《分布式》专题
-
如何在分布式性能测试中验证JMeter的性能?
我正在做一个RESTAPI性能测试,在这里我必须同时做很多请求。为此,我使用了3个JMeter实例(1个主实例和2个从实例)。 为了让您有更多的竞争,我编写了一个包含2个线程组的JMeter脚本,每个组上有150个线程和一个恒定吞吐量计时器。 下面是我用来启动测试的命令行: 在这个命令行中,吞吐量是我针对3台服务器的总吞吐量(它的值除以vmnb,我的第三个变量,然后每个服务器执行这部分吞吐量),持
-
详解springboot中redis的使用和分布式session共享问题
本文向大家介绍详解springboot中redis的使用和分布式session共享问题,包括了详解springboot中redis的使用和分布式session共享问题的使用技巧和注意事项,需要的朋友参考一下 对于分布式使用Nginx+Tomcat实现负载均衡,最常用的均衡算法有IP_Hash、轮训、根据权重、随机等。不管对于哪一种负载均衡算法,由于Nginx对不同的请求分发到某一个Tomcat,T
-
Java访问Hadoop分布式文件系统HDFS的配置说明
本文向大家介绍Java访问Hadoop分布式文件系统HDFS的配置说明,包括了Java访问Hadoop分布式文件系统HDFS的配置说明的使用技巧和注意事项,需要的朋友参考一下 配置文件 m103替换为hdfs服务地址。 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDF
-
是否为Hazelcast分布式映射配置特定备份节点?
假设一个组织有两个数据中心(为简单起见命名为“A”和“B”),每个数据中心运行多个节点,并且所有这些节点上都有一个Hazelcast集群。假设此集群中有一个分布式地图,其配置为备份计数为1。 是否有办法配置Hazelcast分布式地图,以便将数据中心a中的节点备份到数据中心B中的节点上,反之亦然?这意味着如果丢失单个数据中心,地图数据(和备份)不会丢失?
-
在分布式模式下运行kafka connect时出现的问题
我们开始Kafka,动物园管理员和Kafka连接在第一个盒子。我们也在第二个盒子里开始了Kafka连接。现在,根据confluent文档,我们必须使用REST API启动HDFS连接器(或任何其他连接器)。所以,在这两个框中启动kafka connect之后,我们尝试通过REST API启动connector。我们尝试了以下命令:- 当我们在这里按enter键时,我们得到以下响应: 位于etc/k
-
分布式系统中的消息传递与RPC(Openstack与K8S/Swarm)
OpenStack使用消息传递(我想默认情况下是RabbitMQ?)用于节点之间的通信。另一方面,Kubernetes(谷歌内部博格的血统)使用RPC。Docker的swarm也使用了RPC。两者都是基于grpc/protofbuf的,在Google内部似乎也大量使用。
-
Apache TomEE外部ActiveMQ资源在分布式事务中不回滚
我试图在ApacheTome中实现分布式事务。换句话说,流程是: 消息读取器(即消息驱动bean)从队列(1)中读取并处理一条消息触发: 行动1,2, 托米。xml Springconfig。xml: SpringConfig。xml MyMessageReceiver。爪哇: 我的听众。爪哇: 在更新数据库并将消息发送到传出队列之后,我故意抛出,只是为了测试数据库和message broker的
-
用于只有一个Hazelcast实例的分布式查询的Hazelcast
我们使用分布式查询来搜索带有键的部分值的条目。 我们的基础设施目前只能提供微服务的一个实例。映射是用数据库中的MapStore实现持久化的。 如果微服务关闭,我们会丢失内存中的所有数据,分布式查询也不会返回任何结果。使用loadAllKeys()等通过MapStore初始化内存中的数据不是一种方法,因为我们在数据库中将有大量条目需要加载。
-
