
卷积神经网络的深度是多少?

我正在研究CS231n卷积神经网络,用于视觉识别。在卷积神经网络中,神经元按3维排列(高度,宽度,深度)。我对CNN的深度有问题。我无法想象这是什么。
在链接中,他们说,CONV层的参数由一组可学习的过滤器组成。每个滤波器在空间上都很小(沿宽度和高度),但可以延伸到输入卷的整个深度。
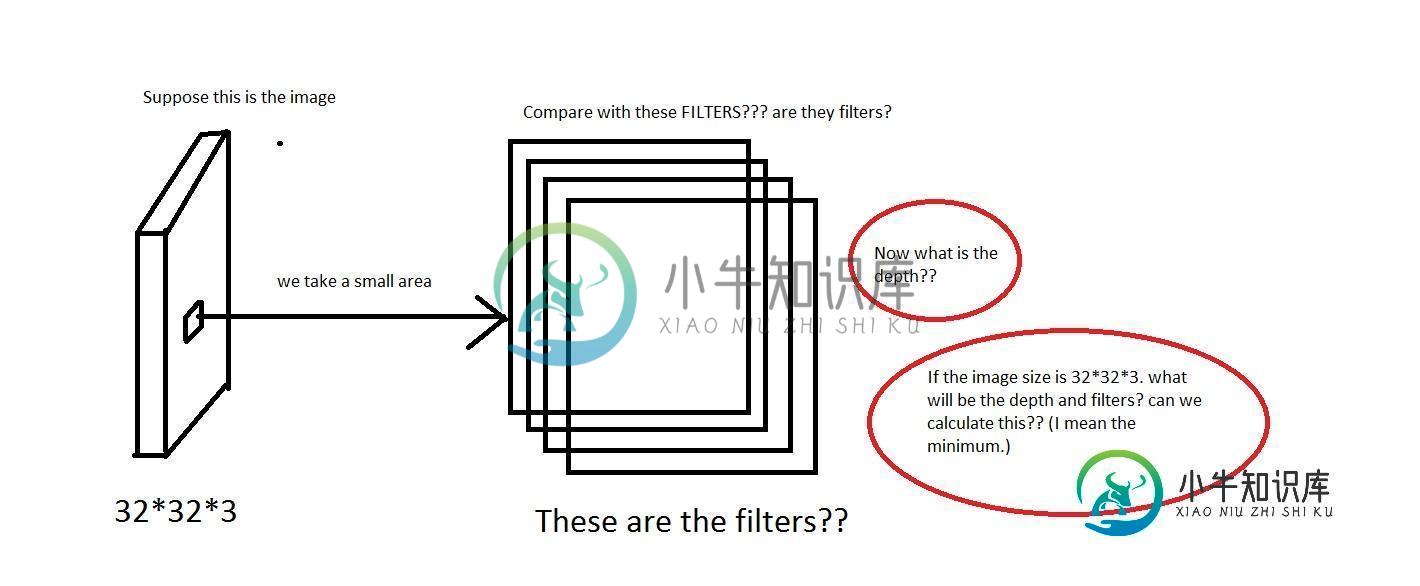
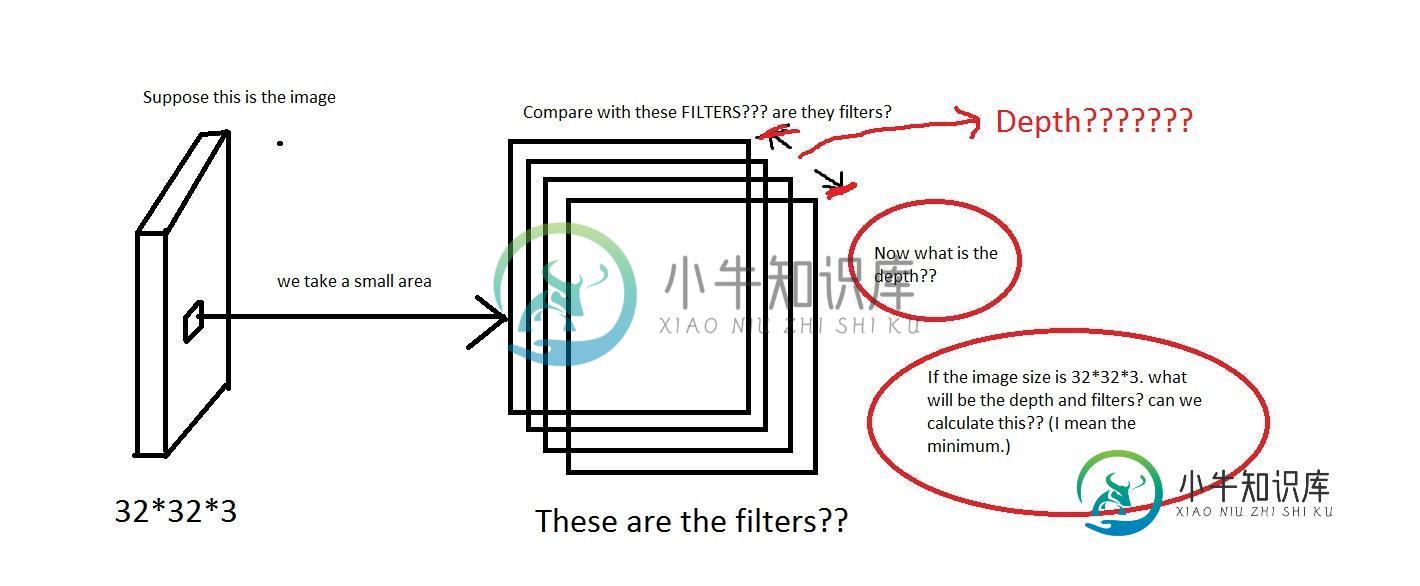
我可以理解这样的想法:我们从图像上取下一小块区域,然后将它与“滤镜”进行比较。那么滤镜会收集小图像吗?他们还说我们将每个神经元只连接到输入体积的一个局部区域。这种连通性的空间范围是一个称为神经元感受野的超参数。那么感受野的维数和滤波器的维数是一样的吗?这里的深度是多少?我们使用CNN的深度意味着什么?
