是取自 Car Talk 的另一个字谜题(http://www.cartalk.com/content/puzzlers):
这是来自一位名叫Dan O’Leary的朋友的分享。他有一次碰到了一个常见的单音节、有五个字母的单词,它具备以下独特的特性。当你移除第一个字母时,剩下的字母组成了原单词的同音词,即发音完全相同的单词。将第一个字母放回,然后取出第二个字母,结果又是原单词的另一个同音词。那么问题来了,这个单词是什么?
接下来我给大家举一个不满足要求的例子。我们来看一个五个字母的单词“wrack”。W-R-A-C-K,常用短句为“wrack with pain”。如果我移除第一个字母,就剩下了一个四个字母的单词“R-A-C-K”。可以这么用,“Holy cow, did you see the rack on that buck! It must have been a nine-pointer!”它是一个完美的同音词。如果你把“w”放回去,移除“r”,你得到的单词是“wack”。这是一个真实的单词,但并不是前两个单词的同音词。
不过,我们和Dan知道至少有一个单词是满足这个条件的,即移除前两个字母中的任意一个,将会得到两个新的由四个字母组成的单词,而且发音完全一致。那么这个单词是什么呢?
你可以使用习题11-1中的字典检查某字符串是否出现在单词表中。
你可以使用CMU发音字典检查两个单词是否为同音词。从 http://www.speech.cs.cmu.edu/cgi-bin/cmudict 或 http://thinkpython2.com/code/c06d 即可下载。你还可以下载 http://thinkpython2.com/code/pronounce.py 这个脚本,其中提供了一个名叫 read_dictionary 的函数,可以读取发音字典,并返回一个将每个单词映射至描述其主要梵音的字符串的Python字典。
编写一个程序,找到满足字谜题条件的所有单词。