
Python熊猫重塑数据帧

这似乎是非常基本的知识,但我还是卡住了,尽管我有一些数据处理的理论背景(通过其他软件)。值得一提的是,我是蟒蛇和熊猫图书馆的新手。
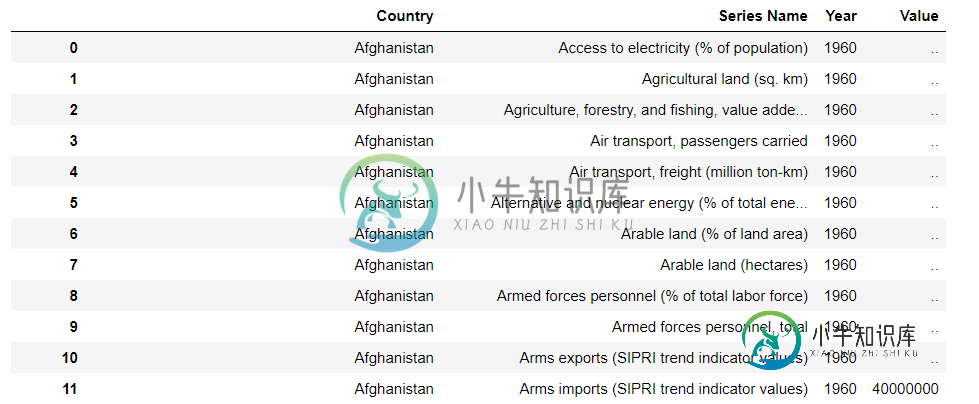
我的任务是将系列名称列的值作为单独的列(从长到宽转换)。我花了很长时间尝试不同的方法,但只有错误。
例如:
mydata = mydata.pivot(index=['Country', 'Year'], columns='Series Name', values='Value')
我犯了一个错误:
...很多短信...通过值的长度是2487175,索引暗示2
有谁能指导我完成这个过程吗?谢谢
它用于代码“mydata=mydata”。pivot(索引=['Country','Year',columns='Series Name',values='Value')”错误消息:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-4-8169d6d374c7> in <module>
----> 1 mydata = mydata.pivot(index=['Country', 'Year'], columns='Series Name', values='Value')
~/anaconda3_501/lib/python3.6/site-packages/pandas/core/frame.py in pivot(self, index, columns, values)
5192 """
5193 from pandas.core.reshape.reshape import pivot
-> 5194 return pivot(self, index=index, columns=columns, values=values)
5195
5196 _shared_docs['pivot_table'] = """
~/anaconda3_501/lib/python3.6/site-packages/pandas/core/reshape/reshape.py in pivot(self, index, columns, values)
412 else:
413 indexed = self._constructor_sliced(self[values].values,
--> 414 index=index)
415 return indexed.unstack(columns)
416
~/anaconda3_501/lib/python3.6/site-packages/pandas/core/series.py in __init__(self, data, index, dtype, name, copy, fastpath)
260 'Length of passed values is {val}, '
261 'index implies {ind}'
--> 262 .format(val=len(data), ind=len(index)))
263 except TypeError:
264 pass
ValueError: Length of passed values is 2487175, index implies 2
共有2个答案

如何将“国家”和“年份”与其他列名放在同一级别,以便能够正常地将其导出到excel?如果我像现在这样出口,表中不包括“国家”和“年份”。

尝试一下:
mydata = mydata.pivot_table(index=['Country', 'Year'], columns='Series Name', values='Value', aggfunc='sum')
(如果您想求和您的Value)似乎需要以某种方式显式地聚合您的数据。虽然会很好,如果你会分享完整的错误消息。
我设法重现了你的错误。正如我所说,您需要提供聚合功能:
import pandas as pd
df=pd.DataFrame({"a": list("xyzpqr"), "b": list("abbbaa"), "c": [4,3,6,2,7,5], "d": list("pqqppp")})
df2=df.pivot(index=["b", "d"], columns="a", values="c")
#ValueError: Length of passed values is 6, index implies 2
df2=df.pivot_table(index=["b", "d"], columns="a", values="c", aggfunc=set)
#works fine - you need aggregation function e.g. list/set to collect all/unique values or e.g. sum/max to do some numeric operation
-
问题内容: 我有一个熊猫系列,目前看起来像这样: 我想从根本上将其重塑成一个看起来像这样的数据框… 即。逻辑构造,指出每个观察(行)属于哪个类别。 我能够编写基于循环的代码来解决该问题,但是鉴于我需要处理的行数众多,这将非常缓慢。 有谁知道针对这种问题的矢量化解决方案?我将不胜感激。 编辑:有509个类别,我确实有一个清单。 问题答案:
-
我有一个数据框架,目前看起来是这样的, 数据框架1 我需要创建一个像这样的数据帧。 数据框架2 我需要从数据帧1列的值填充数据帧2的列。图片显示了示例。对此应该有什么算法和过程? 这是示例数据集
-
本文向大家介绍R重塑数据,包括了R重塑数据的使用技巧和注意事项,需要的朋友参考一下 示例 数据通常在表中。通常,可以将此表格数据分为宽和长格式。在广泛的格式中,每个变量都有自己的列。 人 身高[cm] 年龄[yr] 艾莉森 178 20 鲍勃 174 45 卡尔 182 31 但是,有时使用长格式会更方便,因为所有变量都在一列中,而值在第二列中。 人 变量 值 艾莉森 身高[cm] 178 鲍勃
-
向对象似乎很难完成。有3个与此相关的stackoverflow问题,没有一个给出有效的答案。 这就是我要做的。我有一个DataFrame,我已经知道它的形状以及行和列的名称。 现在,我有了一个迭代计算行值的函数。我如何用字典或?以下是失败的各种尝试: 显然,它试图添加一列而不是一行。 非常不具信息性的错误消息。 显然,这仅用于在数据框中设置单个值。 我不想忽略索引,否则结果如下: 它确实对齐了列名
-
我有一个csv文件列表,我使用 我目前正在尝试遍历csv列表,并使用方法将axis参数设置为1,以按列将所有数据帧添加到一起。 它是工作的希望,但我遇到的问题,因为所有的数据帧都有相同的冒号名称,当我连接他们我得到例如10列都与关键"日期" 不管怎样,我能给哥伦布起个独一无二的名字吗?比如伦敦约会,柏林约会?显然,这些名称基于数据帧的名称。
-
R中的数据重塑是关于改变数据组织成行和列的方式。 大多数情况下,R中的数据处理是通过将输入数据作为数据帧来完成的。 从数据帧的行和列中提取数据很容易,但有些情况下我们需要的数据帧格式与我们收到它的格式不同。 R具有许多功能,可以在数据帧中拆分,合并和更改行到列,反之亦然。 在数据框中加入列和行 我们可以使用cbind()函数连接多个向量来创建数据框。 我们也可以使用rbind()函数合并两个数据帧