
第四章 Hadoop的安装 - 3. Hadoop 2.7.2完全分布式
一 生产环境描述
1 网络环境
- hadoopmaster 192.168.1.159
- hadoopslave1 192.168.1.76
- hadoopslave2 192.168.1.166
2 软件环境
- JDK 7U79
- Hadoop 2.7.2
二 hadoopmaster主机配置
1 JDK设置
chu888chu888@hadoopmaster:~$ lsjdk-7u79-linux-x64.gzchu888chu888@hadoopmaster:~$ sudo tar xvfz jdk-7u79-linux-x64.gzchu888chu888@hadoopmaster:~$ lsjdk1.7.0_79 jdk-7u79-linux-x64.gzchu888chu888@hadoopmaster:~$ sudo cp -r jdk1.7.0_79/ /usr/lib/jvm/chu888chu888@hadoopmaster:~$ cd /usr/lib/jvmchu888chu888@hadoopmaster:/usr/lib/jvm$ lsbin db jre LICENSE README.html src.zip THIRDPARTYLICENSEREADME.txtCOPYRIGHT include lib man release THIRDPARTYLICENSEREADME-JAVAFX.txtchu888chu888@hadoopmaster:/usr/lib/jvm$chu888chu888@ubuntu1:/usr/lib/jvm$ sudo nano /etc/profile修改内容如下,注意大小写,在环境变量中的配置中,有一点需要指出就是如果只是编辑~/.profile的话这个变量的生效只是针对当前用户的.如果想要其在全局生效的话,建议更新/etc/profile,这是一个全局的.
/etc/profile的内容如下:
export JAVA_HOME=/usr/lib/jvm/export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH
这里面有一个小的体验技巧,我建议将所有需要的环境变量配置加入到/etc/profile中,这是全局变量.
export JAVA_HOME=/usr/lib/jvm/export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATHexport JAVA_HOME=/usr/lib/jvm/export HADOOP_INSTALL=/usr/local/hadoopexport PATH=$PATH:$HADOOP_INSTALL/binexport PATH=$PATH:$JAVA_HOME/binexport PATH=$PATH:$HADOOP_INSTALL/sbinexport HADOOP_MAPRED_HOME=$HADOOP_INSTALLexport HADOOP_COMMON_HOME=$HADOOP_INSTALLexport HADOOP_HDFS_HOME=$HADOOP_INSTALLexport YARN_HOME=$HADOOP_INSTALLexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
还有一个问题就是,在启动hadoop的时候经常会出现,找不到JAVA_HOME的问题,这个问题可以通过修改hadoop环境变量来解决,直接写死变量就可以了.
测试环境变量是不是生效
chu888chu888@hadoopmaster:/usr/lib/jvm$ source /etc/profilechu888chu888@hadoopmaster:/usr/lib/jvm$ envXDG_SESSION_ID=1TERM=xterm-256colorSHELL=/bin/bashSSH_CLIENT=192.168.1.23 49818 22OLDPWD=/home/chu888chu888SSH_TTY=/dev/pts/0JRE_HOME=/usr/lib/jvm//jreUSER=chu888chu888LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arj=01;31:*.taz=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lz=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.axv=01;35:*.anx=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=00;36:*.au=00;36:*.flac=00;36:*.mid=00;36:*.midi=00;36:*.mka=00;36:*.mp3=00;36:*.mpc=00;36:*.ogg=00;36:*.ra=00;36:*.wav=00;36:*.axa=00;36:*.oga=00;36:*.spx=00;36:*.xspf=00;36:MAIL=/var/mail/chu888chu888PATH=/usr/lib/jvm//bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/gamesPWD=/usr/lib/jvmJAVA_HOME=/usr/lib/jvm/LANG=en_US.UTF-8SHLVL=1HOME=/home/chu888chu888LANGUAGE=en_US:enLOGNAME=chu888chu888CLASSPATH=.:/usr/lib/jvm//lib:/usr/lib/jvm//jre/libSSH_CONNECTION=192.168.1.23 49818 192.168.1.159 22LESSOPEN=| /usr/bin/lesspipe %sXDG_RUNTIME_DIR=/run/user/1000LESSCLOSE=/usr/bin/lesspipe %s %s_=/usr/bin/envchu888chu888@hadoopmaster:/usr/lib/jvm$ java -versionjava version "1.7.0_79"Java(TM) SE Runtime Environment (build 1.7.0_79-b15)Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)chu888chu888@hadoopmaster:/usr/lib/jvm$
