《机器学习算法面试》专题
-
 速腾聚创 深度学习算法工程师
速腾聚创 深度学习算法工程师职位:深度学习算法工程师 base:上海 技术一面 (9/15) - 30min 自我介绍 项目介绍,随后围绕项目进行展开提问,会议论文与期刊论文之间的差异 反问 部门主要做感知(车道线、行人感知。。。 技术二面 (9/21) - 30min 没开摄像头 自我介绍 项目介绍,所有项目都介绍了一遍 中途会被打断问问题 反问 对除了自己所研究的方向外,还了解哪些,知不知道reid的方法、目标检测算法什
-
 科大讯飞算法岗面经(深度学习框架与平台)
科大讯飞算法岗面经(深度学习框架与平台)写写面经攒人品 一面 7月1日(50min) 1.项目介绍与深挖,同时抛些相关的八股,如ddp与dp差别 2.python的迭代器,生成器,报错机制 3.计算机存储结构。 4.知道哪些量化方法。 5.了解科大讯飞吗 二面 7月8号(40min) 1.项目介绍。 2.为什么选择这个岗位,你觉得是做些什么? 3.网络为什么要增加深度,好处是什么。为什么用两个3*3而不是一个5*5 4.pytorch的
-
在机器学习中处理地理空间坐标
我正在建立一个机器学习模型,其中一些列是物理地址(我可以将其转换为X / Y坐标),但我对ML算法如何处理这一点有点困惑。有没有一种特定的方法可以将地理位置转换成列,以便用于ML(分类和/或回归)中? 提前感谢!
-
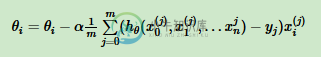 python实现机器学习之多元线性回归
python实现机器学习之多元线性回归本文向大家介绍python实现机器学习之多元线性回归,包括了python实现机器学习之多元线性回归的使用技巧和注意事项,需要的朋友参考一下 总体思路与一元线性回归思想一样,现在将数据以矩阵形式进行运算,更加方便。 一元线性回归实现代码 下面是多元线性回归用Python实现的代码: 特别需要注意的是要弄清:矩阵的形状 在梯度下降的时候,计算两个偏导值,这里面的矩阵形状变化需要注意。 梯度下降数学式子
-
机器学习和人工智能之间的区别
本文向大家介绍机器学习和人工智能之间的区别,包括了机器学习和人工智能之间的区别的使用技巧和注意事项,需要的朋友参考一下 人工智能 人工智能是指可以使非自然元素变得智能的科学。简单来说,人造物体,人造物体可以自己理解和思考。 机器学习 机器学习是指机器无需编程即可学习的方式。简而言之,机器学习是数据驱动的应用程序,它可以基于变化的输入做出自己的决定,并且可以随着时间的推移改进其决定。 以下是机器学习
-
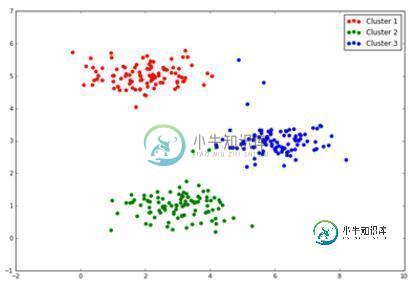 Python机器学习之K-Means聚类实现详解
Python机器学习之K-Means聚类实现详解本文向大家介绍Python机器学习之K-Means聚类实现详解,包括了Python机器学习之K-Means聚类实现详解的使用技巧和注意事项,需要的朋友参考一下 本文为大家分享了Python机器学习之K-Means聚类的实现代码,供大家参考,具体内容如下 1.K-Means聚类原理 K-means算法是很典型的基于距离的聚类算法,采用距离作为相似性的评价指标,即认为两个对象的距离越近,其相似度就越大
-
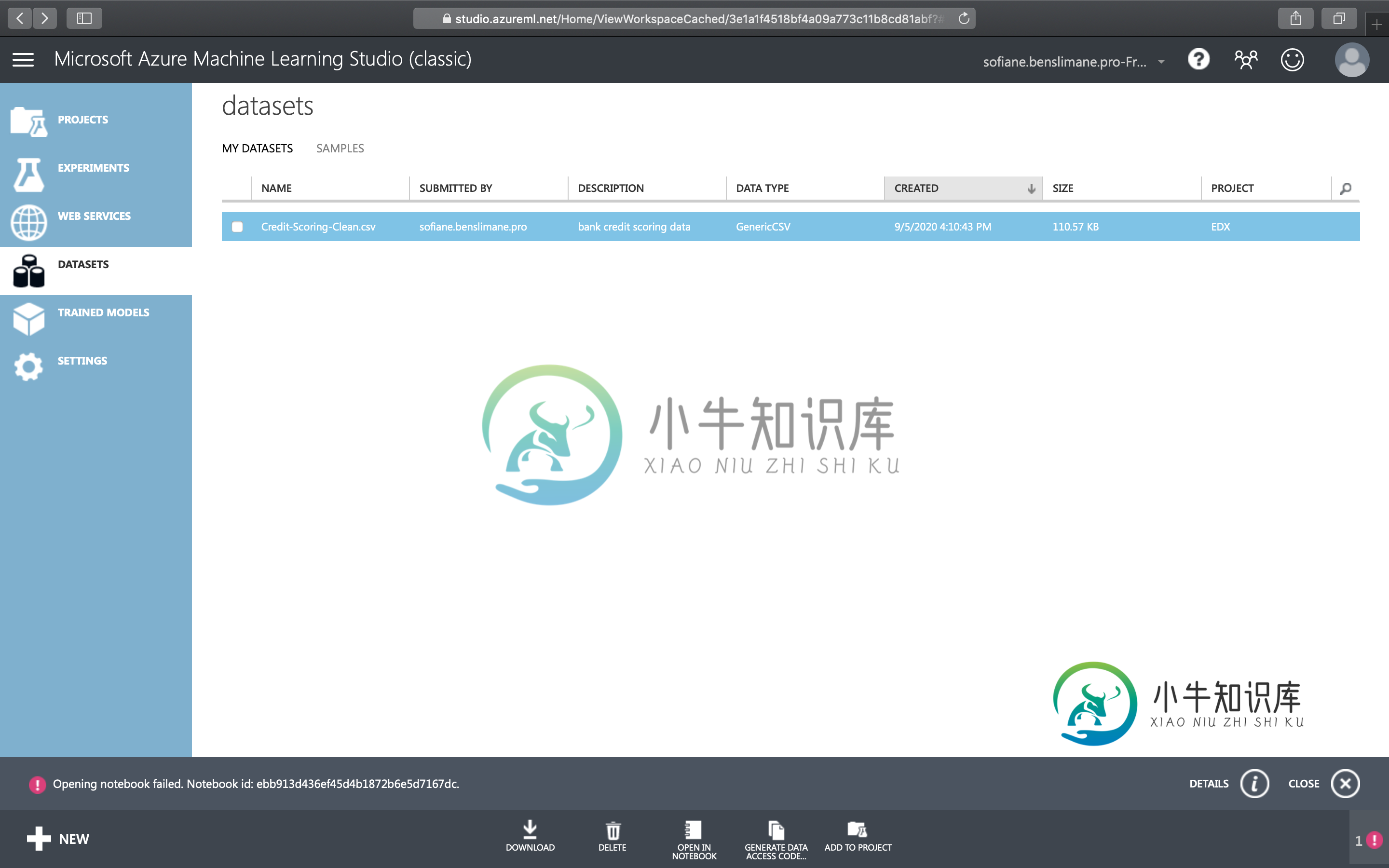 在Azure机器学习工作室打开笔记本
