《分布式》专题
-
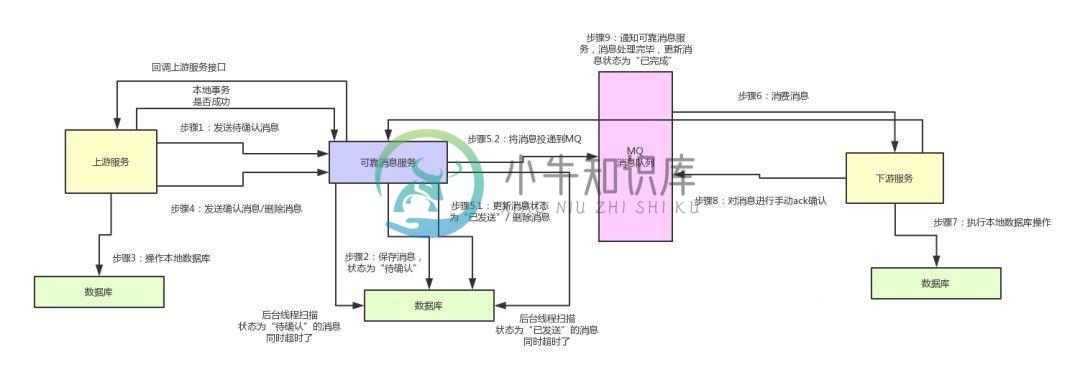 阿里面试问题:分布式事务如何实现高可用?
阿里面试问题:分布式事务如何实现高可用?主要内容:一、写在前面,二、可靠消息最终一致性方案的核心流程,三、可靠消息最终一致性方案的高可用保障生产实践一、写在前面 上一篇文章咱们聊了聊TCC分布式事务,对于常见的微服务系统,大部分接口调用是同步的,也就是一个服务直接调用另外一个服务的接口。 这个时候,用TCC分布式事务方案来保证各个接口的调用,要么一起成功,要么一起回滚,是比较合适的。 但是在实际系统的开发过程中,可能服务间的调用是异步的。 也就是说,一个服务发送一个消息给MQ,即消息中间件,比如RocketMQ、RabbitMQ、Ka
-
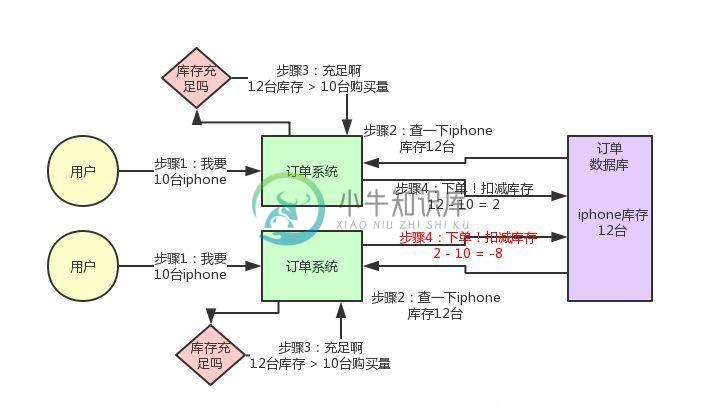 一个基于分布式锁的库存高并发超卖问题
一个基于分布式锁的库存高并发超卖问题主要内容:背景引入,库存超卖现象是怎么产生的?,用分布式锁如何解决库存超卖问题?,有没有其他方案可以解决库存超卖问题?,分布式锁的方案在高并发场景下,如何对分布式锁进行高并发优化?,分布式锁并发优化方案有没有什么不足?,该优化方案的后续改进今天给大家聊一个有意思的话题:每秒上千订单场景下,如何对分布式锁的并发能力进行优化? 背景引入 首先,我们一起来看看这个问题的背景? 前段时间有个朋友在外面面试,然后有一天找我聊说:有一个国内不错的电商公司,面试官给他出了一个场景题: 假如下单时,用分布式锁来
-
分布式系统接口,如何避免表单的重复提交?
幂等性 效果:系统对某接口的多次请求,都应该返回同样的结果!(网络访问失败的场景除外) 目的:避免因为各种原因,重复请求导致的业务重复处理 重复请求场景案例: 1,客户端第一次请求后,网络异常导致收到请求执行逻辑但是没有返回给客户端,客户端的重新发起请求 2,客户端迅速点击按钮提交,导致同一逻辑被多次发送到服务器 简单来划分,业务逻辑无非都可以归纳为增删改查! 对于查询,内部不包含其他操作,属于只
-
生成概率分布范围内的随机整数
问题内容: 我有一个问题,我想使用概率分布生成一组1到5之间的随机整数值。 泊松和逆伽玛是两个分布,它们显示了我所追求的特征(多数情况下为平均值,较少的较高数)。 我正在使用Apache Commons Math,但不确定如何使用可用的分布来生成所需的数字。 问题答案: 从问题描述中,听起来好像您实际上想要从离散的概率分布中生成样本,并且您可以将其用于此目的。为每个整数选择适当的概率,也许类似以下
-
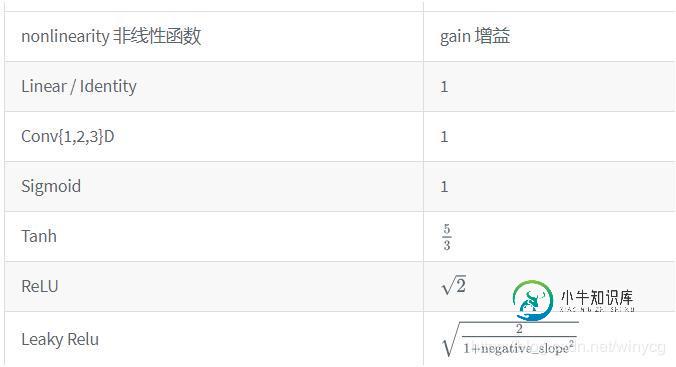 对Pytorch神经网络初始化kaiming分布详解
对Pytorch神经网络初始化kaiming分布详解本文向大家介绍对Pytorch神经网络初始化kaiming分布详解,包括了对Pytorch神经网络初始化kaiming分布详解的使用技巧和注意事项,需要的朋友参考一下 函数的增益值 提供了对非线性函数增益值的计算。 增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系。 xavier分布 xavier分布解析:https://prateekvjoshi.com/2016/03/29/
-
如何在MockMVC中发布多部分/表单数据?