2 IP设置
chu888chu888@hadoopmaster:/etc/network$ lsif-down.d if-post-down.d if-pre-up.d if-up.d interfaces interfaces.d runchu888chu888@hadoopmaster:/etc/network$ sudo nano interfaces
interfaces的内容如下
auto loiface lo inet loopbackauto eth0iface eth0 inet staticaddress 192.168.1.159netmask 255.255.255.0gateway 192.168.1.1
/etc/resolv.conf的内容
nameserver 192.168.1.1
3 Hadoop相关环境变量的设置
创建hadoop用户组创建hadoop用户chu888chu888@hadoopmaster:~$ sudo addgroup hadoop[sudo] password for chu888chu888:Adding group `hadoop' (GID 1001) ...Done.chu888chu888@hadoopmaster:~$ sudo adduser -ingroup hadoop hadoopAdding user `hadoop' ...Adding new user `hadoop' (1001) with group `hadoop' ...Creating home directory `/home/hadoop' ...Copying files from `/etc/skel' ...Enter new UNIX password:Retype new UNIX password:passwd: password updated successfullyChanging the user information for hadoopEnter the new value, or press ENTER for the defaultFull Name []:Room Number []:Work Phone []:Home Phone []:Other []:Is the information correct? [Y/n] y给hadoop用户添加权限,打开/etc/sudoers文件root ALL=(ALL:ALL) ALLhadoop ALL=(ALL:ALL) ALL
4 hosts文件修改
所有的主机的hosts都需要修改,在这里我吃了一个大亏,如果在etc配置文件中直接用Ip的话,可能会出现Datanode链接不上Namenode的现象.
127.0.0.1 localhost192.168.1.159 hadoopmaster192.168.1.76 hadoopslave1192.168.1.166 hadoopslave2
5 SSH无密码登录
步骤一用ssh-key-gen在hadoopmaster主机上创建公钥与密钥
需要注意一下,一定要用hadoop用户生成公钥,因为我们是免密钥登录用的是hadoophadoop@hadoopmaster:~$ ssh-keygen -t rsaGenerating public/private rsa key pair.Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):Created directory '/home/hadoop/.ssh'.Enter passphrase (empty for no passphrase):Enter same passphrase again:Your identification has been saved in /home/hadoop/.ssh/id_rsa.Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.The key fingerprint is:cf:98:06:01:29:81:ff:82:5b:d3:6d:5d:53:b6:a7:75 hadoop@hadoopmasterThe key's randomart image is:+--[ RSA 2048]----+| ..... ||. . .. o || . . . o . || . . o . o E|| . o ...S. . + . ||. + o o..= . || o o . + o ||. . || |+-----------------+
步骤二保证hadoopmaster登录自已是有效的
cd .sshcat ./id_rsa.pub >> ./authorized_keys
步骤三将公钥拷贝到其他主机上
scp ~/.ssh/id_rsa.pub hadoop@hadoopslave1:/home/hadoop/scp ~/.ssh/id_rsa.pub hadoop@hadoopslave2:/home/hadoop/
步骤四 在其他二个节点上做的工作
mkdir ~/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略cat ~/id_rsa.pub >> ~/.ssh/authorized_keysrm ~/id_rsa.pub # 用完就可以删掉了
6 资源限制配置
此步骤要求在hadoopmaster hadoopslave1 hadoopslave2都要进行配置,以防止处理达到机器文件上限
1通过修改/etc/security/limits.conf追击参数进行配置
HBASE和其他的数据库软件一样会同时打开很多文件,Linux默认的ulimit值是1024,这对HBASE来说太小了,当使用诸如bulkload这种工具导入数据的时候会得到这样的异常信息:java.io.IOException:Too many open files.我们需要改变这个值.这是对操作系统的操作,而不是通过HBASE配置文件完成的,我们可以大致估算ulimit值需要配置为多大,例如:每个列族至少有一个存储文件(HFile),每个被加载的Region可能管理多达5或6个列族所对应的存储文件,用于存储文件个数乘于列族数再乘以每个RegionServer中的RegIon数量得到RegionServer主机管理的存储文件数量.假如每个Region有3个列族,每个列族平均有3个存储文件,每个RegionServer有100个region,将至少需要33100=900个文件.这些存储文件会被客户端大量的操作,涉及大量的磁盘操作.
