
Azure机器学习-空分数结果

我训练了一个模型,在测试集上的测试结果是可以的。现在,我已经将模型保存为“训练模型”,并将一个新的实验转化为一个新的数据集,以便在我没有实际值的情况下进行预测。
通常,训练过的模型给我一个每个实例的评分标签结果。但是现在,打分的标签结果是空的。另外,当我将得分结果转换为CSV时,得分标签列是空的。
更奇怪的是,当我查看score Visualize选项卡的统计数据时,我确实看到了得分值的统计数据。但没有实际得分...
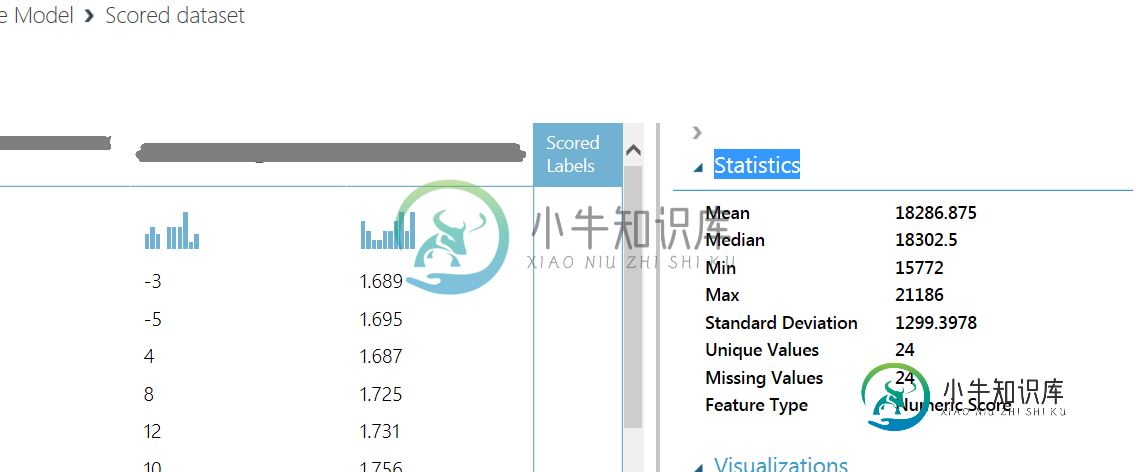
这是虫子吗?还是我忘了什么重要的事?怎么回事;)?
共有1个答案

如果测试数据集缺少相关值,则某些模型的预测实验可能会失败。解决方案是用零值而不是空值填充csv文件。
-
我已经找了几个小时了,但找不到一个能回答这个问题的东西。我已经创建并发布了一个新的Azure机器学习服务,并创建了一个endpoint。我可以使用Postman REST客户机调用服务,但是通过JavaScript网页访问它会返回一个控制台日志,说明该服务启用了CORS。现在,对于我来说,我想不出如何为Azure机器学习服务禁用CORS。如有任何帮助,不胜感激,谢谢!
-
提前感谢普拉迪普
-
每次将一个类别作为正类,其余类别作为负类。此时共有(N个分类器)。在测试的时候若仅有一个分类器预测为正类,则对应的类别标记为最终的分类结果。 【例】当有4个类别的时候,每次把其中一个类别作为正类别,其余作为负类别,共有4种组合,对于这4中组合进行分类器的训练,我们可以得到4个分类器。对于测试样本,放进4个分类器进行预测,仅有一个分类器预测为正类,于是取这个分类器的结果作为预测结果,分类器2预测的结果是类别2,于是这个样本便属于类别
-
监督学习使用标记数据对 (x,y) 学习函数:X\rightarrow Y 。但是,如果我们没有标签呢?这类没有标签的学习方式被称为无监督学习。 无监督学习:如果训练样本全部无标签,则是无监督学习。例如聚类算法,就是根据样本间的相似性对样本集进行聚类试图使类内差距最小化,类间差距最大化。 主要用途: 自动组织数据。 理解某些数据中的隐藏结构。 在低维空间中表示高维数据。
-
Python 有着海量的可用于数据分析、统计以及机器学习的库,这使得 Python 成为很多数据科学家所选择的语言。 下面我们列出了一些被广泛使用的机器学习及其他数据科学应用的 Python 包。 Scipy 技术栈 Scipy 技术栈由一大批在数据科学中被广泛使用的核心辅助包构成,可用于统计分析与数据可视化。由于其丰富的功能和简单易用的特性,这一技术栈已经被视作实现大多数数据科学应用的必备品了。
-
主要内容 前言 课程列表 推荐学习路线 数学基础初级 程序语言能力 机器学习课程初级 数学基础中级 机器学习课程中级 推荐书籍列表 机器学习专项领域学习 致谢 前言 我们要求把这些课程的所有Notes,Slides以及作者强烈推荐的论文看懂看明白,并完成所有的老师布置的习题,而推荐的书籍是不做要求的,如果有些书籍是需要看完的,我们会进行额外的说明。 课程列表 课程 机构 参考书 Notes等其他资