《性能测试》专题
-
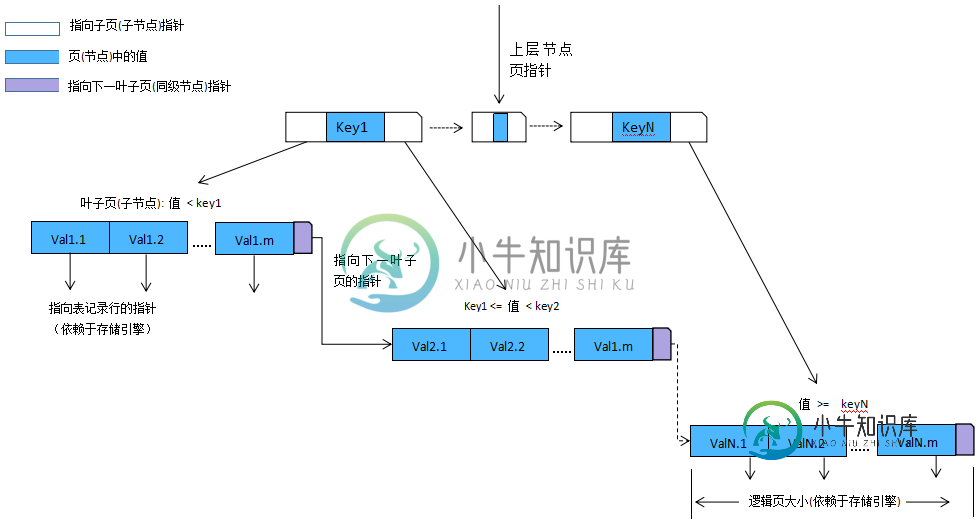 mysql性能优化之索引优化
mysql性能优化之索引优化本文向大家介绍mysql性能优化之索引优化,包括了mysql性能优化之索引优化的使用技巧和注意事项,需要的朋友参考一下 作为免费又高效的数据库,mysql基本是首选。良好的安全连接,自带查询解析、sql语句优化,使用读写锁(细化到行)、事物隔离和多版本并发控制提高并发,完备的事务日志记录,强大的存储引擎提供高效查询(表记录可达百万级),如果是InnoDB,还可在崩溃后进行完整的恢复,优点非常多
-
GZ到ORC文件的性能改进
我们看到ORC和带分区的ORC执行相同(有时我们看到B/W ORC分区和不带分区的ORC差别很小)。带分区的ORC会比ORC表现更好吗。带分区桶的ORC会比ORC分区表现更好吗?。我看到每个ORC分区文件都接近50-100 MB,ORC带外分区(每个文件大小为30-50 MB)。 **注:120 GB的Un压缩数据被压缩为17 GB的ORC文件格式
-
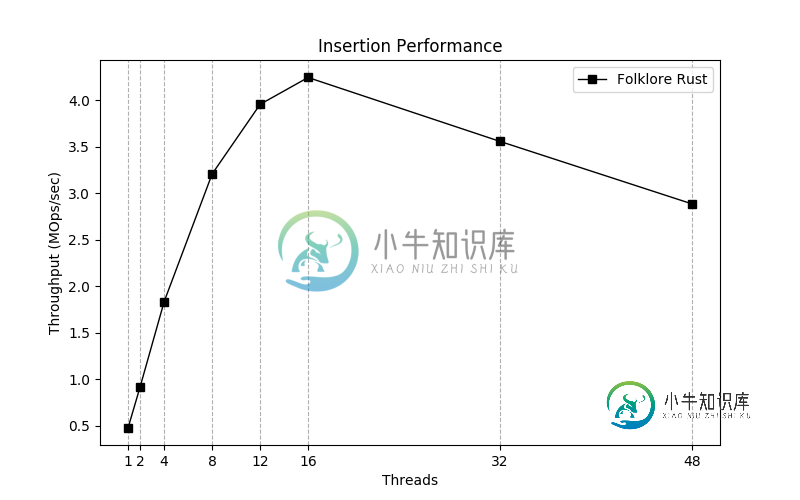 大量锈蚀Thread的性能下降
大量锈蚀Thread的性能下降我正在Rust中创建一个无闩锁并发哈希映射。吞吐量曲线看起来就像我预期的那样,最多可达16个线程,此时性能将下降。 吞吐量(MOps/秒)与线程数 我使用了一个带有48个vCPU和200GB RAM的Google云实例。我尝试启用/禁用超线程,但没有明显的效果。 以下是我如何生成线程: 我没有主意了;我的Rust代码对于多线程是否正确?
