
第十二章:元组
本章介绍另一个内置类型:元组,同时说明如何结合使用列表、字典和元组。我还将介绍一个有用的特性,即可变长度参数列表,以及汇集和分散操作符。
说明:“tuple”并没有统一的发音,有些人读成“tuh-ple”,音律类似于“supple”; 而在编程的语境下,大部分读成“too-ple”,音律类似于“quadruple”。
元组是不可变的
元组是一组值的序列。 其中的值可以是任意类型, 使用整数索引, 因此从这点上看,元组与列表非常相似。 二者不同之处在于元组的不可变性。
语法上,元组是用逗号隔开一系列值:
>>> t = 'a', 'b', 'c', 'd', 'e'
虽然并非必须,元组通常用括号括起来:
>>> t = ('a', 'b', 'c', 'd', 'e')
使用单一元素创建元组时,需要在结尾处添加一个逗号:
>>> t1 = 'a', >>> type(t1) <class 'tuple'>
将值放置在括号中并不会创建元组:
>>> t2 = ('a')
>>> type(t2)
<class 'str'>
另一个创建元组的方法是使用内建函数 tuple 。 在没有参数传递时,它会创建一个空元组:
>>> t = tuple() >>> t ()
如果实参是一个序列(字符串、列表或者元组),结果将是一个包含序列内元素的元组。
>>> t = tuple('lupins')
>>> t
('l', 'u', 'p', 'i', 'n', 's')
因为 tuple 是内建函数名,所以应该避免将它用作变量名。
列表的大多数操作符同样也适用于元组。 方括号运算符将索引一个元素:
>>> t = ('a', 'b', 'c', 'd', 'e')
>>> t[0]
'a'
切片运算符选取一个范围内的元素:
>>> t[1:3]
('b', 'c')
但是,如果你试图更改元组中的一个元素,会得到错误信息:
>>> t[0] = 'A' TypeError: object doesn't support item assignment
因为元组是不可变的,你无法改变其中的元素。 但是可以使用其他元组替换现有元组:
>>> t = ('A',) + t[1:]
>>> t
('A', 'b', 'c', 'd', 'e')
这个语句创建了一个新元组,然后让 t 引用该元组。
关系型运算符也适用于元组和其他序列; Python 会首先比较序列中的第一个元素,如果它们相等,就继续比较下一组元素,以此类推,直至比值不同。 其后的元素(即便是差异很大)也不会再参与比较。
>>> (0, 1, 2) < (0, 3, 4) True >>> (0, 1, 2000000) < (0, 3, 4) True
元组赋值
两个变量互换值的操作通常很有用。 按照传统的赋值方法,你需要使用一个临时变量。 例如,为了交换 a 和 b 的值:
>>> temp = a >>> a = b >>> b = temp
这个方法很繁琐;通过元组赋值来实现更为优雅:
>>> a, b = b, a
等号左侧是变量组成的元组;右侧是表达式组成的元组。 每个值都被赋给了对应的变量。 变量被重新赋值前,将先对右侧的表达式进行求值。
左侧的变量数和右侧值的数目必须相同:
>>> a, b = 1, 2, 3 ValueError: too many values to unpack
一般来说,右侧可以是任意类型(字符串、列表或者元组)的序列。 例如, 将一个电子邮箱地址分成用户名和域名, 你可以这样做:
>>> addr = 'monty@python.org'
>>> uname, domain = addr.split('@')
split 函数返回的对象是一个包含两个元素的列表; 第一个元素被赋给了变量 uname ,第二个被赋给了 domain 。
>>> uname 'monty' >>> domain 'python.org'
元组作为返回值
严格地说,一个函数只能返回一个值,但是如果这个返回值是元组,其效果等同于返回多个值。 例如,你想对两个整数做除法,计算出商和余数,依次计算出x/y和 x%y 的效率并不高。同时计算出这两个值更好。
内建函数 divmod 接受两个实参,返回包含两个值的元组:商和余数。 你可以使用元组来存储返回值:
>>> t = divmod(7, 3) >>> t (2, 1)
或者使用元组赋值分别存储它们:
>>> quot, rem = divmod(7, 3) >>> quot 2 >>> rem 1
下面是一个返回元组作为结果的函数例子:
def min_max(t):
return min(t), max(t)
max和 min 是用于找出一组元素序列中最大值和最小值的内建函数。 min_max函数同时计算出这两个值,并返回二者组成的元组。
可变长度参数元组
函数可以接受可变数量的参数。 以 “*” 开头的形参将输入的参数 汇集 到一个元组中。 例如,printall 可以接受任意数量的参数,并且将它们打印出来:
