《分布式》专题
-
 整理分布式唯一ID的六种生成方案
整理分布式唯一ID的六种生成方案主要内容:(1)方案一:独立数据库自增id,(2)方案二:uuid,(3)方案三:获取系统当前时间,(4)方案四:snowflake算法的思想分析,(5)snowflake算法的代码实现,(6)snowflake算法一个小小的改进思路上一篇文章,我们聊了一下分库分表相关的一些基础知识,具体可以参见:《用真实业务场景告诉你,高并发下如何设计数据库架构?》。 这篇文章,我们就接着分库分表的知识,来具体聊一下全局唯一id如何生成。 在分库分表之后你必然要面对的一个问题,就是id咋生成? 因为要是一个表
-
第四章 Hadoop的安装 - 3. Hadoop 2.7.2完全分布式
一 生产环境描述 1 网络环境 hadoopmaster 192.168.1.159 hadoopslave1 192.168.1.76 hadoopslave2 192.168.1.166 2 软件环境 JDK 7U79 Hadoop 2.7.2 二 hadoopmaster主机配置 1 JDK设置 chu888chu888@hadoopmaster:~$ ls jdk-7u79-linux-x
-
第四章 Hadoop的安装 - 1.Hadoop 2.6.2完全分布式
1网络拓扑 192.168.1.80 Master 192.168.1.82 Slave1 192.168.1.84 Slave2 2安装JDK 所有实验主机都需要正确的安装JDK,具体操作方法 chu888chu888@ubuntu1:~$ tar xvfz jdk-8u65-linux-x64.gz chu888chu888@ubuntu1:~$ sudo cp -r jdk1.8.0_65/
-
分布式安装 - 邮件/短信/微信发送接口
监控系统产生报警事件之后需要发送报警邮件或者报警短信,各个公司可能有自己的邮件服务器,有自己的邮件发送方法;有自己的短信通道,有自己的短信发送方法。falcon为了适配各个公司,在接入方案上做了一个规范,需要各公司提供http的短信和邮件发送接口。 短信发送http接口: method: post params: - content: 短信内容 - tos: 使用逗号分隔的多个手机号 邮件
-
一文读懂 hadoop、hbase、hive、spark 分布式系统架构
本文结构 首先,我们来分别部署一套hadoop、hbase、hive、spark,在讲解部署方法过程中会特殊说明一些重要配置,以及一些架构图以帮我们理解,目的是为后面讲解系统架构和关系打基础。 之后,我们会通过运行一些程序来分析一下这些系统的功能 最后,我们会总结这些系统之间的关系 分布式hadoop部署 首先,在http://hadoop.apache.org/releases.html找到最新
-
反射(Reflection), 对象空间(ObjectSpace),和分布式Ruby(Distributed Ruby)
One of the many advantages of dynamic languages such as Ruby is the ability tointrospect---to examine aspects of the program from within the program itself. Java, for one, calls this featurereflection
-
Seata分布式Go Server正式开源-TaaS设计简介
前言 TaaS 是 Seata 服务端(TC, Transaction Coordinator)的一种高可用实现,使用 Golang 编写。Taas 由InfiniVision (http://infinivision.cn) 贡献给Seata开源社区。现已正式开源,并贡献给 Seata 社区。 在Seata开源之前,我们内部开始借鉴GTS以及一些开源项目来实现分布式事务的解决方案TaaS(Tra
-
通过 AOP 动态创建/关闭 Seata 分布式事务
通过GA大会上滴滴出行的高级研发工程陈鹏志的在滴滴两轮车业务中的实践,发现动态降级的必要性是非常的高,所以这边简单利用spring boot aop来简单的处理降级相关的处理,这边非常感谢陈鹏志的分享! 可利用此demo项目地址 通过以下代码改造实践. 准备工作 1.创建测试用的TestAspect: package org.test.config; import java.lang.ref
-
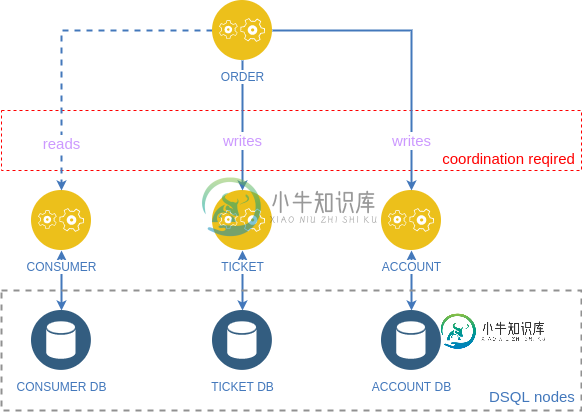 分布式 SQL 工具是否可以用作分布式事务协调的两阶段提交或 sagas 模式的替代方案?