#* soft core 0#root hard core 100000#* hard rss 10000#@student hard nproc 20#@faculty soft nproc 20#@faculty hard nproc 50#ftp hard nproc 0#ftp - chroot /ftp#@student - maxlogins 4hadoop - nofile 65535hadoop - nproc 32000
2 通过修改 hdfs-site.xml解决同时处理文件上限的参数
Hadoop的Datanode有一个用于设置同时处理文件的上限个数的参数,这个参数叫xcievers,在启动之前,先确认有没有配置hadoop的这个参数,默认值是256,这对于一个任务很多的集群来说,实在太小了.
<property><name>dfs.datanode.max.xcievers</name><value>12500</value></property>
三 hadoopslave1 2主机配置
1 JDK安装
同上
2 IP设置
同上
3 Hadoop相关环境变量的设置
同上
4 hosts文件修改
同上
5 SSH无密码登录
同上
四 hadoopmaster的安装
1 安装
以下操作都要以hadoop用户身份进行
chu888chu888@hadoopslave1:~$ sudo tar xvfz jdk-7u79-linux-x64.gzhadoop@hadoopmaster:~$ sudo cp -r hadoop-2.7.2 /usr/local/hadoophadoop@hadoopmaster:~$ sudo chmod -R 775 /usr/local/hadoop/hadoop@hadoopmaster:~$ sudo chown -R hadoop:hadoop /usr/local/hadoop
这里面有一个小的体验技巧,我建议将所有需要的环境变量配置加入到/etc/profile中,这是全局变量.
export JAVA_HOME=/usr/lib/jvm/export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATHexport JAVA_HOME=/usr/lib/jvm/export HADOOP_INSTALL=/usr/local/hadoopexport PATH=$PATH:$HADOOP_INSTALL/binexport PATH=$PATH:$JAVA_HOME/binexport PATH=$PATH:$HADOOP_INSTALL/sbinexport HADOOP_MAPRED_HOME=$HADOOP_INSTALLexport HADOOP_COMMON_HOME=$HADOOP_INSTALLexport HADOOP_HDFS_HOME=$HADOOP_INSTALLexport YARN_HOME=$HADOOP_INSTALLexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/nativeexport HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib"
还有一个问题就是,在启动hadoop的时候经常会出现,找不到JAVA_HOME的问题,这个问题可以通过修改hadoop环境变量来解决,直接写死变量就可以了.
hadoop@hadoopmaster:/usr/local/hadoop/etc/hadoop$ lscapacity-scheduler.xml hadoop-metrics2.properties httpfs-signature.secret log4j.properties ssl-client.xml.exampleconfiguration.xsl hadoop-metrics.properties httpfs-site.xml mapred-env.cmd ssl-server.xml.examplecontainer-executor.cfg hadoop-policy.xml kms-acls.xml mapred-env.sh yarn-env.cmdcore-site.xml hdfs-site.xml kms-env.sh mapred-queues.xml.template yarn-env.shhadoop-env.cmd httpfs-env.sh kms-log4j.properties mapred-site.xml.template yarn-site.xmlhadoop-env.sh httpfs-log4j.properties kms-site.xml slaveshadoop@hadoopmaster:/usr/local/hadoop/etc/hadoop$ sudo nano hadoop-env.sh$ more hadoop-env.shexport JAVA_HOME=/usr/lib/jvm/
2 配置集群环境
集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
3 配置文件内容-slaves
文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 hadoopmaster 节点仅作为 NameNode 使用。
本教程让 hadoopmaster 节点仅作为 NameNode 使用,因此将文件中原来的 localhost 删除,只添加二行内容:hadoopslave1 hadoopslave2。
hadoop@hadoopmaster:/usr/local/hadoop/etc/hadoop$ more slaveshadoopslave1hadoopslave2
4 配置文件内容-core-site.xml
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoopmaster:9000</value></property><property><name>hadoop.tmp.dir</name><value>file:/usr/local/hadoop/tmp</value><description>Abase for other temporary directories.</description></property></configuration>
5 配置文件内容 hdfs-site.xml
dfs.replication 一般设为 3,但我们只有二个 Slave 节点,所以 dfs.replication 的值还是设为 2:
<configuration><property><name>dfs.namenode.secondary.http-address</name><value>hadoopmaster:50090</value></property><property><name>dfs.replication</name><value>2</value></property><property><name>dfs.namenode.name.dir</name><value>file:/usr/local/hadoop/tmp/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/tmp/dfs/data</value></property></configuration>
6 配置文件 - mapred-site.xml
(可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下:
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>hadoopmaster:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>hadoopmaster:19888</value></property></configuration>
7 配置文件 - yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>hadoopmaster</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
五 hadoopslave1 2节点需要做的
首先通过sftp把hadoop配置好的hadoop打包,之后转输到Slave节点上,配置好环境变量JDK PATH SSH 基本上与Master是一样的.
