
第一章 使用神经网络识别手写数字
人类视觉系统是世界上众多奇迹之一。看看下面的手写数字序列:
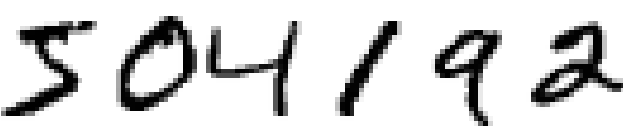
大多数人毫不费力就能够认出这些数字为 504192. 这么容易反而让人觉着迷惑了。在人类的每个脑半球中,有着一个初级视觉皮层,常称为 V1,包含 1 亿 4 千万个神经元及数百亿条神经元间的连接。但是人类视觉不是就只有 V1,还包括整个视觉皮层——V2、V3、V4 和 V5——他们逐步地进行更加复杂的图像处理。人类的头脑就是一台超级计算机,通过数十亿年的进化不断地演变,最终能够极好地适应理解视觉世界的任务。识别手写数字也不是一件简单的事。尽管人类在理解我们眼睛展示出来的信息上非常擅长,但几乎所有的过程都是无意识地。所以,我们通常并不能体会自身视觉系统解决问题的困难。
如果你尝试写出计算机程序来识别诸如上面的数字,就会明显感受到视觉模式识别的困难。看起来人类一下子就能完成的任务变得特别困难。关于我们识别形状——“9 顶上有一个圈,右下方则是一条竖线”这样的简单直觉——实际上算法上就很难轻易表达出来了。而在你试着让这些识别规则越发精准时,就会很快陷入各种混乱的异常或者特殊情形的困境中。看起来毫无希望。
神经网络以另一种方式看待这个问题。其主要思想是获取大量的手写数字,常称作训练样本,

然后开发出一个可以从这些训练样本中进行学习的系统。换言之,神经网络使用样本来自动推断出识别手写数字的规则。另外,通过增加训练样本的数量,网络可以学到更多关于手写数字的知识,这样就能够提升自身的准确性。所以,上面例子中我们只是展出了 100 个训练数字样本,而通过使用数千或者数百万或者数十亿的训练样本我们也许能够得到更好的手写数字识别器。
本章我们将实现一个可以识别手写数字的神经网络。这个程序仅仅 74 行,不适用特别的神经网络库。然而,这个短小的网络不需要人类帮助便可以超过 96% 的准确率识别数字。而且,在后面的章节,我们会发展出将准确率提升到 99% 的技术。实际上,最优的商业神经网络已经足够好到被银行和邮局分别用在账单核查和识别地址上了。
手写识别常常被当成学习神经网络的原型问题,因此我们聚焦在这个问题上。作为一个原型,它具备一个关键点:挑战性——识别手写数字并不轻松——但也不会难到需要超级复杂的解决方法,或者超大规模的计算资源。另外,这其实也是一种发展出诸如深度学习更加高级的技术的方法。所以,整本书我们都会持续地讨论手写数字识别问题。本书后面部分,我们会讨论这些想法如何用在其他计算机视觉的问题或者语音、自然语言处理和其他一些领域中。
[待续]