
Python数据可视化正态分布简单分析及实现代码

Python说来简单也简单,但是也不简单,尤其是再跟高数结合起来的时候。。。
正态分布(Normaldistribution),也称“常态分布”,又名高斯分布(Gaussiandistribution),最早由A.棣莫弗在求二项分布的渐近公式中得到。C.F.高斯在研究测量误差时从另一个角度导出了它。P.S.拉普拉斯和高斯研究了它的性质。是一个在数学、物理及工程等领域都非常重要的概率分布,在统计学的许多方面有着重大的影响力。
正态曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线。
若随机变量X服从一个数学期望为μ、方差为σ^2的正态分布,记为
N(μ,σ^2)
其概率密度函数为正态分布的期望值μ决定了其位置,其标准差σ决定了分布的幅度。当μ=0,σ=1时的正态分布是标准正态分布。其概率密度函数为:
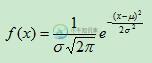
我们通常所说的标准正态分布是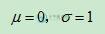 的正态分布:
的正态分布:

概率密度函数
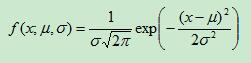
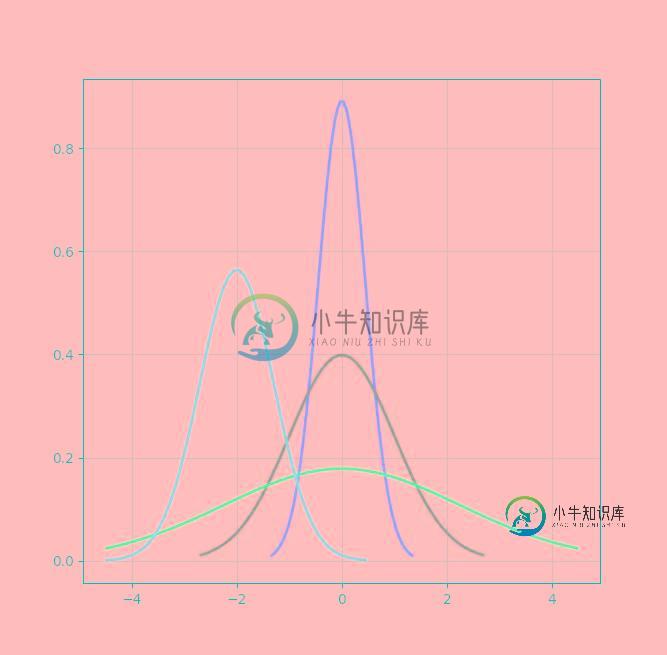
代码实现:
# Python实现正态分布 # 绘制正态分布概率密度函数 u = 0 # 均值μ u01 = -2 sig = math.sqrt(0.2) # 标准差δ sig01 = math.sqrt(1) sig02 = math.sqrt(5) sig_u01 = math.sqrt(0.5) x = np.linspace(u - 3*sig, u + 3*sig, 50) x_01 = np.linspace(u - 6 * sig, u + 6 * sig, 50) x_02 = np.linspace(u - 10 * sig, u + 10 * sig, 50) x_u01 = np.linspace(u - 10 * sig, u + 1 * sig, 50) y_sig = np.exp(-(x - u) ** 2 /(2* sig **2))/(math.sqrt(2*math.pi)*sig) y_sig01 = np.exp(-(x_01 - u) ** 2 /(2* sig01 **2))/(math.sqrt(2*math.pi)*sig01) y_sig02 = np.exp(-(x_02 - u) ** 2 / (2 * sig02 ** 2)) / (math.sqrt(2 * math.pi) * sig02) y_sig_u01 = np.exp(-(x_u01 - u01) ** 2 / (2 * sig_u01 ** 2)) / (math.sqrt(2 * math.pi) * sig_u01) plt.plot(x, y_sig, "r-", linewidth=2) plt.plot(x_01, y_sig01, "g-", linewidth=2) plt.plot(x_02, y_sig02, "b-", linewidth=2) plt.plot(x_u01, y_sig_u01, "m-", linewidth=2) # plt.plot(x, y, 'r-', x, y, 'go', linewidth=2,markersize=8) plt.grid(True) plt.show()
总结
以上就是本文关于Python数据可视化正态分布简单分析及实现代码的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他Python和算法相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
-
本文向大家介绍Java动态代理分析及简单实例,包括了Java动态代理分析及简单实例的使用技巧和注意事项,需要的朋友参考一下 Java动态代理 要想了解Java动态代理,首先要了解什么叫做代理,熟悉设计模式的朋友一定知道在Gof总结的23种设计模式中,有一种叫做代理(Proxy)的对象结构型模式,动态代理中的代理,指的就是这种设计模式。 在我看来所谓的代理模式,和23种设计模式中的“装饰模式”是
-
在处理一组数据时,您通常想做的第一件事就是了解变量的分布情况。本教程的这一章将简要介绍seaborn中用于检查单变量和双变量分布的一些工具。 您可能还需要查看[categorical.html](categorical.html #categical-tutorial)章节中的函数示例,这些函数可以轻松地比较变量在其他变量级别上的分布。 import seaborn as sns import m
-
本文向大家介绍Python数据可视化:泊松分布详解,包括了Python数据可视化:泊松分布详解的使用技巧和注意事项,需要的朋友参考一下 一个服从泊松分布的随机变量X,表示在具有比率参数(rate parameter)λ的一段固定时间间隔内,事件发生的次数。参数λ告诉你该事件发生的比率。随机变量X的平均值和方差都是λ。 代码实现: 以上这篇Python数据可视化:泊松分布详解就是小编分享给大家的全部
-
问题内容: 当我创建一个新会话并告诉可视化分析器启动 python/pycuda脚本我得到以下错误消息: 以下是我的偏好: 启动: 工作目录: 参数: 我在ubuntu10.10下使用cuda4.0。64位。分析编译的示例是有效的。 p、 我知道这个问题[如何在 Linux系统?](https://stackoverflow.com/questions/5317691/how-to-profile
-
本文向大家介绍利用python实现数据分析,包括了利用python实现数据分析的使用技巧和注意事项,需要的朋友参考一下 1:文件内容格式为json的数据如何解析 2:出现频率统计 3:重新加载module的方法py3 4:pylab中包含了哪些module from pylab import * 等效于下面的导入语句:
-
本文向大家介绍Python简单实现词云图代码及步骤解析,包括了Python简单实现词云图代码及步骤解析的使用技巧和注意事项,需要的朋友参考一下 一、安装 wordcloud 二、加载包、设置路径 三、词云图示例 1、默认参数示例 如果 jupyter 没有图形输出,需要设置 jupyter 的图形显示方式 %matplotlib inline WordCloud() 词云图对象对应的画布默认长20