配置好后,将 Master 上的 /usr/local/Hadoop 文件夹复制到各个节点上。因为之前有跑过伪分布式模式,建议在切换到集群模式前先删除之前的临时文件。
在 Master 节点上执行:
cd /usr/localsudo rm -r ./hadoop/tmpsudo rm -r ./hadoop/logs/*tar -cvfz ~/hadoop.master.tar.gz ./hadoop
在Slave节点上执行:
sudo rm -r /usr/local/hadoop # 删掉旧的(如果存在)sudo tar -xvfz ~/hadoop.master.tar.gz -C /usr/localsudo chown -R hadoop:hadoop /usr/local/hadoop
六 开始启动集群
hdfs namenode -format # 首次运行需要执行初始化,之后不需要在Master上执行:$start-dfs.sh$start-yarn.sh$mr-jobhistory-daemon.sh start historyserverCentos6.X需要关闭防火墙sudo service iptables stop # 关闭防火墙服务sudo chkconfig iptables off # 禁止防火墙开机自启,就不用手动关闭了Cent7systemctl stop firewalld.service # 关闭firewallsystemctl disable firewalld.service # 禁止firewall开机启动
之后分别在Master与Slave上执行jps,会看到不同的结果.缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
$jps$hdfs dfsadmin -report可以访问http://192.168.1.159:50070/ 查看结果
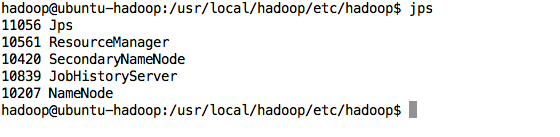

七 执行分布式的实验-分布式存储
执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录:$ hdfs dfs -mkdir -p /user/hadoop将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中:$ hdfs dfs -mkdir input$ hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
八 执行分布式的实验-MapReduce
执行MapReduce作业
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep /user/hadoop/input /user/hadoop/output 'dfs[a-z.]+'查看http://192.168.1.159:8088/cluster看结果
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。
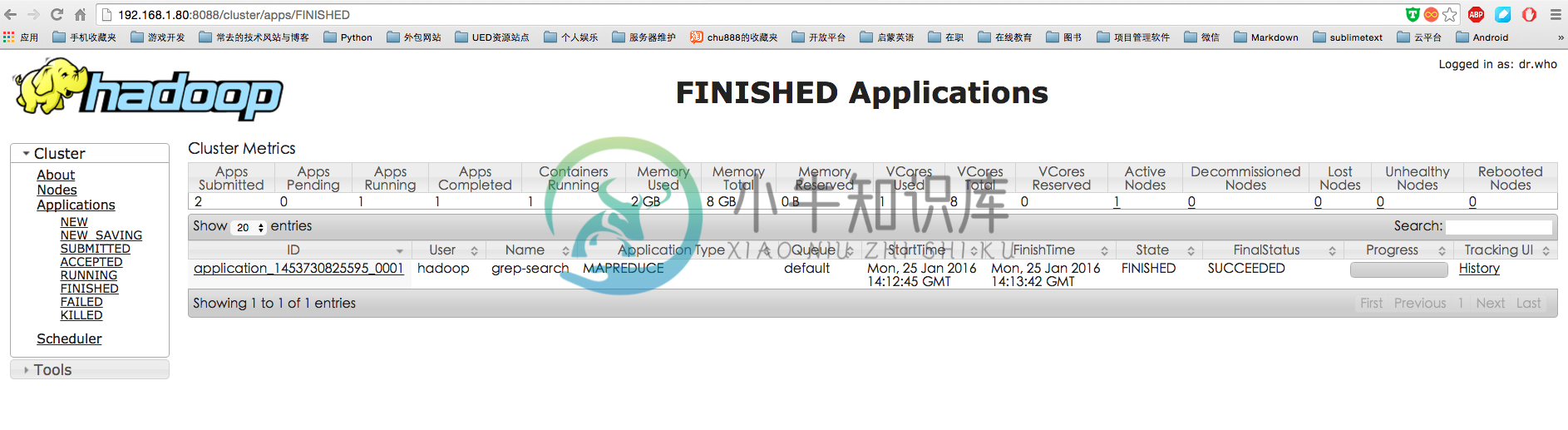
同样可以通过 Web 界面查看任务进度 http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
关闭集群stop-yarn.shstop-dfs.shmr-jobhistory-daemon.sh stop historyserver
九 同步时间
在安装hadoop环境的过程中,时间同步是非常重要的一个服务.因为分布式系统如果时间不同步会造成系统中的许多问题.
1 在线安装
ntp在线安装的方式很简单,只需要执行以下命令即可帮你安装好ntp以及所有的依赖包
sudo apt-get install ntp
2 离线安装
如果要离线安装,那么就需要下载ntp安装包和依赖包。我们可以在一个有线环境下运行上面的在线安装,然后到/var/cache/apt/archives这个目录下拷贝完整的ntp安装包和依赖包。
dpkg -i libopts25_1%3a5.12-0.1ubuntu1_amd64.debdpkg -i ntp_1%3a4.2.6.p3+dfsg-1ubuntu3.1_amd64.deb
当然还有更加简单的方法,将下载的deb包拷贝到/var/cache/apt/archives目录下,然后在执行一下命令同样可以安装。
sudo apt-get install ntp
安装完毕以后我们可以查看服务是否启动,执行以下命令:
hadoop@hadoopmaster:~$ sudo service --status-all[ + ] acpid[ + ] apparmor[ ? ] apport[ + ] atd[ ? ] console-setup[ + ] cron[ - ] dbus[ ? ] dns-clean[ + ] friendly-recovery[ - ] grub-common[ ? ] irqbalance[ ? ] killprocs[ ? ] kmod[ ? ] networking[ + ] ntp[ ? ] ondemand[ ? ] pppd-dns[ - ] procps[ ? ] rc.local[ + ] resolvconf[ - ] rsync[ + ] rsyslog[ ? ] screen-cleanup[ ? ] sendsigs[ - ] ssh[ - ] sudo[ + ] udev[ ? ] umountfs[ ? ] umountnfs.sh[ ? ] umountroot[ - ] unattended-upgrades[ - ] urandom
