
数据预处理,分析和可视化(Data Preprocessing, Analysis & Visualization)
在现实世界中,我们经常遇到大量原始数据,这些数据不适合机器学习算法。 我们需要在将原始数据输入各种机器学习算法之前对其进行预处理。 本章讨论在Python机器学习中预处理数据的各种技术。
数据预处理
在本节中,让我们了解如何在Python中预处理数据。
最初,在文本编辑器(如记事本)中打开扩展名为.py文件,例如prefoo.py文件。
然后,将以下代码添加到此文件中 -
import numpy as np
from sklearn import preprocessing
#We imported a couple of packages. Let's create some sample data and add the line to this file:
input_data = np.array([[3, -1.5, 3, -6.4], [0, 3, -1.3, 4.1], [1, 2.3, -2.9, -4.3]])
我们现在准备对这些数据进行操作。
预处理技术
可以使用此处讨论的几种技术对数据进行预处理 -
平均删除
它涉及从每个特征中删除均值,使其以零为中心。 平均移除有助于消除特征中的任何偏差。
您可以使用以下代码进行平均删除 -
data_standardized = preprocessing.scale(input_data)
print "\nMean = ", data_standardized.mean(axis = 0)
print "Std deviation = ", data_standardized.std(axis = 0)
现在在终端上运行以下命令 -
$ python prefoo.py
您可以观察以下输出 -
Mean = [ 5.55111512e-17 -3.70074342e-17 0.00000000e+00 -1.85037171e-17]
Std deviation = [1. 1. 1. 1.]
观察到在输出中,平均值几乎为0,标准偏差为1。
Scaling
数据点中每个要素的值可以在随机值之间变化。 因此,重要的是缩放它们以使其符合指定的规则。
您可以使用以下代码进行缩放 -
data_scaler = preprocessing.MinMaxScaler(feature_range = (0, 1))
data_scaled = data_scaler.fit_transform(input_data)
print "\nMin max scaled data = ", data_scaled
现在运行代码,您可以观察以下输出 -
Min max scaled data = [ [ 1. 0. 1. 0. ]
[ 0. 1. 0.27118644 1. ]
[ 0.33333333 0.84444444 0. 0.2 ]
]
请注意,所有值都已在给定范围之间缩放。
规范化(Normalization)
标准化涉及调整特征向量中的值,以便以共同的比例测量它们。 在这里,调整特征向量的值,使它们总和为1.我们将以下行添加到prefoo.py文件中 -
您可以使用以下代码进行规范化 -
data_normalized = preprocessing.normalize(input_data, norm = 'l1')
print "\nL1 normalized data = ", data_normalized
现在运行代码,您可以观察以下输出 -
L1 normalized data = [ [ 0.21582734 -0.10791367 0.21582734 -0.46043165]
[ 0. 0.35714286 -0.1547619 0.48809524]
[ 0.0952381 0.21904762 -0.27619048 -0.40952381]
]
规范化用于确保数据点由于其特征的性质而不会得到提升。
二值化(Binarization)
二值化用于将数字特征向量转换为布尔向量。 您可以使用以下代码进行二值化 -
data_binarized = preprocessing.Binarizer(threshold=1.4).transform(input_data)
print "\nBinarized data =", data_binarized
现在运行代码,您可以观察以下输出 -
Binarized data = [[ 1. 0. 1. 0.]
[ 0. 1. 0. 1.]
[ 0. 1. 0. 0.]
