《数据分析科学实习》专题
-
 2023.2数据分析/挖掘日常实习面经汇总
2023.2数据分析/挖掘日常实习面经汇总众安保险-数据分析实习生 30min 个人介绍完了后直接写sql(给20min),未问简历。两道sql题在word写出完整代码,第二题太紧张有个地方理解错了,给面试官看了后还好及时发现,又给我五分钟重写hhh 反问:实习生做什么,主要是写sql满足业务方的需求。 喜马拉雅-数据分析实习生 30min 1、个人介绍。 2、问之前实习公司(初创小公司)是做什么的。对实习项目的成果(数据分析为用电安全提
-
 快手-电商-数据分析师-日常实习(凉经)
快手-电商-数据分析师-日常实习(凉经)复盘一下面试经历,总体来说回答地磕磕绊绊,面试官很耐心一直在引导回答。 但是我的水平不够,缺少深入思考,回答的点很散不成体系,逻辑性也不强。 有些题面试官点出了关键,对比自己的回答,明显感受到思维层次差距。 把面试题和自己的回答都放上来,给自己攒点人品,也希望大佬们指教~ 1,自我介绍(主要介绍了一段互联网电商运营实习) 2,在实习经历中有没有对某个指标进行分析,有无相关case经历? 答:没有(
-
 中金所暑期实习(数据分析)笔试内容
中金所暑期实习(数据分析)笔试内容综合能力测试: 1、言语理解与表达(10题) 2、判断推理(20题) 3、数字关系(10题) 4、资料分析(5题) 5、常识判断(10题) 专业测试: 1、单选题(20题) 2、不定选项题(8题) 3、简答题(2题) 4、算法题(2题)
-
 字节跳动-数据分析实习生-客服平台
字节跳动-数据分析实习生-客服平台一面(约50分钟) 1、自我介绍 2、详细说明工作经历做了什么,有什么成果即工作业绩 3、SQL用的最多的函数有哪些 4、窗口函数rank()、dense_rank()、row_number()的区别 4、两道SQL口述题目 一个表三列分别是:id,顾客的问题,对问题的回答 a)获得顾客问的最多的10个问题 b)获得每个顾客问的最多的10个问题 5、讲述ABtest的过程 6、怎么分析ABtest
-
 vivo数据分析实习面经以及入职攻略
vivo数据分析实习面经以及入职攻略不知不觉已经来到vivo一个多月,现分享下面经及入职攻略 lz坐标南京vivo大厦,岗位是数据分析实习生 首先介绍下timeline:4.18(boss上投递)-4.19约面(此时boss上已经关闭岗位)-4.23(一面)-4.25(hr面)-4.28(offer) 面经干货: 一面:有两位面试官,其中一位是当时boss上的对接人,后续入职知道,这位是数据团队负责人,另外一位是mentor。整个面
-
 百度数据分析面试1|日常实习两面
百度数据分析面试1|日常实习两面百度贴吧业务部数据分析日常实习两面 一面 1. 自我介绍。 2. 说一下SELECT FROM WHERE GROUP BY HAVING ORDER BY的执行顺序。 3. 说一下SQL和Hive SQL的不同。 4. 平常用SQL还是Hive SQL? 5. SQL题:①用户id,月份,销售额。计算每个月的用户数;截至当月的用户数;截至当月的销售额。②学生id,科目(语文、数学),成绩。计算语
-
 已offer|携程大数据分析工程暑期实习
已offer|携程大数据分析工程暑期实习▫️Timeline:3.13投递 - 3.15完成综合考试 - 3.27请求转到第二志愿 - 4.11一面 - 4.21二面 - 4.25HR面+英语测评 - 4.26收offer ▫️bg:美本专业对口,一段相关实习,两个项目(1机器学习,1rfm) ▫️一面(~45mins) - 职业学业规划 - 回国时间&到岗时间&实习时长 - 自我介绍 - 介绍实习内容 - 实习怎么搭建指标体系 - 实
-
PHP数据对象映射模式实例分析