在Azure机器学习工作室打开笔记本我是Azure机器学习的新手。 我试图从Azure机器学习工作室经典中的数据集中打开一个笔记本。 但我得到了这个错误: 打开笔记本失败。笔记本id:ebb913d436ef45d4b1872b6e5d7167dc。 正如你在图片上看到的,我甚至不可能访问左侧菜单中的所有笔记本。
-
机器学习如何比较不同的特征集
假设我有两组不同的特性A和B。我正在尝试确定哪一组特性是最好的。由于我的数据集很小,所以我使用了漏掉一个交叉验证作为最终指标。我正试图弄清楚我的实验装置,我在以下几种方式中做出选择: 1) 将特征集A赋予我的分类器(并可选地运行特征选择),将特征集B赋予同一分类器(也可选地运行特征选择),然后比较这两个分类器之间的LOOCV错误? 2) 将特征集A和B赋予分类器,然后明确地对其进行特征选择,然后根
-
从新的Azure机器学习工作室导出ARFF?
我在新的Azure机器学习工作室工作,但我没有看到像Azure机器学习经典版那样转换为ARFF模块。是否有人知道此功能是否仍然存在以及如何访问它?
-
 Sklearn 与 TensorFlow 机器学习实用指南第二版
Sklearn 与 TensorFlow 机器学习实用指南第二版2006 年,Geoffrey Hinton 等人发表了一篇论文,展示了如何训练能够识别具有最新精度(> 98%)的手写数字的深度神经网络。他们称这种技术为“Deep Learning”。
-
 百度提前批(机器学习/数据挖掘/nlp)
百度提前批(机器学习/数据挖掘/nlp)地图出行服务业务部-T联合 (一面已凉 投递时间:7.11(第一次投递的挂掉了) 变更岗位:7.26 测评邮件:7.26 面试时间:7.30 15:00,挂得很快,吃完饭回来就挂了 总时长:80min,其中项目40min 1、之前在百度做的岗位信息爬取和我的论文有什么关系,为什么离职了? 2、论文里的损失解释一下,设计的模型是微调的 or 预训练的? 3、比赛是自己做的还是组里合作的 4、tran
-
 百度提前批(机器学习/数据挖掘/nlp)
百度提前批(机器学习/数据挖掘/nlp)7.30一面 1.自我介绍 2.纯问项目,主要就是让讲项目,做这个项目的背景,以及具体思路。 3.手撕,(给一个有问题的路径,返回正确路径)
-
 字节ai lab 机器人算法
字节ai lab 机器人算法一面偏向讲论文和比赛,两道coding例行公事 二面聊天,分析论文不足,面向业务场景提问,考察知识面广度,coding二分查找 三面继续聊天,开放性场景,考察思维的深度和广度,coding很难 随缘等通知 #字节#
-
算法练习
我正在做这个算法练习,但我不完全理解公式。下面是练习: 给定一个string str和一对数组(该数组指示字符串中的哪些索引可以交换),返回通过执行允许的交换而产生的词典中最大的字符串。您可以交换任何次数的索引。 示例 对于str=“abdc”和pairs=[[1,4],[3,4]],输出应该是swapLexOrder(str,pairs)=“dbca”。 通过交换给定的索引,可以得到字符串:“c
-
 阿里云 计算机视觉算法 二面面经
阿里云 计算机视觉算法 二面面经1小时,无手撕 你用的对抗损失有什么特点 采集的图片压缩噪声居多,还是说采集噪声居多 facefusion了解吗 讲一下扩散模型原理 ddim推导过吗。。。。。。。 有啥加速采样方法 欧拉采样怎么做的 文生视频有了解吗?(我简单说了下dit。) llm了解吗 clip讲一下 qformer讲一下 无手撕 #阿里##秋招##面经##如何判断面试是否凉了##算法#