可以看到ntp服务已经启动([+]表示已经启动。)
3 配置文件 /etc/ntp.conf
建议在配置之前进行备份
driftfile /var/lib/ntp/ntp.driftstatistics loopstats peerstats clockstatsfilegen loopstats file loopstats type day enablefilegen peerstats file peerstats type day enablefilegen clockstats file clockstats type day enableserver ntp.ubuntu.comrestrict -4 default kod notrap nomodify nopeer noqueryrestrict -6 default kod notrap nomodify nopeer noqueryrestrict 192.168.1.0 mask 255.255.255.0 nomodifyrestrict 127.0.0.1restrict ::1
4 同步时间
sudo ntpdate 192.168.1.159
十 FAQ
1 出现的问题
hadoop@hadoopmaster:~$ start-dfs.sh16/07/18 20:45:04 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicableStarting namenodes on [hadoopmaster]hadoopmaster: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-hadoopmaster.outhadoopslave1: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-hadoopslave1.outhadoopslave2: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-hadoopslave2.outStarting secondary namenodes [hadoopmaster]hadoopmaster: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-hadoopmaster.out16/07/18 20:45:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
解决方法
首先下载hadoop-native-64-2.4.0.tar:http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.4.0.tar如果你是hadoop2.6的可以下载下面这个:http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.6.0.tar下载完以后,解压到hadoop的native目录下,覆盖原有文件即可。操作如下:tar -x hadoop-native-64-2.4.0.tar -C hadoop/lib/native/再将环境变量导入到系统中.修改/etc/profileexport JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
时钟不正确的问题
fatal org.apache.hadoop.hbase.regionserver.hregionserver: master rejected startup because clock is out of syncorg.apache.hadoop.hbase.clockoutofsyncexception: org.apache.hadoop.hbase.clockoutofsyncexception: server suc-pc,60020,1363269953286 has been rejected; reported time is too far out of sync with master. time difference of 39375ms > max allowed of 30000ms小问题,一看就知道错误发生在哪。在hbase中,允许小的时间偏差,但是上面39秒的时间偏差就有点大了。如果你是联网的话,可以用ntpdate 219.158.14.130进行同步。219.158.14.130是网通北京的时间服务器,如果不行你可以用别的服务器进行同步。
这里面有一段小插曲就是,我在使用的时候,由于使用了外网的时钟服务器,但是resolv.conf反复被覆盖.所以不成功.