def printall(*args):
print(args)
汇集形参可以使用任意名字,但是习惯使用 args。 以下是这个函数的调用效果:
>>> printall(1, 2.0, '3') (1, 2.0, '3')
与汇集相对的,是 分散(scatter) 。 如果你有一个值序列,并且希望将其作为多个参数传递给一个函数, 你可以使用运算符*。 例如,divmod 只接受两个实参; 元组则无法作为参数传递进去:
>>> t = (7, 3) >>> divmod(t) TypeError: divmod expected 2 arguments, got 1
但是如果你将这个元组分散,它就可以被传递进函数:
>>> divmod(*t) (2, 1)
许多内建函数使用了可变长度参数元组。 例如,max 和 min 就可以接受任意数量的实参:
>>> max(1, 2, 3) 3
但是 sum 不行:
>>> sum(1, 2, 3) TypeError: sum expected at most 2 arguments, got 3
我们做个练习,编写一个叫做 small 的函数,使它能够接受任何数量的实参并返回它们的和。
列表和元组
zip是一个内建函数,可以接受将两个或多个序列组,并返回一个元组列表, 其中每个元组包含了各个序列中相对位置的一个元素。 这个函数的名称来自名词拉链(zipper),后者将两片链齿连接拼合在一起。
下面的示例对一个字符串和列表使用 zip 函数:
>>> s = 'abc' >>> t = [0, 1, 2] >>> zip(s, t) <zip object at 0x7f7d0a9e7c48>
输出的结果是一个 zip 对象,包含了如何对其中元素进行迭代的信息。 zip 函数最常用于 for 循环:
>>> for pair in zip(s, t):
... print(pair)
...
('a', 0)
('b', 1)
('c', 2)
zip对象是迭代器的一种,即任何能够按照某个序列迭代的对象。 迭代器在某些方面与列表非常相似,但不同之处在于,你无法通过索引来选择迭代器中的某个元素。
如果你想使用列表操作符和方法,你可以通过 zip 对象创建一个列表:
>>> list(zip(s, t))
[('a', 0), ('b', 1), ('c', 2)]
结果就是一个包含若干元组的列表;在这个例子中,每个元组又包含了字符串中的一个字符和列表 中对应的一个元素。
如果用于创建的序列长度不一,返回对象的长度以最短序列的长度为准。
>>> list(zip('Anne', 'Elk'))
[('A', 'E'), ('n', 'l'), ('n', 'k')]
你可以在 for 循环中使用元组赋值,遍历包含元组的列表:
t = [('a', 0), ('b', 1), ('c', 2)]
for letter, number in t:
print(number, letter)
每次循环时,Python 会选择列表中的下一个元组, 并将其内容赋给 letter 和 number 。循环的输出是:
0 a 1 b 2 c
如果将 zip 、for 循环和元组赋值结合起来使用,你会得到一个可以同时遍历两个(甚至多个)序列的惯用法。 例如,has_match 接受两个序列 t1 和 t2 , 如果存在索引 i 让 t1[i] == t2[i] ,则返回 True :
def has_match(t1, t2):
for x, y in zip(t1, t2):
if x == y:
return True
return False
如果需要遍历一个序列的元素以及其索引号,你可以使用内建函数 enumerate :
for index, element in enumerate('abc'):
print(index, element)
enumerate的返回结果是一个枚举对象(enumerate object),可迭代一个包含若干个对的序列; 每个对包含了(从0开始计数)的索引和给定序列中的对应元素。 在这个例子中,输出结果是:
0 a 1 b 2 c
和前一个示例的结果一样。
字典和元组
字典有一个叫做 items 的方法,它返回由多个元组组成的序列,其中每个元组是一个键值对。
>>> d = {'a':0, 'b':1, 'c':2}
>>> t = d.items()
>>> t
dict_items([('c', 2), ('a', 0), ('b', 1)])
其结果是一个 dict_items 对象,这是一个对键值对进行迭代的迭代器。 你可以在 for 循环中像这样使用它:
>>> for key, value in d.items(): ... print(key, value) ... c 2 a 0 b 1
由于是字典生成的对象,你应该猜到了这些项是无序的。
另一方面,你可以使用元组的列表初始化一个新的字典:
>>> t = [('a', 0), ('c', 2), ('b', 1)]
