《分布式》专题
-
相关软件介绍/HBase/HBase分布式安装手册
一、安装准备 1、下载HBASE 0.20.5版本:http://www.apache.org/dist/hbase/hbase-0.20.5/ 2、JDK版本:jdk-6u20-linux-i586.bin 3、操作系统:Linux s132 2.6.9-78.8AXS2smp #1 SMP Tue Dec 16 02:42:55 EST 2008 x86_64 x86_64 x86_64 GN
-
 基于Redis实现分布式应用限流的方法
基于Redis实现分布式应用限流的方法本文向大家介绍基于Redis实现分布式应用限流的方法,包括了基于Redis实现分布式应用限流的方法的使用技巧和注意事项,需要的朋友参考一下 限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务。 前几天在DD的公众号,看了一篇关于使用 瓜娃 实现单应用限流的方案 --》原文,参考《redis in action》 实现了一个jedis
-
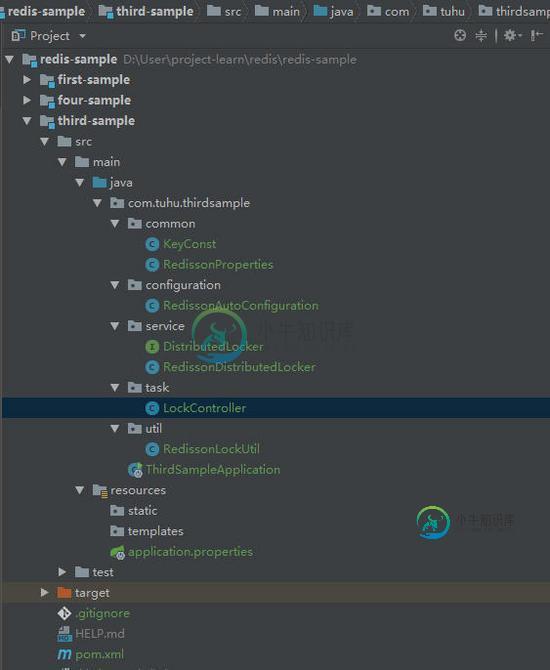 SpringBoot集成Redisson实现分布式锁的方法示例
SpringBoot集成Redisson实现分布式锁的方法示例本文向大家介绍SpringBoot集成Redisson实现分布式锁的方法示例,包括了SpringBoot集成Redisson实现分布式锁的方法示例的使用技巧和注意事项,需要的朋友参考一下 上篇 《SpringBoot 集成 redis 分布式锁优化》对死锁的问题进行了优化,今天介绍的是 redis 官方推荐使用的 Redisson ,Redisson 架设在 redis 基础上的 Java 驻内存
-
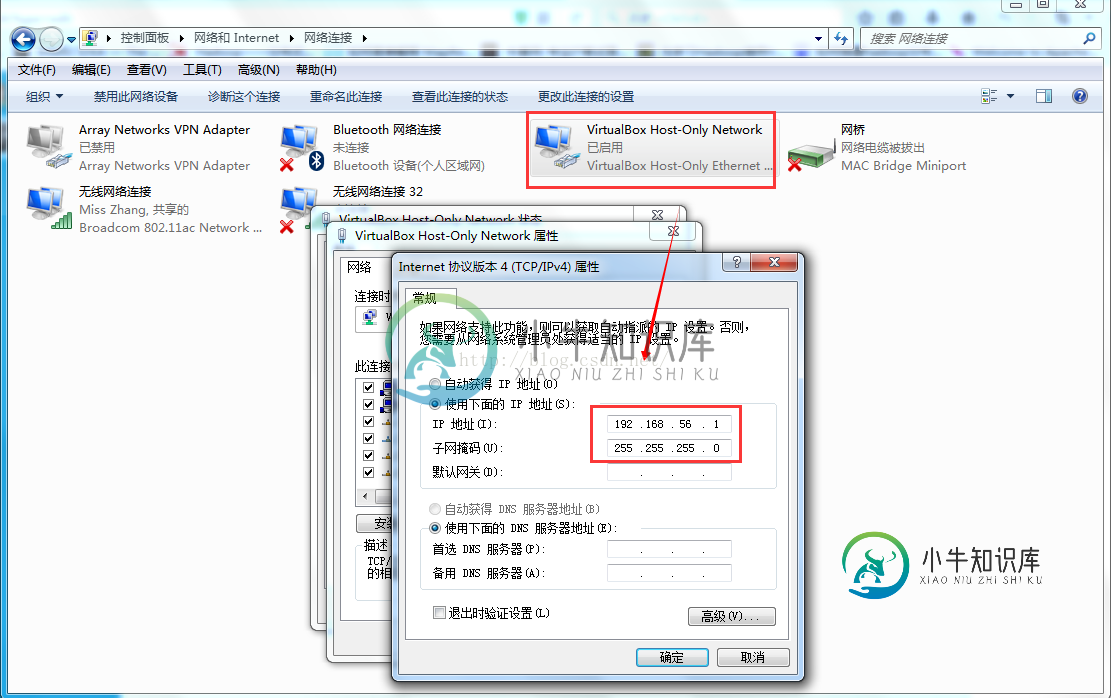 基于CentOS的Hadoop分布式环境的搭建开发
基于CentOS的Hadoop分布式环境的搭建开发本文向大家介绍基于CentOS的Hadoop分布式环境的搭建开发,包括了基于CentOS的Hadoop分布式环境的搭建开发的使用技巧和注意事项,需要的朋友参考一下 首先,要说明的一点的是,我不想重复发明轮子。如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录。 其次,我要说的是我也是新手,对于Hadoop也不是很熟悉。但是就是想实际搭建好环境,看看他的庐山真面目,还好,
-
Tensorflow:在分布式培训中使用参数服务器
问题内容: 尚不清楚参数服务器如何知道分布式张量流训练中的操作。 例如,在此SO问题中,以下代码用于配置参数服务器和工作程序任务: 如何指示给定的任务应该是参数服务器?参数是一种默认的任务行为吗?您还能/应该告诉参数服务任务做什么? 编辑 :这个SO问题解决了我的一些问题:“逻辑确保将Variable对象均匀分配给充当参数服务器的工作程序。” 但是参数服务器如何知道它是参数服务器?是否足够? 问题
-
Hadoop 2.x伪分布式环境搭建详细步骤
本文向大家介绍Hadoop 2.x伪分布式环境搭建详细步骤,包括了Hadoop 2.x伪分布式环境搭建详细步骤的使用技巧和注意事项,需要的朋友参考一下 本文以图文结合的方式详细介绍了Hadoop 2.x伪分布式环境搭建的全过程,供大家参考,具体内容如下 1、修改hadoop-env.sh、yarn-env.sh、mapred-env.sh 方法:使用notepad++(beifeng用户)打开这三
-
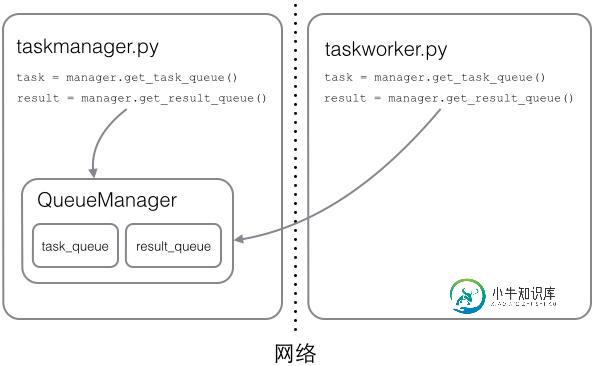 在Python程序中实现分布式进程的教程