]
当我们具有数据的先验知识时,该技术是有用的。
一个热编码
可能需要处理很少且分散的数值,您可能不需要存储这些值。 在这种情况下,您可以使用One Hot Encoding技术。
如果不同值的数量是k ,则它将该特征变换为k-dimensional向量,其中只有一个值是1而所有其他值都是0 。
您可以将以下代码用于一个热编码 -
encoder = preprocessing.OneHotEncoder()
encoder.fit([ [0, 2, 1, 12],
[1, 3, 5, 3],
[2, 3, 2, 12],
[1, 2, 4, 3]
])
encoded_vector = encoder.transform([[2, 3, 5, 3]]).toarray()
print "\nEncoded vector =", encoded_vector
现在运行代码,您可以观察以下输出 -
Encoded vector = [[ 0. 0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
在上面的示例中,让我们考虑每个特征向量中的第三个特征。 值为1,5,2和4。
这里有四个单独的值,这意味着单热编码向量的长度为4.如果我们要编码值5,它将是向量[0,1,0,0]。 此向量中只有一个值可以是1。 第二个元素是1,表示该值为5。
标签编码
在有监督的学习中,我们主要遇到各种各样的标签,可以是数字或单词的形式。 如果它们是数字,则它们可以由算法直接使用。 但是,很多时候,标签需要是可读的形式。 因此,训练数据通常用单词标记。
标签编码是指将单词标签更改为数字,以便算法可以理解如何处理它们。 让我们详细了解如何执行标签编码 -
创建一个新的Python文件,并导入预处理包 -
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
input_classes = ['suzuki', 'ford', 'suzuki', 'toyota', 'ford', 'bmw']
label_encoder.fit(input_classes)
print "\nClass mapping:"
for i, item in enumerate(label_encoder.classes_):
print item, '-->', i
现在运行代码,您可以观察以下输出 -
Class mapping:
bmw --> 0
ford --> 1
suzuki --> 2
toyota --> 3
如上面的输出所示,单词已被改为0索引号。 现在,当我们处理一组标签时,我们可以将它们转换如下 -
labels = ['toyota', 'ford', 'suzuki']
encoded_labels = label_encoder.transform(labels)
print "\nLabels =", labels
print "Encoded labels =", list(encoded_labels)
现在运行代码,您可以观察以下输出 -
Labels = ['toyota', 'ford', 'suzuki']
Encoded labels = [3, 1, 2]
这比手动维护单词和数字之间的映射更有效。 您可以通过将数字转换回字标签来检查,如下面的代码所示 -
encoded_labels = [3, 2, 0, 2, 1]
decoded_labels = label_encoder.inverse_transform(encoded_labels)
print "\nEncoded labels =", encoded_labels
print "Decoded labels =", list(decoded_labels)
现在运行代码,您可以观察以下输出 -
Encoded labels = [3, 2, 0, 2, 1]
Decoded labels = ['toyota', 'suzuki', 'bmw', 'suzuki', 'ford']
从输出中,您可以观察到映射得到了完美保留。
数据分析
本节详细讨论Python机器学习中的数据分析 -
加载数据集
我们可以直接从UCI机器学习库加载数据。 请注意,我们在这里使用pandas来加载数据。 我们还将使用pandas来探索数据,包括描述性统计和数据可视化。 请注意以下代码,并注意我们在加载数据时指定每列的名称。
import pandas
data = ‘pima_indians.csv’
names = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', ‘Outcome’]