>>> d = dict(t)
>>> d
{'a': 0, 'c': 2, 'b': 1}
将 dict 和 zip 结合使用,可以很简洁地创建一个字典:
>>> d = dict(zip('abc', range(3)))
>>> d
{'a': 0, 'c': 2, 'b': 1}
字典的 update 方法也接受元组列表,并将其作为键值对添加到已有的字典中去。
在字典中使用元组作为键(主要因为无法使用列表)的做法很常见。 例如,一个电话簿可能会基于用户的姓-名对,来映射至号码。 假设我们已经定义了 last 、 first 和 number 三个变量, 我们可以这样实现映射:
directory[last, first] = number
方括号中的表达式是一个元组。我们可以通过元组赋值来遍历这个字典:
for last, first in directory:
print(first, last, directory[last,first])
该循环遍历电话簿中的键,它们其实是元组。 循环将元组的元素赋给 last 和 first , 然后打印出姓名和对应的电话号码。
在状态图中有两种表示元组的方法。更详细的版本是, 索引号和对应元素就像列表一样存放在元组中。例如,元组 ('Cleese', 'John') 可像图12-1:状态图中那样存放。

图12-1:状态图
在更大的图表中,你不会想要再描述这些细节。 例如,该电话簿的状态图可能如图12-2:状态图所示。
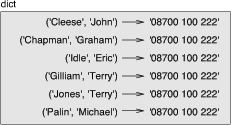
图12-2:状态图
在上图中,为了方便起见,使用 Python 语法表示元组。 此图中的电话号码是 BBC 的投诉热线,请不要拨打它。
序列嵌套
我已经介绍了包含元组的列表, 但本章几乎所有示例也适用于列表嵌套列表、元组嵌套元组,以及元组嵌套列表。 为了避免穷举这类可能的嵌套组合,介绍序列嵌套有时更简单一些。
在很多情况下,不同类型的序列(字符串、列表、元组)可以互换使用。 因此,我们该如何选用合适的序列呢?
首先,显而易见的是,字符串比其他序列的限制更多,因为它的所有元素都必须是字符,且字符串不可变。如果你希望能够改变字符串中的字符,使用列表嵌套字符或许更合适。
列表比元组更常用,主要是因为它们是可变的。 但是有些情况下,你可能更倾向于使用元组:
- 在一些情况下(例如
return语句),从句式上生成一个元组比列表要简单。 - 如果你想使用一个序列作为字典的键,那么你必须使用元组或字符串这样的不可变类型。
- 如果你向函数传入一个序列作为参数,那么使用元组可以降低由于别名而产生的意外行为的可能性。
由于元组的不可变性,它们没有类似(sort) 和 (reverse)这样修改现有列表的方法。 然而 Python 提供了内建函数 sorted 和 reversed ,前者可以接受任意序列,并返回一个正序排列的新列表,后者则接受一个序列,返回一个可逆序迭代列表的迭代器。
调试
列表、字典和元组都是数据结构 (data structures);本章中,我们开始接触到复合数据结构(compound data structures),如:列表嵌套元组,以及使用元组作为键、列表作为值的字典。 复合数据结构非常实用,但是使用时容易出现所谓的形状错误(shape errors),也就是由于数据结构的类型、大小或结构问题而引发的错误。 例如,当你希望使用一个整数组成的列表时,我却给了你一个纯粹的整数(没有放在列表中),就会出现错误。
为了方便调试这类错误,我编写了一个叫做 structshape 的模块, 它提供了一个同名函数,可以接受任意类型的数据结构作为实参,然后返回一个描述它形状的字符串。 你可以从 http://thinkpython2.com/code/structshape.py 下载该模块。
下面是用该模块调试一个简单列表的示例:
>>> from structshape import structshape >>> t = [1, 2, 3] >>> structshape(t) 'list of 3 int'
更完美的程序应该显示 “list of 3 ints”,但是忽略英文复数使程序变得简单的多。 我们再看一个列表嵌套的例子:
>>> t2 = [[1,2], [3,4], [5,6]] >>> structshape(t2) 'list of 3 list of 2 int'
如果列表内的元素不是相同类型,structshape 会按照类型的顺序进行分组:
>>> t3 = [1, 2, 3, 4.0, '5', '6', [7], [8], 9] >>> structshape(t3) 'list of (3 int, float, 2 str, 2 list of int, int)'
下面是一个元组列表的例子:
>>> s = 'abc' >>> lt = list(zip(t, s)) >>> structshape(lt) 'list of 3 tuple of (int, str)'
