《数据分析师面经》专题
-
 shopee数分面经
shopee数分面经无笔试 一面面试内容: 1.自我介绍 2.介绍上一段实习的项目 3.追问首页转化的计算方式 4.怎么判断用户是误触到结果页的 5.设计一个实验,在页面某个模块做直播标签的设置,点这个词搜完后出直播,问怎么设计方案,需要观察哪些指标,怎么评估实验效果,评估效果多大 6.excel、sql、python、bi掌握程度在1-10打分 7.sql计算次留率 8.可实习时长,是日常实习,问对转正有
-
SQLite教程(五):索引和数据分析/清理
本文向大家介绍SQLite教程(五):索引和数据分析/清理,包括了SQLite教程(五):索引和数据分析/清理的使用技巧和注意事项,需要的朋友参考一下 一、创建索引: 在SQLite中,创建索引的SQL语法和其他大多数关系型数据库基本相同,因为这里也仅仅是给出示例用法: 从.indices命令的输出可以看出,三个索引均已成功创建。 二、删除索引: 索引的删除和视
-
Python操作Access数据库基本步骤分析
本文向大家介绍Python操作Access数据库基本步骤分析,包括了Python操作Access数据库基本步骤分析的使用技巧和注意事项,需要的朋友参考一下 本文实例分析了Python操作Access数据库基本步骤。分享给大家供大家参考,具体如下: Python编程语言的出现,带给开发人员非常大的好处。我们可以利用这样一款功能强大的面向对象开源语言来轻松的实现许多特定功能需求。比如Python操作A
-
MongoDB数据库的日志文件深入分析
本文向大家介绍MongoDB数据库的日志文件深入分析,包括了MongoDB数据库的日志文件深入分析的使用技巧和注意事项,需要的朋友参考一下 前言 日志是MongoDB中一个非常重要的功能,他保证了数据库服务器在意外断电、自然灾害下数据的完整性 。MongoDB日志记录了数据库实例的健康状态、语句的执行状况、资源的消耗情况,所以日志对于分析数据库服务和性能优化很有帮助。 因此,很有必要花费一些时间来
-
 Python数据分析库pandas基本操作方法
Python数据分析库pandas基本操作方法本文向大家介绍Python数据分析库pandas基本操作方法,包括了Python数据分析库pandas基本操作方法的使用技巧和注意事项,需要的朋友参考一下 pandas是什么? 是它吗? 。。。。很显然pandas没有这个家伙那么可爱。。。。 我们来看看pandas的官网是怎么来定义自己的: pandas is an open source, easy-to-use data structures
-
 Python运用于数据分析的简单教程
Python运用于数据分析的简单教程本文向大家介绍Python运用于数据分析的简单教程,包括了Python运用于数据分析的简单教程的使用技巧和注意事项,需要的朋友参考一下 最近,Analysis with Programming加入了Planet Python。作为该网站的首批特约博客,我这里来分享一下如何通过Python来开始数据分析。具体内容如下: 数据导入 导入本地的或者web端的CSV文件;
-
PHP数据对象映射模式实例分析
本文向大家介绍PHP数据对象映射模式实例分析,包括了PHP数据对象映射模式实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP数据对象映射模式。分享给大家供大家参考,具体如下: 将对象和数据存储映射起来,对一个对象的操作映射为对数据存储的操作。 例如在代码中new 一个对象,使用数组对象映射模式可以将对象的一些操作,比如设置一些属性,就会自动保存到数据库,跟数据库表的一条记录对应
-
SQL数据库中的维度和单位分析
问题内容: 问题: 关系数据库(Postgres),用于存储各种测量值的时间序列数据。每个测量值可以具有特定的“测量类型”(例如,温度,溶解氧等),并且可以具有特定的“测量单位”(例如,华氏/摄氏度/开尔文,百分数/毫克/升等)。 问题: 有没有人建立过类似的数据库以保持尺寸完整性? 有什么建议吗? 我正在考虑建立一个measurement_type和一个measurement_unit表,这两个
-
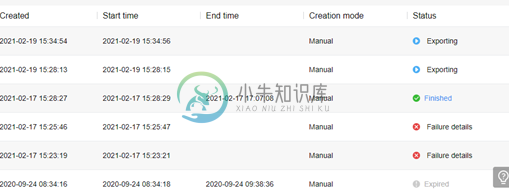 华为分析控制台导出数据失败
华为分析控制台导出数据失败试图在以下日期导出数据,但我错误地说“失败详细信息”。为什么这个导出数据会失败?我们对数据导出有限制吗?
-
如何利用Cytoscape分析“一对多”数据值
我对使用Cytoscape分析基因之间的分子关系很感兴趣,我一直在阅读Cytoscape网站上的教程,但不确定如何使用Cytoscape进行“一对多”比较。 例如,每个基因通常被指定为一个“节点”,具有与其他基因相互作用对应的“边缘”。Cytoscape使用“属性”将节点或边缘名称映射到特定的数据值。在一个简单的“一对一”比较中,你可能有一个10个基因及其表达值的列表,这样每个基因的属性将是1)基
-
 西山居数据分析实习笔试(自用)
西山居数据分析实习笔试(自用)excel题:不让用中间表,只能用计算公式 用到了VLOOKUP(),index(match()),sumproduct,countif(),sumif(),if(),rank()函数 SQL题: 为给流失玩家(手机号下所有账号近30天都没有登录)发送召唤短信,现需要计算每个手机号下的付费总金额,且按每个手机号付费金额从高到低进行排序 特定行为匹配,找出用bug的玩家(用不上开窗,join就行)
-
 建信金科4.20数据分析建模笔试
建信金科4.20数据分析建模笔试20道选择题一共60分,我怎么觉得第一题4个答案都不正确? 算法题20分,核心代码模式不用自己操心输入: 有一个长度为n的数组,从中找到这样一个序列:1.子序列的第一项任意;2.子序列的后一项比前一项大1。要求返回满足上述条件的最大的子序列的元素和。 范例1:输入[1,3,2,4,3],输出7 范例2:输入[4,6,2,5,3,4],输出9 其实挺简单的题,用动态规划做超时了,只过了80% SQL
-
数据分区
Redisson 仅在集群模式中支持数据分区(分片)。 它使得可以使用整个 Redis 集群的内存而不是单个节点的内存来存储单个数据结构实例。 Redisson 默认将数据结构切分为 231 个槽。槽的数量可在 3 和 16834 之间。槽会一致地分布在所有的集群节点上。这意味着每个节点将包含近似相等数量的槽。如默认槽量(231) 和 4 个节点的情况,每个节点将包含接近 57 个数据分区,而对
-
分组数据
用GROUP BY 跟 HAVING子句,分组数据来汇总表内容子集。 创建分组 分组在SELECT语句的GROUP BY子句中建立。 mysql> SELECT vend_id, COUNT(*) AS num_prods -> FROM Products -> GROUP BY vend_id; +---------+-----------+ | vend_id | num_pr
-
数据分页
$Wxch_indent = M("Wxch_indent"); // 实例化Wxch_indent对象 $count = $Wxch_indent->where($where)->count();// 查询满足要求的总记录数 $Page = $this->Page($count,25);// 实例化分页类 传入总记录数和每页显示的记录数(25) $show = $Page->sho