《机器学习算法面试》专题
-
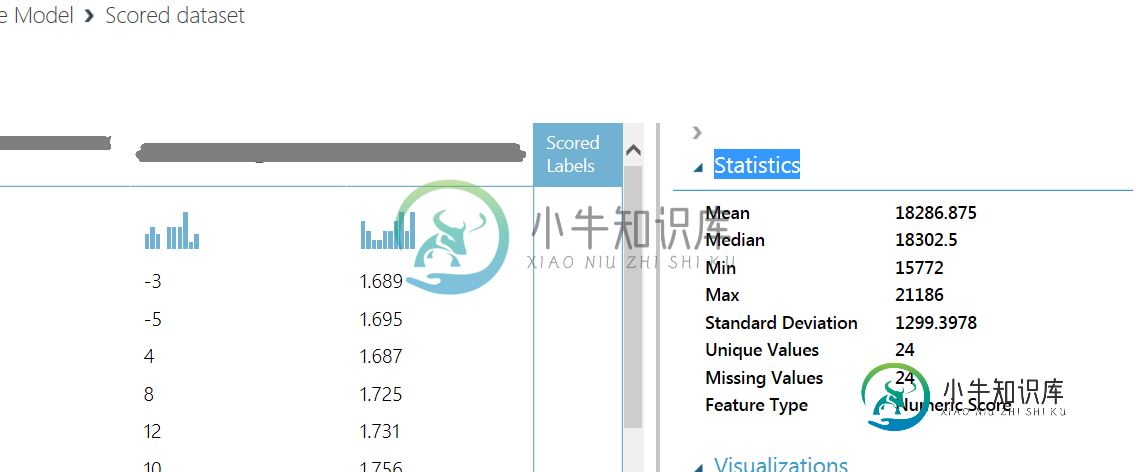 Azure机器学习-空分数结果
Azure机器学习-空分数结果我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。 通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。 更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。
-
第十八章 机器学习入门
入门文章 一文读懂机器学习,大数据/自然语言处理/算法全有了
-
8. 大数据与机器学习 - Tensorflow
Kubeflow 是 Google 发布的用于在 Kubernetes 集群中部署和管理 tensorflow 任务的框架。主要功能包括 用于管理 Jupyter 的 JupyterHub 服务 用于管理训练任务的 Tensorflow Training Controller 用于模型服务的 TF Serving 容器 部署 部署之前需要确保 一套部署好的 Kubernetes 集群或者 Mini
-
8. 大数据与机器学习 - Spark
Kubernetes 从 v1.8 开始支持原生的Apache Spark应用(需要Spark支持Kubernetes,比如v2.2.0-kubernetes-0.4.0),可以通过 spark-submit 命令直接提交Kubernetes任务。比如计算圆周率 bin/spark-submit --deploy-mode cluster --class org.apache.spark.
-
使用 scikit-learn 介绍机器学习
校验者: @小瑶 翻译者: @李昊伟 校验者: @hlxstc @BWM-蜜蜂 @小瑶 翻译者: @... 内容提要 在本节中,我们介绍一些在使用 scikit-learn 过程中用到的 机器学习 词汇,并且给出一些例子阐释它们。 机器学习:问题设置 一般来说,一个学习问题通常会考虑一系列 n 个 样本 数据,然后尝试预测未知数据的属性。 如果每个样本是 多个属性的数据 (比如说是一个多维记录),
-
6 最好的机器学习资源
用于制定人工智能、机器学习和深度学习课程表的资源概览。 制定课程表的一般建议 上学获得一个正式学位并不总是可行或者令人满意的。对于那些考虑自学来代替的人,这就是写给你们的。 1. 构建基础,之后专攻兴趣领域 你不能深入每个机器学习话题。有太多药学的东西,并且领域的进展较快。掌握基础概念,之后专注特定兴趣领域的项目 -- 无论是自然语言理解,计算机视觉,深度强化学习,机器人,还是任何其它东西。 2.