dataset = pandas.read_csv(data, names = names)
运行代码时,您可以观察到数据集已加载并准备好进行分析。 在这里,我们下载了pima_indians.csv文件并将其移动到我们的工作目录中,并使用本地文件名加载它。
总结数据集
总结数据可以通过以下方式完成,具体如下 -
- 检查数据集的尺寸
- 列出整个数据
- 查看所有属性的统计摘要
- 由类变量细分数据
数据集的维度
您可以使用以下命令检查数据包含shape属性的实例(行)和属性(列)的数量。
print(dataset.shape)
然后,对于我们讨论过的代码,我们可以看到769个实例和6个属性 -
(769, 6)
列出整个数据
您可以查看整个数据并了解其摘要 -
print(dataset.head(20))
此命令打印前20行数据,如图所示 -
Sno Pregnancies Glucose BloodPressure SkinThickness Insulin Outcome
1 6 148 72 35 0 1
2 1 85 66 29 0 0
3 8 183 64 0 0 1
4 1 89 66 23 94 0
5 0 137 40 35 168 1
6 5 116 74 0 0 0
7 3 78 50 32 88 1
8 10 115 0 0 0 0
9 2 197 70 45 543 1
10 8 125 96 0 0 1
11 4 110 92 0 0 0
12 10 168 74 0 0 1
13 10 139 80 0 0 0
14 1 189 60 23 846 1
15 5 166 72 19 175 1
16 7 100 0 0 0 1
17 0 118 84 47 230 1
18 7 107 74 0 0 1
19 1 103 30 38 83 0
查看统计摘要
您可以使用以下命令查看每个属性的统计摘要,其中包括count,unique,top和freq。
print(dataset.describe())
上面的命令为您提供以下输出,显示每个属性的统计摘要 -
Pregnancies Glucose BloodPressur SkinThckns Insulin Outcome
count 769 769 769 769 769 769
unique 18 137 48 52 187 3
top 1 100 70 0 0 0
freq 135 17 57 227 374 500
按类变量细分数据
您还可以使用此处显示的命令查看属于每个结果的实例(行)数作为绝对计数 -
print(dataset.groupby('Outcome').size())
然后你可以看到实例的结果数量 - 如图所示 -
Outcome
0 500
1 268
Outcome 1
dtype: int64
数据可视化
您可以使用两种类型的图形来显示数据,如图所示 -
单变量图来理解每个属性
多变量图可以理解属性之间的关系
单变量图
单变量图是每个变量的图。 考虑输入变量是数字的情况,我们需要创建每个输入变量的框和晶须图。 您可以使用以下代码来实现此目的。
import pandas
import matplotlib.pyplot as plt
data = 'iris_df.csv'
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = pandas.read_csv(data, names=names)
dataset.plot(kind='box', subplots=True, layout=(2,2), sharex=False, sharey=False)
plt.show()
您可以更清楚地了解输出属性的分布,如下所示 -
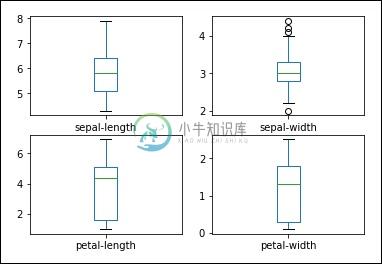
盒子和晶须图
您可以使用下面显示的命令创建每个输入变量的直方图,以了解分布情况 -
#histograms
dataset.hist()
plt().show()
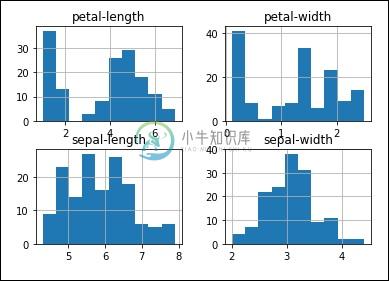
从输出中,您可以看到两个输入变量具有高斯分布。 因此,这些图有助于了解我们可以在程序中使用的算法。
多变量图
多变量图帮助我们理解变量之间的相互作用。
散点图矩阵
首先,让我们看一下所有属性对的散点图。 这有助于发现输入变量之间的结构化关系。
from pandas.plotting import scatter_matrix
scatter_matrix(dataset)
plt.show()
你可以观察输出如图所示 -
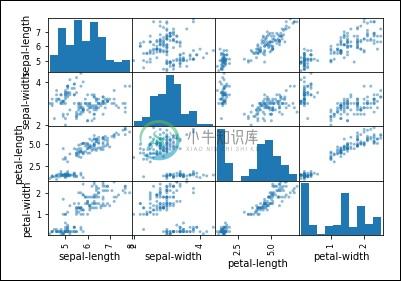
观察到在输出中存在一些属性对的对角分组。 这表明高度相关性和可预测的关系。