《机器学习算法面试》专题
-
 高德地图 深度学习/大模型算法 二面面经
高德地图 深度学习/大模型算法 二面面经一小时,拷打transformer 你怎么理解AIGC? 讲一下transformer transformer和cnn的区别 transformer中embeding怎么做的 位置编码你了解哪些形式 三角函数位置编码有哪些好处,旋转位置编码呢 position embeding 和input怎么融合的 多头注意力相比单头优势,encode的时候多头会做融合吗?还是什么时候做融合? 拆成多少个头有什
-
 海康实习 算法面试
海康实习 算法面试海康 5-31算法面试 15min 介绍项目 一个问题:说一下cartographer的大致流程 反问。 想问下有佬收到2面邮件了没。
-
 零跑汽车- 强化学习算法工程师面经
零跑汽车- 强化学习算法工程师面经因为投的比较晚,所以目前进行到一面,后面是主管面和HR 面。 一面(1小时20分钟):主要是聊项目和论文,撕了一道蒙特卡洛估计的题 从论文的DDPG算法开始聊,TD3,SAC算法,应用场景,优缺点啥的 聊王者荣耀比赛,从网络结构设计(特征工程、channel attention,self-attention,multi-head value estimation),奖励函数设计,算法设计(dual
-
 《机器学习高频面试题详解》1.3:L1和L2正则化
《机器学习高频面试题详解》1.3:L1和L2正则化前言 大家好,我是鬼仔,今天带来《机器学习高频面试题详解》专栏的第1.3节:L1和L2正则化。这是鬼仔第一次开设专栏,每篇文章鬼仔都会用心认真编写,希望能将每个知识点讲透、讲深,帮助同学们系统性地学习和掌握机器学习中的基础知识,希望大家能多多支持鬼仔的专栏~ 目前这篇是试读,后续的文章需要订阅才能查看哦(每周一更/两更),专栏预计更新30篇文章(只增不减),具体内容可以看专栏介绍,大家的支持是鬼仔
-
 23秋招 顺丰科技机器学习工程师 面经
23秋招 顺丰科技机器学习工程师 面经9.6一面 (30min) 面试官先说流程,一共考察两部分:一,简历上的项目提问+基础知识;二,个人综合素质与沟通交流能力。感觉更注重模型和特征的解释方面,说是因为要经常跟学统计的人打交道和合作。 自我介绍 项目提问,并穿插着问基础,比如讲一下特征选择的方法,特征重要性等等 问懂数理统计吗?讲一下假设检验的流程。特征选择的卡方检验。 碰到给客户解释不清的东西,或者他听不懂,怎么解决? IT领域裁员
-
 23春招 顺丰科技 机器学习工程师 面经
23春招 顺丰科技 机器学习工程师 面经一面: 自我介绍 说一下卡方检验 树的剪枝 GBDT 随机过程 ADASYN(我简历里面写了这个所以才问的) SVM常用核函数 问项目 反问 二面: 自我介绍 GBDT(问的巨细,包括为什么可以用负梯度拟合残差、如果换个loss function还可以用负梯度拟合吗) 拉格朗日插值法具体怎么算的(我简历里面写了这个所以才问的) 回归树用什么损失函数(我回答了一堆分类树的,傻杯了哈哈哈哈) 用三个词
-
 阿里国际 AI- business 计算机视觉算法实习一面
阿里国际 AI- business 计算机视觉算法实习一面自我介绍,双方的,(我对阿里国际确实不了解) 问想要未来工作的base地 先来两道题,leetcode 11。leetcode爬楼梯 介绍一篇论文 知道vit吗 知道多模态吗 反问:1.卡多少(一千多张H100) 2.做什么(虚拟试衣,多模态,基座大模型)3. hc多少,暑期实习有10个,卡不能停找的人会比较多 4. 做research吗?(是的,一年以来业务做的很多了,现在需要技术的攻关) 全程
-
Python常用算法学习基础教程
本文向大家介绍Python常用算法学习基础教程,包括了Python常用算法学习基础教程的使用技巧和注意事项,需要的朋友参考一下 本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的清晰指令,算法代表着用系统的方法描述解决问题的策略机制。也就是说,能够对一定规范的输入,在有限时间内获得所要求的输出。如果一
