《分布式》专题
-
Spring中使用atomikos+druid实现经典分布式事务的方法
本文向大家介绍Spring中使用atomikos+druid实现经典分布式事务的方法,包括了Spring中使用atomikos+druid实现经典分布式事务的方法的使用技巧和注意事项,需要的朋友参考一下 经典分布式事务,是相对互联网中的柔性分布式事务而言,其特性为ACID原则,包括原子性(Atomictiy)、一致性(Consistency)、隔离性(Isolation)、持久性(Durabili
-
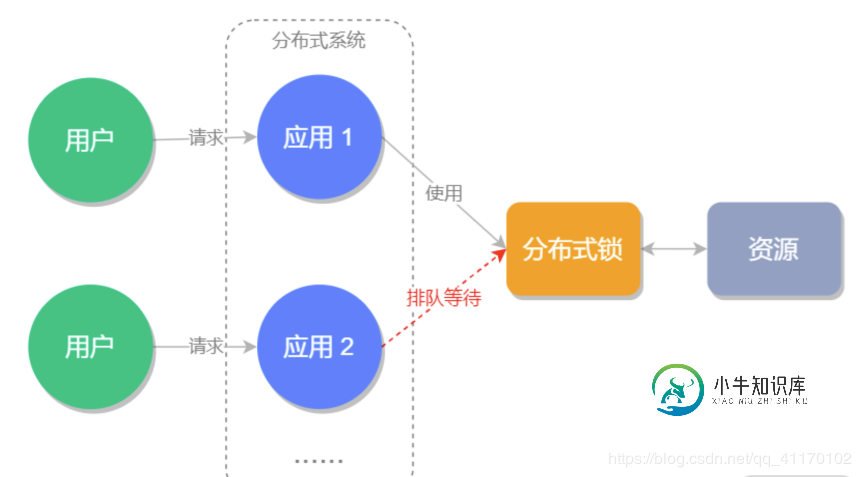 SpringBoot整合Redis正确的实现分布式锁的示例代码
SpringBoot整合Redis正确的实现分布式锁的示例代码本文向大家介绍SpringBoot整合Redis正确的实现分布式锁的示例代码,包括了SpringBoot整合Redis正确的实现分布式锁的示例代码的使用技巧和注意事项,需要的朋友参考一下 前言 最近在做分块上传的业务,使用到了Redis来维护上传过程中的分块编号。 每上传完成一个分块就获取一下文件的分块集合,加入新上传的编号,手动接口测试下是没有问题的,前端通过并发上传调用就出现问题了,并发的ge
-
运行 kafka 连接分布式模式时已在使用的地址
我按问题推出了合流套件”。/bin/合流启动”命令。然后我用kafka connect把kafka的数据汇到mysql。 我可以通过执行以下命令在独立模式下很好地运行 kafka 连接: ./bin/connect-standalone ./etc/schema-registry/connect-avro-standalone.properties ./etc/kafka-connect-jdbc
-
2.3.7 分布式服务接口请求的顺序性如何保证?
面试题 分布式服务接口请求的顺序性如何保证? 面试官心理分析 其实分布式系统接口的调用顺序,也是个问题,一般来说是不用保证顺序的。但是有时候可能确实是需要严格的顺序保证。给大家举个例子,你服务 A 调用服务 B,先插入再删除。好,结果俩请求过去了,落在不同机器上,可能插入请求因为某些原因执行慢了一些,导致删除请求先执行了,此时因为没数据所以啥效果也没有;结果这个时候插入请求过来了,好,数据插入进去
-
详解spring cloud config整合gitlab搭建分布式的配置中心
本文向大家介绍详解spring cloud config整合gitlab搭建分布式的配置中心,包括了详解spring cloud config整合gitlab搭建分布式的配置中心的使用技巧和注意事项,需要的朋友参考一下 在前面的博客中,我们都是将配置文件放在各自的服务中,但是这样做有一个缺点,一旦配置修改了,那么我们就必须停机,然后修改配置文件后再进行上线,服务少的话,这样做还无可厚非,但是如果是
-
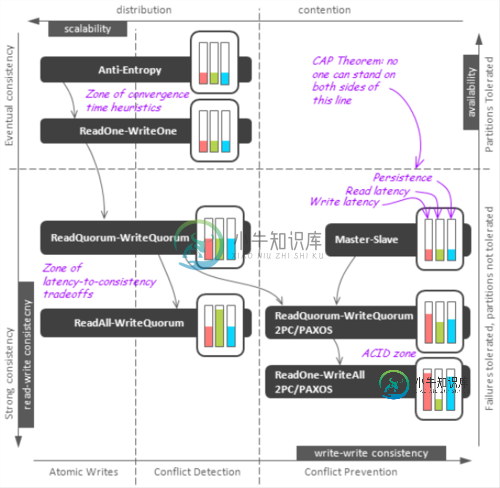 深入解析NoSQL数据库的分布式算法(图文详解)
深入解析NoSQL数据库的分布式算法(图文详解)本文向大家介绍深入解析NoSQL数据库的分布式算法(图文详解),包括了深入解析NoSQL数据库的分布式算法(图文详解)的使用技巧和注意事项,需要的朋友参考一下 尽管NoSQL运动并没有给分布式数据处理带来根本性的技术变革,但是依然引发了铺天盖地的关于各种协议和算法的研究以及实践。在这篇文章里,我将针对NoSQL数据库的分布式特点进行一些系统化的描述。 系统的可扩展性是推动NoSQL运动发展的的主要
-
用Hazelcast将单个节点转换为分布式java应用程序
基本上我们有2: 我们有2个,以便根据组的ID轻松地查询组,并知道哪些组属于我们的成员。 但是,根据文档,使用,应该可以只创建一个映射: null
-
在分布式JMeter测试中写入以变量命名的文件
好的,我一直在将结果写入JMeter中的文件夹时遇到问题。 我已经设置了两个变量,一个用于测试的名称,一个用于提交日期。我希望将报告写到用这两个变量命名的文件夹中。 这是变量: 要写入的文件夹的路径如下所示: 当我在主计算机上运行它时,它很好。它会保存到正确的文件和文件夹路径,最终显示如下: 然而,当我在远程机器上运行它时,它会按如下方式保存它: 所以我最终得到了一个名为“${TestRun}${