我已经创建了一个使用“多部分/表单数据”的控制器 采样器请求对象 现在,我将尝试使用模拟MVC测试它,但我不知道如何将“多部分/表单数据”作为内容传递。我看到很多使用JSON的示例,但没有使用多部分/表单数据 有没有一种方法可以完成我的请求与多部分/form_data?理想情况下,它需要在MockHttpServletRequest的主体中
-
获取MySQL中十进制范围的频率分布
问题内容: 我正在寻找一种优雅的方法(就语法而言,不一定有效)来获取小数范围的频率分布。 例如,我有一个带有“评分”列的表,该列可以是负数也可以是正数。我想获得具有一定范围等级的行的频率。-…-[-140.00至-130.00):5-[-130.00至-120.00):2-[-120.00至-110.00):1-…-[120.00至130.00):17-依此类推。 [i到j]表示i包含到j排除。
-
StackExchange.Redis 根据发布线程对命令进行分组
本文向大家介绍StackExchange.Redis 根据发布线程对命令进行分组,包括了StackExchange.Redis 根据发布线程对命令进行分组的使用技巧和注意事项,需要的朋友参考一下 示例 perThreadTimings 最终以1,000个IProfilingCommands的16个条目结束,由发出它们的线程键入。
-
Spring集成-拆分后发布订阅通道聚合
我有一个基于DSL的流,它使用拆分迭代对象列表并发送Kafka消息: 在所有消息发出后,我需要调用服务,还需要记录处理了多少消息。我知道一种方法是使用publishSubscribeChannel,其中第一个subscribe执行实际的Kafka发送,然后聚合执行服务调用: 我在弄清楚如何使用DSL在pubSubChannel中实际执行部分时遇到了问题。到目前为止,我已经尝试过: 有什么指示吗?
-
如何使用WHERE id IN(1,2,3,4)获得均匀分布
问题内容: 我有一个查询,该查询从表中拉出喜欢特定对象的用户。等级存储在表格中。到目前为止,我提出的查询看起来像这样: 当每个ID仅需要3个左右的结果时,我希望能够在此查询上放一个,以避免返回所有结果。例如,如果我仅放置一个,则可能会获得8个记录,每个记录具有一个ID,其他ID分别为1或2个记录-即ID分布不均。 有没有一种写此查询的方法来保证(假设一个对象被“点赞”了至少3次),对于列表中的每个
-
基于JavaScript伪随机正态分布代码实例
本文向大家介绍基于JavaScript伪随机正态分布代码实例,包括了基于JavaScript伪随机正态分布代码实例的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了基于JavaScript伪随机正态分布代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在游戏开发中经常遇到随机奖励的情况,一般会采取先生成数组,再一个一个取的方式发随
-
节点v0之间的差异。12和v5。x分布
我希望通过Dockerfile将nodejs安装到基于debian的容器中。我对那里的不同发行版有点困惑。我已经得出结论,我想要最新的稳定发行版。 现在,在nodesource/distributions#deb中有四种不同的发行版(v0.10、v0.12、v4.x、v5.x)。据我所知,我需要v5。x(通过阅读这篇博文,以及我在谷歌上搜索到的其他随机信息)。但无论我在哪里寻找,人们都建议安装v0
-
 Python中给定范围之间值的指数分布
Python中给定范围之间值的指数分布我有三个变量Min=0.29、Max=6.52和center=2.10。我希望创建一个表,以以下方式将这些数据以表格式分配为100个值: 这里,这个图像可以分成0到50和50到100两部分。 在第一部分中,后续值的x与y的增加在1-10与10-20之间较高,在10-20与20-30之间较高,以此类推。 在第二部分中,随后值的x与y的增加在50-60比60-70之间较低,在60-70比70-80之间
-
顶点在 Vert.x 节点群集上的公平分布
我一直在试验Vert. x的高可用性功能来测试水平可扩展性和弹性。我有一个基于Hazelcast的几个节点的集群。我正在通过HTTP应用编程接口在任何节点上创建顶点。Verticle在创建时设置了标志。 如果我有< code>n个节点< code>Nn加载了HA-verticles,并且如果我添加了一个额外的节点,则没有从新节点上的< code>Nn节点迁移的vertices,因此负载将会平衡。有
-
生成R中某一极限内的正态分布
我想生成一个均值为120,标准差为20的正态分布。但是我需要将这些值限制在[0,150]。我该怎么办?