在Python程序中实现分布式进程的教程本文向大家介绍在Python程序中实现分布式进程的教程,包括了在Python程序中实现分布式进程的教程的使用技巧和注意事项,需要的朋友参考一下 在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上。 Python的multiprocessing模块不但支持多进程,其中man
-
瘦客户端的ignite ClientCache是否支持分布式锁
现在我使用的是瘦客户机的ignite ClientCache,我没有找到ClientCache的分布式锁,如果要使用分布式锁,必须使用ignition.start()
-
基于Spring批处理和AMQP的分布式批处理
我想分散加工大批量。这个想法是使用Spring Batch在云中激发一堆AMQP消费者,然后加载廉价的任务(如项目ID)并将它们提交给AMQP交换。结果的书写将由消费者自己完成。 null
-
Hadoop伪分布式java.net.ConnectException:在虚拟框上拒绝连接
我已经在ubuntu上安装了hadoop,它运行在VirtualBox上。当我第一次安装hadoop时,我可以毫无问题地启动hdfs和创建目录。 但是当我重新启动虚拟机后,当尝试在HDFS上运行ls命令时,我得到了“拒绝连接”的错误。然后,我根据Hadoop集群设置在sshd_config中添加了“端口9000”-java.net.connectException:Connection Relec
-
Karaf中的分布式OSGI消费者服务未启动
我刚刚开始使用动物园管理员在卡拉夫的DOSGi。我在Karaf的一个实例中提供服务,在另一个实例中提供消费者。服务端运行良好。一旦发布,我可以在安装了Zookeeper服务器的Karaf控制台中使用log:display命令查看它,并且我也可以通过浏览器访问wsdl。问题出在消费端。当服务启动时,它应该写一条消息(下面的ref代码),但是它从来没有发生。消费者代码: 和component.xml:
-
关于分布式模式下运行在hadoop上的hbase
Hadoop版本=2.4.1 hbase版本=0.98.6 我已经在下面的conf上启动并顺利运行了hadoop: 107.108.86.119-hadoop namenode,secondarynamenode 107.109.155.100-datanode1 107.109.155.102-datanode2 现在我按以下方式安装hbase:- 107.108.86.114:-hmaster
-
 在 Azure cosmos DB 中维护分布式增量计数器
在 Azure cosmos DB 中维护分布式增量计数器我对cosmos DB相当陌生,并试图了解azure cosmos DB SDK为修补文档提供的Java的增量操作。我需要在容器中的一个Documents中维护一个增量计数器。文档看起来像这样- 现在,在我的应用程序中,每当一个动作发生时,我想将这个计数器的值增加1。为此,我使用了宇宙空间运算。我在这里添加了一个增量,就像这样< code > cosmos patch . increment("/
-
BigMemory 4.0.5 Terrocatta分布式Hibernate二级缓存无法配置
我正在使用Bigmemory Max 4.0.5,因为terracotta为我的应用程序分配缓存作为hibernate二级缓存,但是我在服务器启动时遇到了以下异常。 原因:com.tc.config.schema.setup.ConfigurationSetupException: 来自 'localhost:9510' 服务器的基本配置中的配置数据不符合 Terracotta 架构: [0]:
-
如何在分布式测试中使用JMeter Simple Table Server?
我正在尝试在分布式测试中设置JMeter Simple Table Server(STS)。在本地,在主控制器上,STS服务器已启动,我可以使用