-
Spring-Data-Redis带有Jedis PutifAstant用于分布式锁-不正确行为
我在使用Spring Data Redis创建分布式锁时遇到了一些问题。为此,使用CacheManager中的putifAstant方法。 从高层的角度来看,操作如下所示: Spring实现的代码类似于: 连接的setNX只是对实际客户端操作的委派。关于该方法的实现,有如下内容: 我达到了一种情况,钥匙仍然没有过期。这意味着代码processKeyExpiration(element,connec
-
使用terracotta设置hibernate分布式ehcache时的会话工厂问题
我正在尝试使用Terracotta在分布式环境中设置EHCache。在这里,我能够连接应用程序服务器和兵马俑服务器,在兵马俑开发人员控制台中,我能够看到复制的对象。 但是在应用程序服务器中不断出现以下异常消息,尽管应用程序的其余部分运行正常: 大家好,如果有人能指导一下为什么会出现这个异常消息,以及我们该如何解决它。此外,它将有助于我有任何全面的教程,为hibernate应用程序设置terraco
-
使用分布式terracotta ehcache运行spring boot代码时出现异常
我已经创建了一个使用分布式ehcache的spring boot项目。我下载并运行terracotta服务器,配置在tc-config.xml中。服务器在本地主机9510上成功运行。以下是我的ehcache。xml,它位于spring boot项目的类路径中 以下是我的maven依赖。 下面是我尝试创建缓存管理器的代码,以便在我的应用程序中使用它 但我得到的例外如下 任何帮助都将不胜感激
-
 关于大规模分布式系统的容错架构的设计
关于大规模分布式系统的容错架构的设计主要内容:1、TB级数据放在一台机器上:难啊!,2、到底啥是分布式存储?,3、啥又是分布式存储系统?,4、某台机器宕机了咋办?,5、Master节点如何感知到数据副本消失?,6、复制副本保持足够副本数量,7、删除多余副本,8、全文总结这篇文章,我们将用非常浅显易懂的语言,跟大家聊聊大规模分布式系统的容错架构设计。 虽然定位是有“分布式”、“容错架构”等看起来略显复杂的字眼,但是咱们还是按照老规矩:大白话 + 手绘数张彩图,逐步递进,让每个同学都能看懂这种复杂架构的设计思想。 1、TB级数据放在一
-
第三章 Hadoop是什么 - 第三章 Hadoop的伪分布式搭建
一 JDK的安装 下载JDK安装包,建议去Oracle官方下载,地址自行百度 下载Hadoop2.6的安装包,建议官方下载,地址自行百度 如果是在Windows端进行终端操作,建议使用XFTP与XShell,有Free版本 之后用XFTP将JDK安装包与Hadoop安装包上传到实验主机上 将Java SDK解压,并将解压文件复制到/usr/lib/jvm中 配置环境变量 如果系统中已经有默认的Op
-
1.5 个人计算、分布式计算与客户/服务器计算
1977年,Apple 计算机公司使个人计算(personal computer)得以普及。最初拥有一台计算机只是爱好者的梦想,随着它的价格不断降低,人们可以购买供个人或办公使用的计算机。1981年,世界上最大的计算机广家IBM公司推出了IBM个人计算机(IBM Personal computer)。一夜之间,个人计算机遍布公司、企业和政府机关。 然而这些计算机只是“独立”的个体,各自做自己的工作
-
分布式事务如何实现?深入解读 Seata 的 XA 模式
Seata 1.2.0 版本重磅发布新的事务模式:XA 模式,实现对 XA 协议的支持。 这里,我们从三个方面来深入解读这个新的特性: 是什么(What):XA 模式是什么? 为什么(Why):为什么支持 XA? 怎么做(How):XA 模式是如何实现的,以及怎样使用? 1. XA 模式是什么? 这里有两个基本的前置概念: 什么是 XA? 什么是 Seata 定义的所谓 事务模式? 基于这两点,再