《机器学习算法面试》专题
-
Azure机器学习实验创建
提前感谢普拉迪普
-
机器学习:关联与回归
关联规则:关联规则反映一个事物与其他事物之间的相互依存性和关联性。如果两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。Apriori算法利用频繁项集生成关联规则。它基于频繁项集的子集也必须是频繁项集的概念。频繁项集是支持值大于阈值(support)的项集。
-
8. 大数据与机器学习
Kubernetes 在大数据与机器学习中的实践案例。
-
5.2 更多机器学习资源
以下是根据不同语言类型和应用领域收集的各类工具库,持续更新中。 C 通用机器学习 Recommender - 一个产品推荐的C语言库,利用了协同过滤. 计算机视觉 CCV - C-based/Cached/Core Computer Vision Library ,是一个现代化的计算机视觉库。 VLFeat - VLFeat 是开源的 computer vision algorithms库, 有
-
第四章 机器学习基础
numpy比较适合用来生产一些简单的抽样数据。API都在random类中,常见的API有: 1) rand(d0,d1,...,dn) 用来生成d0xd1x...dn维的数组。数组的值在[0,1]之间 例如:np.random.rand(3,2,2),输出如下3x2x2的数组 array([[[ 0.49042678, 0.60643763], [ 0.18370487,
-
基本机器学习(Basic Machine Learning)
人工智能(AI)是使计算机能够模仿人类认知行为或智能的任何代码,算法或技术。 机器学习(ML)是AI的一个子集,它使用统计方法使机器能够通过经验学习和改进。 深度学习是机器学习的一个子集,它使多层神经网络的计算变得可行。 机器学习被视为浅层学习,而深度学习被视为具有抽象的层次学习。 机器学习涉及广泛的概念。 概念如下 - supervised unsupervised 强化学习 linear re
-
 写给人类的机器学习
写给人类的机器学习本指南旨在让任何人访问。将讨论概率,统计学,程序设计,线性代数和微积分的基本概念,但从本系列中学到东西,不需要事先了解它们。
-
 Python 机器学习实战教程
Python 机器学习实战教程欢迎阅读 Python 机器学习系列教程的回归部分。这里,你应该已经安装了 Scikit-Learn。如果没有,安装它,以及 Pandas 和 Matplotlib。
-
第1章 机器学习基础
机器学习 概述 机器学习(Machine Learning,ML) 是使用计算机来彰显数据背后的真实含义,它为了把无序的数据转换成有用的信息。是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。 它是人工智能的核心,是使计算机具有智能的根本途径,其应用遍及
-
3.6 scikit-learn:Python 中的机器学习
先决条件 Numpy, Scipy IPython matplotlib scikit-learn (http://scikit-learn.org) 警告:从版本0.9(在2011年9月发布)起,scikit-learn导入路径从scikits.learn 改为 sklearn 3.5.1 加载样例数据集 首先,我们将加载一些数据来玩玩。我们将使用的数据是知名的非常简单的花数据鸢尾花数据集。 我
-
 9.18顺丰 机器学习 凉经
9.18顺丰 机器学习 凉经sift步骤和公式 #面经# #校招# #面试# canny步骤和公式 交叉验证原理 hsv和rgb转换公式 pca原理步骤 为什么要降维 怎么特征现选择,卡方检验是什么 kmeans原理步骤,k值怎么确定 决策树怎么预测值 adaboost原理 xgboost原理 皮尔逊系数 在手机上部署大模型要怎么做 python内存清除机制 roc曲线是什么,怎么计算 最后一道lc medium 因为简历上
-
 卓驭 机器学习平台工程师 一面面经
卓驭 机器学习平台工程师 一面面经问项目问的很细,但不拷打,纯交流。 中间问了推理加速的选择,大概讲了讲vllm和deepspeed-mii主要的一些推理加速的技术路线。 问了问推理框架的选择,说了一下vllm,deepspeed-mii和sglang的使用体验。 问了问模型增大主要带来的是什么瓶颈,分别讲了计算瓶颈和访存瓶颈。 无八股,无代码题。 方向其实不太匹配,挂了也正常,许愿一个二面吧 #秋招##卓驭科技#
-
 附答案 | 最强Python面试题之机器学习篇
附答案 | 最强Python面试题之机器学习篇写在之前 大家好呀,我是帅蛋。 今天来更新机器学习篇面试,这一部分一共 32 道题。Python 面试八股文尽在帅蛋的【最强Python面试题】,大家一定要记得点赞收藏呀!!! 欢迎和帅蛋聊一聊~扣扣2群:609771600,获取最新秋招信息 & 内推进度,日常聊聊迷茫吹吹牛皮,抱团取暖 顺便提一句,我所有和面试相关的内容都会放在#帅蛋的面试空间# 中,大家可以关注下这个话题~ 我会尽我最大的努力
-
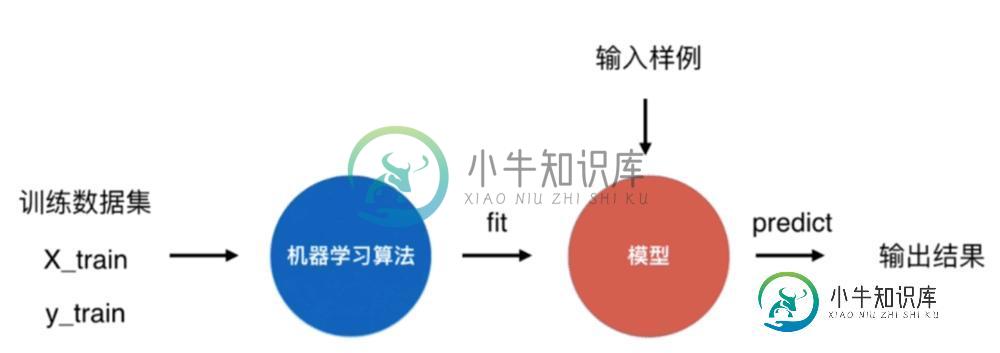 Python机器学习之scikit-learn库中KNN算法的封装与使用方法
Python机器学习之scikit-learn库中KNN算法的封装与使用方法本文向大家介绍Python机器学习之scikit-learn库中KNN算法的封装与使用方法,包括了Python机器学习之scikit-learn库中KNN算法的封装与使用方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python机器学习之scikit-learn库中KNN算法的封装与使用方法。分享给大家供大家参考,具体如下: 1、工具准备,python环境,pycharm 2、在机器
-
 计算机视觉算法岗面经(暑期实习)
计算机视觉算法岗面经(暑期实习)终于轮到我写面经了,之前因为拿不到oc一直不敢写,现在感觉成功了90%,就先半场开个香槟,攒攒人品。 bg:双9,非科班,一篇二区,一篇准备投二区,两个项目,一个项目论文,一个项目专利。 简历挂:360,携程,美团,阿里云 其中阿里云点名批评,hr给我打电话,问我要不要走他们部门的流程,如果走的话可能要一个月的时间,还贴心地说如果觉得部门不合适的话可以给我推到其他部门,我深受感动,当即同意进入流程