-
1 为什么机器学习重要
简单、纯中文的解释,辅以数学、代码和真实世界的示例 谁应该阅读它 想尽快赶上机器学习潮流的技术人员 想要入门机器学习,并愿意了解技术概念的非技术人员 好奇机器如何思考的任何人 本指南旨在让任何人访问。将讨论概率,统计学,程序设计,线性代数和微积分的基本概念,但从本系列中学到东西,不需要事先了解它们。 为什么机器学习重要 人工智能将比本世纪的任何其他创新,更有力地塑造我们的未来。 任何一个不了解它的
-
 bilibili机器学习引擎开发 1h
bilibili机器学习引擎开发 1h自我介绍 c++,计网八股 好多好多 项目深挖 raft和跳表 学校科研和难点 手撕快排(中间脑子一抽写完partition就运行了,现在想想,麻了) 面试官好好!也很温柔~全防出去了!!许愿~ bilibili💕b小将,启动!#bilibili##机器学习#
-
 这年头机器学习没深度学习不能活了吗
这年头机器学习没深度学习不能活了吗快手一面凉经 算法 我迟到10分钟 面试45分钟 1. 和为k的连续数组 2.AUC 公式,物理意义,GAUC,auc缺点 3.L1 和L2 4. Dropout 训练预测区别 BN在哪些场景下不适用 5.Xgboost特点 6.损失函数评价函数,Huber 7.交叉熵公式 为什么分类用交叉熵不用Mae 8.生成式模型与判别式模型,NLP了解吗(我是做数据挖掘的, 认识不深,说不了解) 9.实习介
-
第七章 机器学习 - 7.2 支持向量机
第一层、了解SVM 支持向量机,因其英文名为support vector machine,故一般简称SVM,通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。 1.1、线性分类 理解SVM,咱们必须先弄清楚一个概念:线性分类器。 1.1.1、分类标准 考虑一个二类的分类问题,数据点用x来表示,类别用y来
-
 京东JDS机器算法岗一面面经
京东JDS机器算法岗一面面经写在前面的碎碎念:第一次发帖 大概率是凉经 刚面完没有两分钟TET的短信就到了 我还说效率真高 刚被刷就给我调到下一个岗了() 本人985本硕 非科班 传统工科 略带一点代码方向 ---------正文部分-------- 一面是hr面 整个过程大概20min+ 京东健康部门 自我介绍 专业对口的企业有哪些 为什么没去专业对口的企业 对未来的考虑和对不同选择的认识(比如国央企 大厂 读博) 对薪资
-
 23秋招 阿里高德部门机器学习 面经
23秋招 阿里高德部门机器学习 面经更新:已挂 9月1号投递的算法工程师-机器学习岗,高德部门 9.5一面 (50min) 总结:面试分四部分:简历项目+基础知识+场景题+做题 自我介绍 简历项目比赛介绍+提问 问了许多深度学习和机器学习的基础知识: 卷积 vs 全连接 怎么理解卷积? 图片的物体发生位移或扰动,对CNN有影响吗? 池化的作用 随机森林 vs GBDT 随机森林和GBDT的基分类器可以改成线性分类器或者其他吗? 分类
-
 百度提前批机器学习岗位一面凉经
百度提前批机器学习岗位一面凉经不用自我介绍,就是聊项目,面试官人特别好,我特别菜 大概讲了讲项目后做算法题, 第一题self-attention,用pytorch,继承pytorch.nn.Module写forward函数,没写出来,如果写出来了应该会继续写mask self-attention 第二题求前K个高频数 第三题二叉树 前序遍历中序遍历后序遍历 然后根据后序和中序结果写前序遍历 机器学习问了过拟合 决策树,xgb和
-
内置sagemaker算法的增量学习
我正在训练DeepAR AWS SageMaker的内置算法。使用sagemaker SDK,我可以使用特定的超参数训练模型: 我想以较小的学习率再次训练生成的模型。我遵循此处描述的增量培训方法:https://docs.aws.amazon.com/en_pv/sagemaker/latest/dg/incremental-training.html,但它不起作用,显然(根据链接),只有两个内置
-
 vivo-深度学习算法工程师
vivo-深度学习算法工程师8.26 测评 9.14 笔试 9.21 一面 自我介绍 项目介绍(细节深挖) BN层参数的作用 吸BN操作 样本不均衡问题 小目标问题 双线性插值(边界考虑) GAN网络能否落地 怎样提高特殊目标(电线杆、树)等目标的检测精度 反问 9.22 二面 自我介绍 项目介绍 编程能力和管理能力打分 团队管理方面(好多问题) 责任心考虑 地点考虑 期望薪资 offer考虑 互联网公司投递情况 为找工作做