-
1.3 第四部分 生成学习算法
第四部分 生成学习算法(Generative Learning algorithms) 目前为止,我们讲过的学习算法的模型都是$p (y|x;\theta)$,也就是给定 $x$ 下 $y$ 的条件分布,以 $\theta$ 为参数。例如,逻辑回归中就是以 $h_\theta(x) = g(\theta^T x)$ 作为 $p (y|x;\theta)$ 的模型,这里的 $g$ 是一个 $S$型函
-
 【寒假实习备战day3】折半算法的学习
【寒假实习备战day3】折半算法的学习简单的自我介绍 我是一名双非大二学生,目前学习方向为Java后端,快速学习并学到了springboot,并和实验室的朋友做了一个简单的微信小程序,想在寒假找份有关互联网的实习,打算海投,城市和公司暂时没有特别强烈的意向,我会再次牢固的复习一遍Java整套学习知识,并且开始补充算法知识刷算法题,来备战这次寒假实习,并且想报名参加蓝桥杯Java B组的比赛,希望我的一些学习笔记能为你带来一些帮助,这次
-
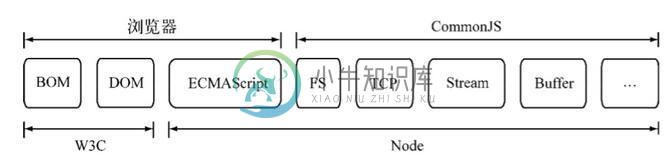 学习Node.js模块机制
学习Node.js模块机制本文向大家介绍学习Node.js模块机制,包括了学习Node.js模块机制的使用技巧和注意事项,需要的朋友参考一下 一、CommonJS的模块规范 Node与浏览器以及 W3C组织、CommonJS组织、ECMAScript之间的关系 Node借鉴CommonJS的Modules规范实现了一套模块系统,所以先来看看CommonJS的模块规范。 CommonJS对模块的定义十分简单,主要分为模块引用
-
机器学习的时间序列是什么?
本文向大家介绍机器学习的时间序列是什么?,包括了机器学习的时间序列是什么?的使用技巧和注意事项,需要的朋友参考一下 顾名思义,时间序列是包含特定时间段或时间戳的数据。它包含一定时间段内的观察结果。这类数据告诉我们变量是如何根据各种因素随时间变化的。时间序列分析和预测可以用来预测未来某个时间的数据。 单变量时间序列包含在一段时间内某些时间实例中针对单个变量获取的值。多元时间序列包含在相同的周期性时间
-
机器学习:使用 NVIDIA JetsonTX2 - 从零开始
从零开始 灌作业系统一定是我们的首要目标,但在这之前,我们要先有一台运行 Ubuntu x64 (14.04或更新) 的电脑,可以用虚拟机来代替。 没有虚拟机的朋友可以用VirtualBox。 Ubuntu x64 的映像档可以在这边下载。 1. 安装 VirtualBox 流程就不在这边赘述,简单来说,就是狂按下一步。 2. 安装 Ubuntu x64 有两点要注意: 因为稍后下载回来的安装包还
-
Azure机器学习(预览)到客户洞察
我正在尝试将MS Dynamics Customer Insights(CI)与我在新的Azure机器学习(designer)中构建的模型集成。目前,我看到CI和Azure机器学习工作室(classic)之间只有一个集成。 我已经在新Azure机器学习中的web服务(REST)后面部署了我的模型,但是它在CI中没有得到重视。但是,我能够使用Python脚本从API中评分/生成预测。 请推荐一种集成
-
weka中的机器学习分类与预测
我对机器学习很陌生。对不起,如果我的英语有任何错误。 我使用weka J48分类来预测是真是假。我有将近999K的训练套件,我用来训练模型。我使用了3倍的交叉验证方法来训练模型,使我的准确率达到了约84%。 现在在存储模型之后。我试着在50k数据集上测试它。结果非常糟糕,其中50%是不匹配的。我有11个属性,包括名词和数字字段。 我不知道为什么会这样。 我有两个问题。 我怎样训练才能在测试集中表现