本文向大家介绍PHP数据对象映射模式实例分析,包括了PHP数据对象映射模式实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP数据对象映射模式。分享给大家供大家参考,具体如下: 将对象和数据存储映射起来,对一个对象的操作映射为对数据存储的操作。 例如在代码中new 一个对象,使用数组对象映射模式可以将对象的一些操作,比如设置一些属性,就会自动保存到数据库,跟数据库表的一条记录对应
-
 腾讯游戏数据科学后端开发暑假实习二面凉经(C++)
腾讯游戏数据科学后端开发暑假实习二面凉经(C++)上来直接自我介绍,摁怼项目,面试官问的比较细,也有点凶,类似于说“你做这个是为了提高性能还是为了项目而项目”。 时间:30min,真的就是腾讯会议写着30min就是30min,全程无算法无八股。
-
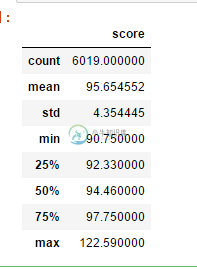 Python实现的北京积分落户数据分析示例
Python实现的北京积分落户数据分析示例本文向大家介绍Python实现的北京积分落户数据分析示例,包括了Python实现的北京积分落户数据分析示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python实现的北京积分落户数据分析。分享给大家供大家参考,具体如下: 北京积分落户状况 获取数据(爬虫/文件下载)—> 分析 (维度—指标) 从公司维度分析不同公司对落户人数指标的影响 , 即什么公司落户人数最多也更容易落户 从年龄维
-
看数据科学家是如何找回丢失的数据的(二)
连续型变量是如何做数据填补的 上一节中讲的Embarked的填补是一种离散型变量的填补方式,也就是通过统计规律来预测。那么对于连续型变量如果使用这种方法就不合适了,而应该使用某一种插值方式。比如Age这种数据,根据统计规律,假设其他人年龄多数是50岁,其他人都小于50岁,那么就预测是50岁吗?显然不对,而应该是小于50的某个值。那么如何根据统计规律来计算插值呢?我们来介绍一下mice mice就是
-
看数据科学家是如何找回丢失的数据的(一)
补全数据的纯手工方案 我们以泰坦尼克号数据集为例(不了解这个数据集请见《十八-R语言特征工程实战》)。 先重温一下这个数据集里面都有哪些字段: PassengerId,Survived,Pclass,Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked 分别表示: 样本编号、是否得救、乘客级别、姓名、性别、年龄、船上的兄弟姐妹数、船上的父母子女数、
-
 网易数据分析面经
网易数据分析面经回馈牛客~面的是传媒技术部的数据分析,对接的是网易新闻 一面35分钟 1.简历深挖。挖得太细了,很多角度都是从未设想过的,不得不说业务做的多的人看细节真的很独到 2.机器学习相关。随机森林、逻辑回归原理,如何做特征筛选,评价指标 3.口述三道SQL 4.一道python数据清洗的题目,屏幕共享直接写 5.反问,介绍业务,然后给我提了点二面的建议 二面 主管面20分钟 1.AB实验样本不平衡怎么办
-
 快手-数据分析-一面
快手-数据分析-一面一面 总评:感觉有点奇怪,也没有问我数理统计相关的内容,也没有让我写sql,难道是因为我最后一份实习是做的数据产品,所以就不怎么问我?但是整体下来问的问题都比较常规,面试官态度也很nice 细分题: 简历深耕 介绍下之前做的数据化产品,以及如何使用数据化产品帮助业务的? 介绍下自动化归因的功能和算法(简历有) 数据化产品主要的服务对象是谁?你认为他们主要关注的什么信息? 你在产品优化过程中起到了什
-
 京东 数据分析 笔试
京东 数据分析 笔试有人知道京东数据分析笔试考啥吗,我看邮件里说无编程题,难不成考数据库? 更新一下: 笔试是50道行测,整体比较简单,当然不知道是不是因为我复习过行测的原因 5道资料分析非常简单的 大约10道的数字推理题,比如1 2 5 10 17 下一个数字是啥,有几个是比较难的 再就是言语理解和图形题 #京东笔试#