
大量锈蚀Thread的性能下降

我正在Rust中创建一个无闩锁并发哈希映射。吞吐量曲线看起来就像我预期的那样,最多可达16个线程,此时性能将下降。
吞吐量(MOps/秒)与线程数
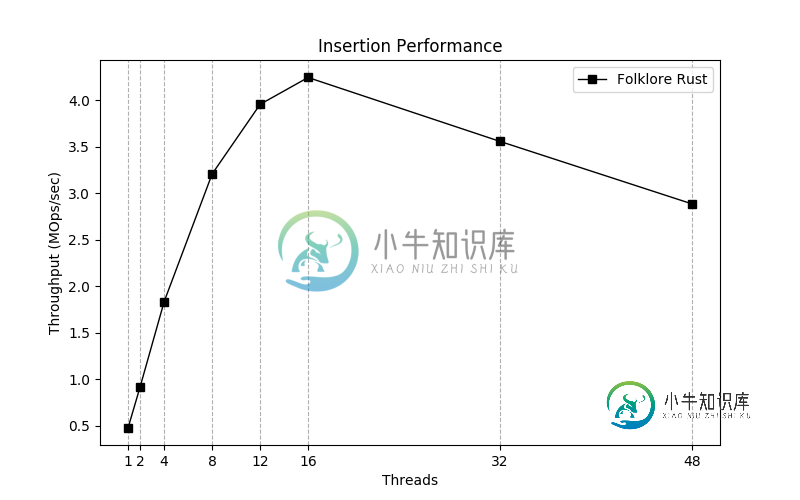
我使用了一个带有48个vCPU和200GB RAM的Google云实例。我尝试启用/禁用超线程,但没有明显的效果。
以下是我如何生成线程:
for i in 0..num_threads {
//clone the shared data structure
let ht = Arc::clone(&ht);
let handle = thread::spawn(move || {
for j in 0..adds_per_thread {
//randomly generate and add a (key, value)
let key = thread_rng().gen::<u32>();
let value = thread_rng().gen::<u32>();
ht.set_item(key, value);
}
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
我没有主意了;我的Rust代码对于多线程是否正确?
共有1个答案

如果您的所有线程都将所有时间花在无锁数据结构上,那么是的,一旦您有足够的线程,就会出现争用。有了足够的写入程序,它们将更频繁地争夺表中的同一缓存线。(而且,在PRNG中花费的时间可能不会隐藏对缓存或DRAM共享带宽的争用)。
您可能会开始遇到更多CAS重试之类的事情,包括任何争用退避机制。此外,线程将遭受缓存未命中,甚至内存顺序错误猜测管道也会从一些原子读取中清除;并非所有内容都是原子RMW或写入。
这不是无锁数据结构的正常用例;通常,您将它们与执行重要工作的代码一起使用,而不是对它们进行重击,因此实际争用很低。此外,hashmap的实际工作负载很少是只写的(尽管如果您只想消除重复数据,可能会发生这种情况)。
阅读量表非常好,读者的数量,但写会击中竞争。
-
我正在对大小为50,000个元素的两个向量执行基于元素的操作,并且有不满意的性能问题(几秒钟)。是否存在明显的性能问题,例如使用不同的数据结构?
-
JMeter可以在java应用程序中检测线程泄漏吗?也就是说,可以通过JVisualvm观察线程泄漏,但是JMeter没有任何插件等可以检测Java应用程序中的线程泄漏。如果没有,那么有没有其他性能测试工具可以检测java应用程序中的线程泄漏,为什么Jeter不能这样做?
-
问题内容: 我们正在为IMAP帐户开发基于Java的邮件客户端,并使用最新的Java邮件api(1.5.6)。我们的客户拥有超过400个文件夹的邮件帐户。用户在文件夹上执行检查邮件,并在每个文件夹上进行迭代并获取新消息,例如, 或获取未读邮件的数量过多,这是因为文件夹数量巨大。(我们必须遍历400个文件夹) 为了提高性能,我们在线程中使用了并行工作连接,并且我们有一个SESSION实例,但是每个线
-
刚刚读完《铁锈书》中关于生命的章节。 所有的东西都是有意义的,特别是一个主要的例子是下面的不会编译 这是因为“我们告诉Rust,最长函数返回的引用的生存期与传入的引用的生存期中的较小者相同。因此,借用检查器不允许清单10-24中的代码具有无效引用。”在本章的另一部分中,“最长函数返回的引用的生存期与传入的引用的生存期中较小者相同。” 因此,很自然地,我会尝试给出我自己的简化示例,如下所示 令我惊讶
-
问题内容: 从变量读取的速度比从常规字段读取的速度慢多少? 更具体地说,简单对象创建比访问变量快还是慢? 我认为它足够快,因此与每次创建实例相比,拥有实例要快得多。但这是否也适用于字节[10]或字节[1000]? 编辑:问题是调用get 时真正发生了什么?如果那只是一个领域,就像其他领域一样,那么答案将是“它总是最快的”,对吗? 问题答案: 运行未发布的基准测试,我的计算机上每次迭代大约需要35个
-
在Java中,所有对象都继承自。在Go中,所有类型/结构都实现空接口。Rust语言中是否有类似的构造? 如果答案是否定的,是什么让它变得不必要?这是因为Rust中的所有实体(模块除外)都可以按类型参数化吗?这是否消除了所有Rust实体/结构/枚举共享的公共“超类型”或公共特性的需要?