-
 Cassandra火花连接器读取性能
Cassandra火花连接器读取性能我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码: 所有3个参数都是表上键的一部分: 主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generat
-
Spring NamedParameterJdbcTemplate查询的性能非常慢
我正在处理一个需要JDBC调用Oracle数据库的项目。我已经设置了UCP池化来与SpringJDBC一起工作。我有一个相当简单的查询,我正在执行如下... 我的java代码来设置这个查询看起来像下面... 只要数组中只有一个id,这一切都可以正常运行。当我添加第二个ID时,查询需要将近5分钟的时间运行。如果我获取精确的查询并在SQLDeveloper中执行它,则需要.093秒。 我的代码或配置一
-
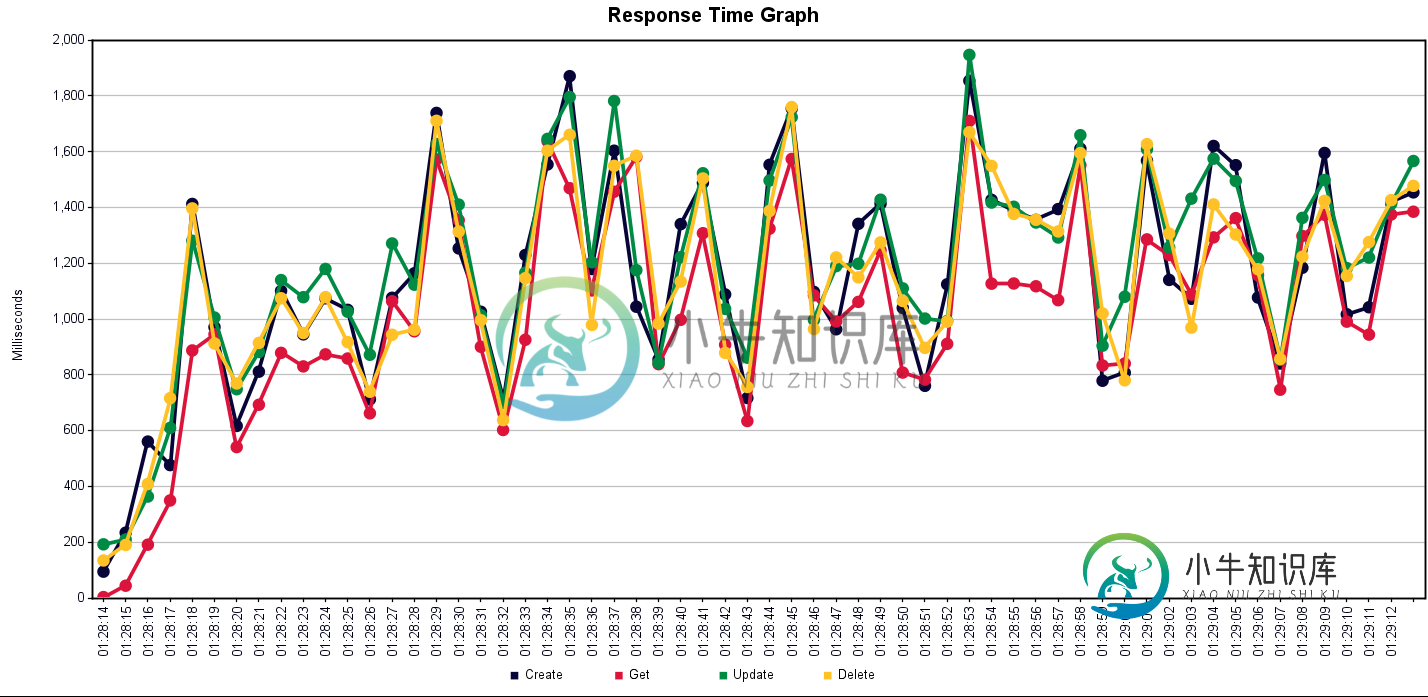 Spring Boot应用程序性能较慢
Spring Boot应用程序性能较慢我有一个非常基本的Spring Boot应用程序,它公开了一个非常简单的实体的CRUD Rest API。使用JMeter运行性能测试显示响应时间很差 约束:id PK自动增量 设置: 线程数:100 4个API,用于执行以下功能 我试图用可视化虚拟机查看原因。似乎存储库函数花费了太多时间。我假设是数据库导致了这个问题。 连接池设置:因为我没有设置任何内容,假设我的应用程序使用HikariCP,默
-
本地flink执行的性能极低
我目前正在将我公司的一些算法移植到flink应用程序中,以便将来作为流运行。为了测试这些算法,我使用从CSV文件读取的现有数据,然后使用flink spector创建流。这些数据集通常包含大约10000个基准,而每个基准都包含一个时间戳和一个整数值。 我现在的问题是,flink应用程序需要非常长的时间(大约半个小时)来处理这些数据,这应该可以在几秒钟内轻松完成,我不知道为什么。 以下是我的代码的外
-
React无状态组件-性能和PureRender
每个人都说它使用组件将提高应用程序的性能。然而,我注意到,在错误的地方使用无状态组件确实会降低应用程序的性能。 无状态组件:
-
Solr性能警告:DeckSearcher上的重叠
在我们的测试环境中,我们的solr搜索引擎遇到了许多问题。我们在4.6版上有一个solr云设置,单个分片,4个节点。我们看到CPU在领导节点上的平行线达到100%几个小时,然后服务器开始抛出OutOfMemory错误,“性能警告:重叠onDeckSearcher”开始出现在日志中,领导进入恢复模式,过滤器缓存和查询缓存预热时间达到60秒左右(通常不到2秒),领导节点关闭,我们在整个集群恢复并选举新