使用ServiceStack Redis实现分布式锁定的互斥体违规
我试图使用ServiceStack-Redis库提供的锁定机制实现DLM,并在此进行了描述,但我发现API似乎呈现了一种竞争条件,有时会将相同的锁授予多个客户端。 当运行上述代码来模拟两个客户端在短时间内相继尝试相同的操作时,有三个可能的输出。第一种是互斥体正常工作、客户端按正确顺序进行的最佳情况。第二种情况是当第二个客户端在等待获取锁时超时;也是一个可以接受的结果。然而,问题是,当接近或超过获取
-
第1章 可扩展Web架构与分布式系统之一
原文在:http://www.aosabook.org/en/distsys.html Kate Matsudaira 开源软件如今已成为最大的一些网站的基础组件。随着这些网站的发展,围绕它们的架构出现了许多最佳实践与指导原则。本章将试图阐述设计大规模网站时要考虑的一些关键问题,以及用于实现这些目标(???疑有误)的一些组件。 本章主要讲Web系统,虽然一些内容也适用于其他分布式系统。 1.1 W
-
报错:com+无法与 Microsoft 分布式事务协调程序交
在安装E立方管理平台出现下面的报错时,可以按以下方法解决 原因:E立方管理平台用到了操作系统的分布式事务处理服务,该服务是操作系统的核心服务,如果该服务没有正常启动,就导致上图的错误。导致该核心服务没有正常启动最常见的情况是使用克隆光盘安装的操作系统或者使用一些系统优化的工具把一些关键的服务给关闭了。 解决方法: 程序-->运行-->输入 msdtc -resetlog -->确定
-
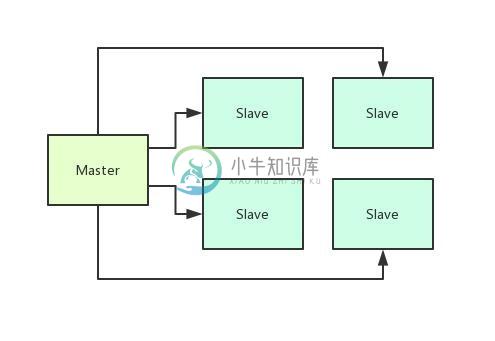 如何设计一个分布式架构的中间件系统?
如何设计一个分布式架构的中间件系统?主要内容:1、Master-Slave架构,2、异步日志持久化机制,3、检查点机制:定时持久化全量数据,4、引入检查点节点,5、总结 & 思考这篇文章,给大家来聊一个生产级的中间件系统的架构设计实践,希望给对中间件系统感兴趣的同学一点启发。 1、Master-Slave架构 这个中间件系统的本质是希望能够用分布式的方式来处理一些数据,但是具体的作用涉及到核心技术,所以这里不能直接说明。 但是他的核心思想,就是把数据分发到很多台机器上来处理,然后需要有一台机器来控制N多台机器的分布式处理,大概如下
-
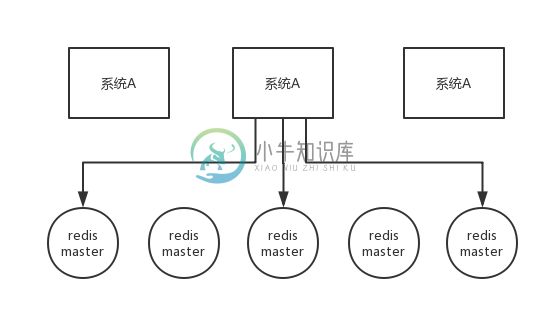 常见面试题-Redis中是如何实现分布式锁的
常见面试题-Redis中是如何实现分布式锁的分布式锁常见的三种实现方式: 数据库乐观锁; 基于Redis的分布式锁; 基于ZooKeeper的分布式锁。 要点 Redis要实现分布式锁,以下条件应该得到满足 互斥性 在任意时刻,只有一个客户端能持有锁。 不能死锁 客户端在持有锁的期间崩溃而没有主动解锁,也能保证后续其他客户端能加锁。 容错性 只要大部分的Redis节点正常运行,客户端就可以加锁和解锁。 实现 可以直接通过 set key v
-
go 有没有能持久化的分布式定时任务库?
写了个基于kratos的服务,基本需求是:可以增删管理定时任务(如配置每天、每周发个统计报告),支持分布式结构,持久化任务。加分项包括:注册回调、结果和日志记录、失败重试等。 看kratos已经支持的transport有两个:asynq和machinery,但似乎都不满足需要基本的持久化任务需求,machinery甚至还不能删除已经添加的任务。 考虑到服务可能会重启,那么添加过的任务如何恢复呢?如
-
Android发布高分辨率图像耗尽内存
问题内容: 各位开发人员,大家好。 我正忙于android从应用程序上传图像。 我也可以使用它(代码将在下面)。 但是,当我发送大图像(10兆像素)时,我的应用程序因内存不足异常而崩溃。 一个解决方案是使用压缩,但是如果我要发送完整尺寸的图像怎么办? 我想也许有些东西在溪流中,但我不喜欢溪流。也许urlconnection可能有帮助,但我真的不知道。 我给文件名命名为File [0到9999] .