
Cassandra火花连接器读取性能

我有一些Spark经验,但刚开始使用Cassandra。我正在尝试进行非常简单的阅读,但性能非常差——不知道为什么。这是我正在使用的代码:
sc.cassandraTable("nt_live_october","nt")
.where("group_id='254358'")
.where("epoch >=1443916800 and epoch<=1444348800")
.first

所有3个参数都是表上键的一部分:
主键(group\u id,epoch,group\u name,auto\u generated\u uuid\u field),聚类顺序为(epoch ASC,group\u name ASC,auto\u generated\u uuid\u field ASC)
我从驱动程序中看到的输出是这样的:
15/10/07 15:05:02信息CassandraConnector:连接到Cassandra集群:shakassandra15/10/07 15:07:02错误会话:错误创建池到attila。/198.xxx:9042com.datastax.driver.core.ConnectionException:[attila。/198.xxx:9042]传输初始化过程中出现意外错误(com.datastax.driver.core.操作时间异常:[attila/198.xxx:9042]操作超时)
2007年10月15日15:07:02信息SparkContext:开始工作:接受CassandraRDD。scala:121
15/10/07 15:07:03信息BlockManagerInfo:在osd09:39903内存中添加broadcast_5_piece0(大小: 4.8 KB,免费: 265.4 MB)
15/10/07 15:08:23信息TaskSetManager:在osd09(1/1)上的80153 ms内,在阶段6.0(TID 8)中完成任务0.0
15/10/07 15:08:23信息TaskSetManager:在osd09(1/1)上的80153 ms内,在阶段6.0(TID 8)中完成任务0.0
2007年10月15日15:08:23 INFO DAGScheduler:ResultStage 6(以CassandraRDD为例。scala:121)在80.958中完成s 2007年10月15日15:08:23 INFO TaskScheduleImpl:从池中删除了任务集6.0,其任务已全部完成
2007年10月15日15:08:23信息DAGScheduler:作业5已完成:在CassandraRDD拍摄。斯卡拉:121,用了81.043413秒
我希望这个查询速度非常快,但它需要一分钟的时间。有几件事突然向我袭来
- 获取会话错误几乎需要两分钟——我将3个节点的IP传递给Spark Cassandra连接器——有没有办法告诉它更快地跳过失败的连接?
- 任务被发送到不是Cassandra节点的Spark工作人员——这对我来说似乎很奇怪——有没有办法获取有关调度程序选择将任务发送到远程节点的原因的信息?
- 即使任务被发送到远程节点,该工作器的输入大小(Max)显示为334.0 B/1,但执行器时间为1.3分钟(见图)。这看起来真的很慢——我希望时间花在反序列化上,而不是计算上...
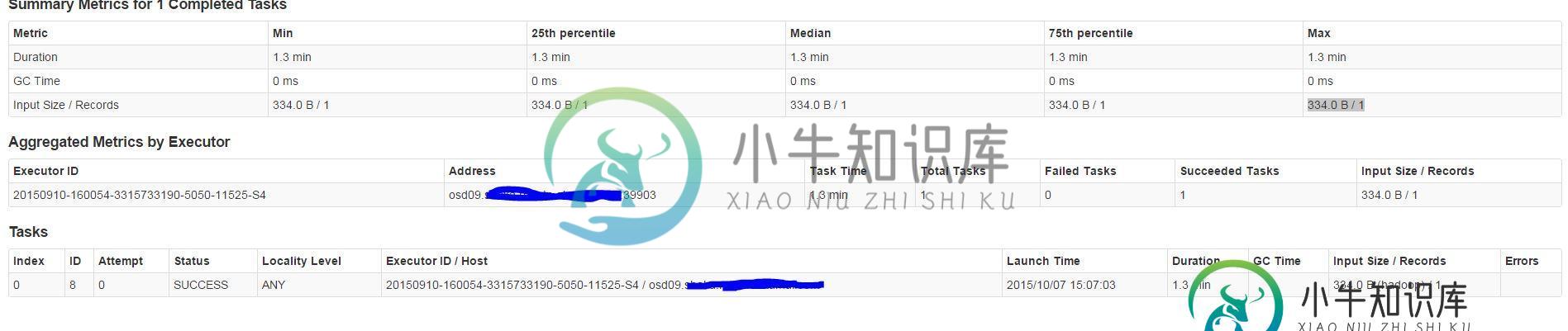
任何关于如何调试这个的提示,在哪里寻找潜在问题都是值得赞赏的。将Spark 1.4.1与连接器1.4.0-M3一起使用,cassandra ReleaseVersion:2.1.9,可调连接器参数的所有默认值
共有1个答案

我认为问题在于分区之间的数据分布。您的表有一个集群(分区)键groupId,epoch只是一个集群列。数据仅按groupId分布在集群节点上,因此在集群的一个节点上有一个groupId='254358'的巨大分区。当您运行查询时,Cassandra以groupId='254358'到达非常快的分区,然后过滤所有行以查找纪元在1443916800和1444348800之间的记录。如果有很多行,查询速度会非常慢。实际上,此查询不是分布式的,它将始终在一个节点上运行。
更好的做法是提取日期甚至小时,并将其添加为分区键,在您的示例中类似
PRIMARY KEY ((group_id, date), epoch, group_name, auto_generated_uuid_field)
WITH CLUSTERING ORDER BY (epoch ASC, group_name ASC, auto_generated_uuid_field ASC)
为了验证我的假设,您可以在cqlsh中运行当前查询,并打开跟踪阅读此处的“如何执行”。所以这个问题与火花无关。
关于错误和获取时间,一切都很好,因为您在超时发生后收到错误。
我还记得Spark-cassandra-连接器的建议,将Spark从站连接到Cassandra节点,以便通过分区键分发查询。
-
我有一个Cassandra节点集群,每个节点机器上都有Spark worker。对于通信,我使用Datastax Spark-Cassasndra连接器。Datastax连接器是否对同一台机器中的工作人员从Cassandra节点读取数据进行了优化,或者在机器之间存在一些数据流?
-
编辑1 当选择正确的scala版本时,它似乎会更进一步,但我不确定下面的输出是否仍然有需要解决的错误:
-
我正在研究建立一个JDBC Spark连接,以便从r/Python使用。我知道和都是可用的,但它们似乎更适合交互式分析,特别是因为它们为用户保留了集群资源。我在考虑一些更类似于Tableau ODBC Spark connection的东西--一些更轻量级的东西(据我所知),用于支持简单的随机访问。虽然这似乎是可能的,而且有一些文档,但(对我来说)JDBC驱动程序的需求是什么并不清楚。 既然Hiv
-
Java和Scala解决方案都受到欢迎
-
我现在有一个spark工作,它从HDFS中提取数据,并将数据转换为平面文件,以加载到Cassandra中。
-
我使用Spark2和neo4j3(安装在一个节点上),并使用这个spark/Neo4j https://github.com/neo4j-contrib/neo4j-spark-connector 我可以使用我的数据库。 多谢帮忙。