下面是一个字典的例子,其中包含三个将整数映射至字符串的项:
>>> d = dict(lt) >>> structshape(d) 'dict of 3 int->str'
如果你在追踪数据结构的类型上遇到了困难,可以使用 structshape 来帮助分析。
术语表
元组(tuple):
一个由多个元素组成的不可变序列。
元组赋值(tuple assignment):
一种赋值方式,等号右侧为一个序列,等号左侧为一个变量组成的元组。右侧的表达式先求值,然后其元素被赋值给左侧元组中对应的变量。
汇集(gather):
组装可变长度实参元组的一种操作。
分散(scatter):
将一个序列变换成一个参数列表的操作。
zip 对象:
使用内建函数 zip 所返回的结果;它是一个可以对元组序列进行迭代的对象。迭代器(iterator):
一个可以对序列进行迭代的对象,但是并不提供列表操作符和方法。
数据结构(data structure):
一个由关联值组成的数据集合,通常组织成列表、字典、元组等。
形状错误(shape error):
由于某个值的形状出错,而导致的错误;即拥有错误的类型或大小。
练习题
习题12-1
编写一个名为 most_frequent 的函数,接受一个字符串,并按字符出现频率降序打印字母。 找一些不同语言的文本样本,来试试看不同语言之间字母频率的区别。 将你的结果和 http://en.wikipedia.org/wiki/Letter_frequencies 页面上的表格进行比较。
答案: http://thinkpython2.com/code/most_frequent.py 。
习题12-2
再来练习练习易位构词:
编写一个程序,使之能从文件中读取单词列表(参考读取单词列表一节), 并且打印出所有属于易位构词的单词组合。
下面是一个输出结果的示例:
['deltas', 'desalt', 'lasted', 'salted', 'slated', 'staled'] ['retainers', 'ternaries'] ['generating', 'greatening'] ['resmelts', 'smelters', 'termless']
提示:你也许应该创建一个字典,用于映射一个字母集合到一个该集合可异位构词的词汇集合。但是问题是,你怎样表示这个字母集合才能将其用作字典的键呢?
改写前面的程序,使之先打印易位构词数量最多的列表,第二多的次之,依次按易位构词的数量排列。
在Scrabble 拼字游戏中,游戏胜利(“bingo”)指的是你利用手里的全部七个字母,与图版上的那个字母一起构成一个8个字母的单词。哪八个字母能够达成最多的“bingo”?提示:最多有7种胜利方式。
习题12-3
如果两个单词中的某一单词可以通过调换两个字母变为另一个,这两个单词就构成了“换位对(metatheisi pair)”;比如,“converse”和“conserve”。 编写一个程序,找出字典里所有的“换位对”。
提示:不用测试所有的单词组合,也不用测试所有的字母调换组合。致谢:这道习题受 http://puzzlers.org 上的案例启发而来。
答案: http://thinkpython2.com/code/metathesis.py 。
习题12-4
又是一个来自 Car Talk 的字谜题( http://www.cartalk.com/content/puzzlers ):
如果你每一次从单词中删掉一个字母以后,剩下的字符仍然能构成一个单词,请问世界上符合条件的最长单词是什么?
注意,被删掉的字母可以位于首尾或是中间,但不允许重新去排列剩下的字母。每次移除一个字母后,你会得到一个新单词。这样一直下去,最终你只剩一个字母,并且它也是一个单词——可以在字典中查到。我想知道,符合条件的最长单词是什么?它由多少个字母构成?
我先给出一个短小的例子:“Sprite”。一开始是 sprite ,我们可以拿掉中间的 ‘r’ 从而获得单词 spite,然后拿掉字母 ‘e’ 得到 spit,再去掉 ‘s’,剩下 pit,依次操作得到 it,和 I。
编写一个程序,找到所有能够按照这种规则缩减的单词,然后看看其中哪个词最长。
这道题比大部分的习题都要难,所以我给出一些建议:
- 你可以写一个函数,接受一个单词,然后计算所有“子词”(即拿掉一个字母后所有可能的新词)组成的列表。
- 递归地看,如果单词的子词之一也可缩减,那么这个单词也可被缩减。我们可以将空字符串视作也可以缩减,视其为基础情形。
- 我提供的词汇列表中,并未包含诸如 ‘I’、 ‘a’ 这样的单个字母词汇,因此,你可能需要加上它们,以及空字符串。
- 为了提高程序的性能, 你可能需要暂存(memorize)已知可被缩减的单词。
答案: http://thinkpython2.com/code/reducible.py 。
贡献者
- 翻译:@SeikaScarlet
- 校对:@bingjin
- 参考:@carfly