-
提高配置单元jdbc的性能
是否有人知道如何提高配置单元JDBC连接的性能。 详细问题: 当我从配置单元CLI查询配置单元时,我在7秒内得到响应,但从配置单元JDBC连接,我在14秒后得到响应。我想知道是否有任何方法(配置更改)可以通过JDBC连接来提高查询的性能。 提前道谢。
-
配置单元查询性能优化
为了提高配置单元查询的性能,有哪些优化参数 配置单元版本:-Hive 0.13.1-cdh5.2.1 配置单元查询:- 设置hive.exec.parallel=true; 您能建议任何其他设置,除了以上,以提高配置单元查询的性能,我正在使用的类型查询。
-
刷新postgres物化视图的性能
我正在探索物化视图来创建非规范化视图,以避免为了提高读取性能而连接多个表。API将从物化视图中读取数据,以向客户端提供数据。 我正在使用亚马逊aurora postgres(版本11)。 我在物化视图(MV)上使用一个唯一的索引,这样我就可以使用“并发刷新”选项。 不过我注意到的是,当只有一小部分行在其中一个源表中更新,我尝试刷新视图时,它非常慢。事实上比第一次填充视图慢。例如:要填充MV第一次需
-
StanfordCoreNLP和语义图的性能问题
当我尝试使用斯坦福NLP和CoreNLP分析文本时,性能非常差。处理CNN的文件。com大约需要30秒。 我拥有的代码基本上创建了具有以下配置的StanfordCoreNLP的单个实例: 注释器=标记化、ssplit、pos、引理、ner、解析、dcoref sutime。活页夹=0 当我禁用“ner, parse, dcoref”时,性能非常快。由于我需要获取语义图,我想知道是否有一种方法可以优
-
Java同步int变量:性能差异
经过以下问题后,同步块能比原子更快吗<我编写了一个简单的程序来比较AtomicInteger和synchronized块(其中int递增)的性能差异。每次我运行这个程序,它都会给我一个比率 当我使用 该比率最小。它在100左右变化 比率约为800。 问题1:你能告诉我这是测试AtomicInteger和synchronized increment()方法性能差异的正确方法吗? 问题2:如果我增加T
-
JavaFX时间轴动画性能不佳
我目前正在创建一个非常简单的JavaFX程序,模拟城市之间运送乘客的飞机和船只。到目前为止,我已经能够让飞机在几个城市进行短途飞行,但问题是,当我添加超过3或4架飞机时,动画速度非常慢。 我正在做的是使用Timeline类作为我的主游戏循环,清除并重新绘制画布上每帧60帧的平面图像。以下是时间表部分: 以下是我如何为平面创建新线程: 这是Plane类中定义的run()方法: 我知道代码非常混乱,但