/etc/resolv.conf中设置dns之后每次重启Ubuntu Server时该文件会被覆盖,针对这种情况找了一些个解决方法防止/etc/resolv.conf被覆盖的方法方法一1.需要创建一个文件/etc/resolvconf/resolv.conf.d/tailsudo vi /etc/resolvconf/resolv.conf.d/tail2.在该文件中写入自己需要的dns服务器,格式与/etc/resolv.conf相同nameserver 8.8.8.83.重启下resolvconf程序sudo /etc/init.d/resolvconf restart再去看看/etc/resolv.conf文件,可以看到自己添加的dns服务器已经加到该文件中方法二在/etc/network/interfaces中###interfaces中#######auto eth0iface eth0 inet staticaddress 192.168.3.250netmask 255.255.255.0 #子网掩码gateway 192.168.3.1 #网关dns-nameservers 8.8.8.8 8.8.4.4 #设置dns服务器
zookeeper服务器未设置或者/etc/hosts设置有误(hbase)
2013-03-11 19:41:08,263 info org.apache.zookeeper.clientcnxn: opening socket connection to server localhost/127.0.0.1:2181. will not attempt to authenticate using sasl (unknown error)2013-03-11 19:41:08,266 warn org.apache.zookeeper.clientcnxn: session 0x0 for server null, unexpected error, closing socket connection and attempting reconnectjava.net.connectexception: 拒绝连接at sun.nio.ch.socketchannelimpl.checkconnect(native method)at sun.nio.ch.socketchannelimpl.finishconnect(socketchannelimpl.java:692)at org.apache.zookeeper.clientcnxnsocketnio.dotransport(clientcnxnsocketnio.java:350)at org.apache.zookeeper.clientcnxn$sendthread.run(clientcnxn.java:1068)这个问题的出现,会伴随一个非常奇怪的现象。在master所在的pc上启动start-all时,内容提示所有的regionserver已经全部启动。但是,如果你去查看masterip:60010时会发现其他的regionserver并没有启动,regionserver的数量只有一台。因为已经有一台regionserver是活着的,所以hbase还是能继续使用的,这此文来自: 马开东博客 转载请注明出处 网址: http://www.makaidong.com会迷惑你。查看别的机器的日志后,你就会发现上述错误。zookeeper的定位居然定位到127.0.0.1去了,这个不科学。最后,查阅资料才发现hbase.zookeeper.quorum这个属性设置时,默认本机即为zookeeper服务器(单机使用)。这就很简单了,只需要增加这个属性就可以了。<property><name>hbase.zookeeper.quorum</name><value>10.82.58.213</value></property>同时,也发现如果/etc/hosts设置错误也会发生类似问题。/etc/hosts中,localhost和本机pc名都需要为127.0.0.1,因为本机pc名默认是127.0.1.1。参考:http://mail-archives.apache.org/mod_mbox/hbase-user/201106.mbox/%3cbanlktimcghr-1mdtdo3netzmrqxkbjy=da@mail.gmail.com%3e