分布式 SQL 工具是否可以用作分布式事务协调的两阶段提交或 sagas 模式的替代方案?我目前正在阅读微服务模式,它说分布式事务主要有两种方法:两阶段提交(2PC)和sagas模式。 此外,我听说了目前正在发展的分布式SQL(DSQL)工具,如CockroachDB、YuGabyteDB和YDB,它们还通过自己的低级db节点通信支持分布式ACID类事务。 那么问题是,后者是否可以作为前者的替代方案? 为了说明这个问题,考虑以下典型的微服务分布式事务示例。这里我们需要2PC或sagas
-
父相对布局内子线性布局的百分比(加权)高度
我直接在相对布局中有两个线性布局。 我希望第一个LinearLayout占据75%的高度,接下来占据25%。我如何实现这一点? 例如 我希望线性布局1使用可用高度的75%,线性布局2使用25%<没有为LinearLayout定义layout_weight,因此显然它不起作用。 我有什么办法可以做到这一点吗? 这似乎是一个非常常见的场景,所以我几乎可以肯定这个问题以前被问过。 但我似乎没有找到它。请
-
 python如何生成各种随机分布图
python如何生成各种随机分布图本文向大家介绍python如何生成各种随机分布图,包括了python如何生成各种随机分布图的使用技巧和注意事项,需要的朋友参考一下 在学习生活中,我们经常性的发现有很多事物背后都有某种规律,而且,这种规律可能符合某种随机分布,比如:正态分布、对数正态分布、beta分布等等。 所以,了解某种分布对一些事物有更加深入的理解并能清楚的阐释事物的规律性。现在,用python产生一组随机数据,来演示这些分布
-
推荐的Python发布/订阅/分发模块?
问题内容: Pypubsub为您的Python应用程序提供了一种解耦其组件的简单方法:应用程序的某些部分可以发布消息(带有或不带有数据),其他部分可以订阅/接收它们。这允许消息“发件人”和消息“侦听器”彼此不知道: 一个不需要导入另一个 发件人不需要知道 “谁”得到消息, 监听者将如何处理数据, 甚至任何侦听器都将获取消息数据。 同样,听众也不必担心消息的来源。 这是用于实现模型-视图-控制器体系
-
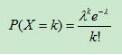 Python数据可视化:泊松分布详解
Python数据可视化:泊松分布详解本文向大家介绍Python数据可视化:泊松分布详解,包括了Python数据可视化:泊松分布详解的使用技巧和注意事项,需要的朋友参考一下 一个服从泊松分布的随机变量X,表示在具有比率参数(rate parameter)λ的一段固定时间间隔内,事件发生的次数。参数λ告诉你该事件发生的比率。随机变量X的平均值和方差都是λ。 代码实现: 以上这篇Python数据可视化:泊松分布详解就是小编分享给大家的全部
-
 github“发布此分支失败”窗口错误
github“发布此分支失败”窗口错误我是git新手,我昨天刚刚下载了它。作为我的第一个在线(非本地)存储库的测试,我提交了一个无用的文本文件,然后点击发布。过了一会儿,我得到了这个非常非描述性的错误: 所以我知道我不能发布到这个分支。只有一个,它是主分支。有人有任何关于可能导致此错误的进一步信息吗? 顺便说一句,我的合作伙伴已经成功地将文件上传到同一个回购协议,但我没有得到任何迹象表明发生了这种情况。这是否意味着我在某种程度上与回购
-
分布追踪与弹性叠加可视化
这是我的控制台中的日志格式。我正在使用spring cloud stream将我的日志从应用程序传输到logstash,这是logstash中的日志解析格式 这是我的logstash.conf 这是我在log-stash控制台中的输出。这是解析异常 {“message”=>“[{\”traceid\“:\”411a0496b048bcf4\“,\”parentId\“:\”8d40fcfea926