编辑:所以在教程的一部分(真实世界示例部分),它说Krizhevsky等人。2012年赢得ImageNet挑战赛的架构接受了[227x227x3]大小的图像。在第一卷积层,它使用感受野大小F=11,步幅S=4,无零填充P=0的神经元。由于(227-11)/4+1=55,并且由于Conv层的深度为K=96,因此Conv层输出卷的大小为[55x55x96]。
这里我们看到深度是96。那么深度是我任意选择的东西吗?还是我计算的东西?同样在上面的例子(Krizhevsky等人)中,它们有96个深度。那么它的96个深度是什么意思呢?本教程还说明每个过滤器在空间上都很小(沿宽度和高度),但可以延伸到输入卷的整个深度。
共有1个答案

在深度神经网络中,深度指的是网络有多深,但在这种情况下,深度用于视觉识别,它转化为图像的第三维度。
在本例中,您有一个图像,该输入的大小为32x32x3,即(宽度、高度、深度)。当深度转换到训练图像的不同通道时,神经网络应该能够基于这些参数进行学习。
更新:
此外,关于过滤器深度。教程说明了这一点。
每个滤波器在空间上都很小(沿宽度和高度),但却延伸到输入卷的整个深度。
这基本上意味着滤波器是图像的一个较小的部分,它围绕图像的深度移动,以便学习图像中的规律性。
这有道理吗?
-
在LeNet提出后的将近20年里,神经网络一度被其他机器学习方法超越,如支持向量机。虽然LeNet可以在早期的小数据集上取得好的成绩,但是在更大的真实数据集上的表现并不尽如人意。一方面,神经网络计算复杂。虽然20世纪90年代也有过一些针对神经网络的加速硬件,但并没有像之后GPU那样大量普及。因此,训练一个多通道、多层和有大量参数的卷积神经网络在当年很难完成。另一方面,当年研究者还没有大量深入研究参
-
最后,我开始学习神经网络,我想知道卷积深度信念网络和卷积网络之间的区别。在这里,有一个类似的问题,但没有确切的答案。我们知道卷积深度信念网络是CNN DBN。所以,我要做一个物体识别。我想知道哪一个比另一个好得多或者它们的复杂性。我搜索了一下,但找不到任何东西,可能是做错了什么。
-
我是神经网络领域的新手,我想知道深度信念网络和卷积网络之间的区别。还有,有没有深度信念和卷积神经网络相结合的深度卷积网络? 这就是我目前所收集到的。如果我错了请纠正我。 对于图像分类问题,深度信念网络有许多层,每个层都使用贪婪的分层策略进行训练。例如,如果我的图像大小是50x50,我想要一个有4层的深度网络,即 输入层 隐藏层1(HL1) 隐藏层2(HL2) 输出层 如果使用卷积神经网络解决了同样
-
我正在学习卷积神经网络,并试图弄清楚数学计算是如何发生的。假设有一个输入图像有3个通道(RGB),所以图像的形状是28*28*3。考虑为下一层应用大小为5*5*3和步幅为1的6个过滤器。这样,我们将在下一层得到24*24*6。由于输入图像是RGB图像,每个滤波器的24*24图像如何解释为RGB图像,即每个滤波器的内部构造的图像大小为24*24*3?
-
注意: 本教程适用于对Tensorflow有丰富经验的用户,并假定用户有机器学习相关领域的专业知识和经验。 概述 对CIFAR-10 数据集的分类是机器学习中一个公开的基准测试问题,其任务是对一组大小为32x32的RGB图像进行分类,这些图像涵盖了10个类别: 飞机, 汽车, 鸟, 猫, 鹿, 狗, 青蛙, 马, 船以及卡车。 想了解更多信息请参考CIFAR-10 page,以及Alex Kriz
-
卷积神经网络(Convolutional Neural Network, CNN)是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。卷积神经网络由一个或多个卷积层和顶端的全连通层(对应经典的神经网络)组成,同时也包括关联权重和池化层(pooling layer)。这一结构使得卷积神经网络能够利用输入数据的二维结构。与其他深度学习结构相比,卷积神经网络